Компьютерное зрение использование в жизни. Как компьютерное зрение меняет рынки
Распознавание лиц в России
Где и зачем это хотят применять
Массовые мероприятия
Компания NtechLab разработала систему камер, которые . Она распознает нарушителей и отправляет их фотографии полицейским. Еще у полиции появятся ручные камеры, чтобы фотографировать подозрительных людей, распознавать их лица и узнавать по базам данных, кто они такие.
В московском метро тестируют камеры с распознаванием лиц. Они просматривают лица 20 человек в секунду и сверяют их с базами данных людей в розыске. Если есть совпадение, камеры отправляют данные полицейским. За 2,5 месяца система , которые были в розыске. Известно, что такие камеры есть , но, возможно, их установили и на других станциях.
Банк «Открытие» в начале 2017 года запустил систему распознавания лиц . Она сравнивает лицо посетителя с фотографией в базе данных. Система нужна, чтобы обслуживать клиентов быстрее, как именно - не уточняется. В будущем «Открытие» хочет использовать систему для удаленной идентификации. В 2018 году подобная система, но разработки «Ростелекома» должна появится .
Главное - алгоритм
Какая технология позволяет машинам узнавать лица
Сергей Миляев
Компьютерное зрение - это алгоритмы, позволяющие получить высокоуровневую информацию из изображений и видео, тем самым автоматизируя некоторые аспекты зрительного восприятия человека. Компьютерное зрение для машины, так же как и обычное зрение для человека, это средство измерения и получения семантической информации о наблюдаемой сцене. С его помощью машина получает информацию о том, какого размера объект, какой он формы и что из себя представляет.
Камера с алгоритмом компьютерного зрения OpenCV следит за детьми на игровой площадке
Все работает на основе нейросетей
Как именно устроено распознавание лиц, с примером
Сергей Миляев: Наиболее эффективно машины делают это на основе машинного обучения, то есть когда они принимают решение на основе некоторой параметрической модели без явного описания всех необходимых правил принятия решения программным кодом. Например, для распознавания лиц нейронная сеть извлекает признаки из изображения и получает уникальное представления о лице каждого человека, на которое не влияет ориентация его головы в пространстве, наличие или отсутствие бороды или макияжа, освещение, возрастные изменения и так далее.
Компьютерное зрение не воспроизводит зрительную систему человека, а только выполняет моделирование некоторых аспектов для решения различных задач
Сергей Миляев
Ведущий исследователь компании VisionLabs
Наиболее распространены сейчас алгоритмы компьютерного зрения на основе нейронных сетей, которые с ростом производительности процессоров и объема данных продемонстрировали высокий потенциал для решения широкого круга задач. Каждый фрагмент картинки анализируется с помощью фильтров с параметрами, которые нейросеть применяет для поиска характерных признаков изображения.
Пример
Слои нейронной сети последовательно обрабатывают изображение, причем на каждом последующем слое вычисляются все более абстрактные признаки, а фильтры на последних слоях могут видеть все изображение целиком. При распознавании лиц на первых слоях нейросеть определяет простые признаки вроде границ и черт лица, затем на более глубоких слоях фильтры могут выявлять более сложные признаки - например, два кружка рядом, скорее всего, будут означать, что это глаза и так далее.
Алгоритм компьютерного зрения OpenCV определяет, сколько пальцев ему показывают
Компьютер знает, когда его обманывают
Может ли человек обмануть очень умный компьютер, три примера
Олег Гринчук
Ведущий исследователь VisionLabs
Мошенники могут попытаться либо выдать себя за другого человека, чтобы получить доступ к его аккаунтам и данным, либо обмануть систему, чтобы она не смогла распознать их в принципе. Рассмотрим оба варианта.
Фотография, видео другого человека или распечатанная маска
С этими способами обмана платформа VisionLabs борется с помощью проверки на liveness, то есть она проверяет, что объект, находящийся перед камерой, живой. Это может быть, например, интерактивный liveness, когда система просит человека улыбнуться, моргнуть или поднести камеру или смартфон ближе к лицу.
Набор проверок невозможно предсказать, так как платформа составляет случайную последовательность с десятками тысяч комбинаций - нереально записать тысячи видеороликов с нужными комбинациями улыбок и других эмоций. А если камера оснащена сенсорами ближнего инфракрасного диапазона или сенсором глубины, то они передают системе дополнительную информацию, которая помогает по одному кадру определить, реальный ли человек перед ней.
Помимо этого, система анализирует отражение света от разных текстур, а также окружение объекта. Так что таким способом обмануть систему почти невозможно.
В этом случае мошеннику для воспроизведения достаточной для получения доступа копии нужно иметь доступ к исходному коду и на основе реакций системы на изменения внешности с макияжем постепенно менять его, чтобы стать точной копией другого человека.
Злоумышленнику необходимо взломать именно логику и принцип проверки. Но для стороннего пользователя это просто камера, черный ящик, глядя на который невозможно понять, какой именно вариант проверки внутри. Более того, от кейса к кейсу факторы для проверки отличаются, поэтому нельзя использовать для взлома какой-то универсальный алгоритм.
При нескольких ошибках распознавания система отправляет сигнал с предупреждением на сервер, после чего злоумышленнику блокируют доступ. Так что даже при маловероятном условии наличия доступа к коду взломать систему сложно, так как злоумышленник не может бесконечно менять свой облик, пока не произойдет распознавание.
Большие темные очки, кепка, шарф, закрыть лицо рукой
Система не сможет узнать человека, если большая часть его лица скрыта, даже несмотря на то, что нейросеть распознает лица гораздо лучше, чем человек. Но чтобы полностью скрыться от системы распознавания лиц, человек должен закрывать свое лицо от камер всегда, а это довольно сложно реализовать на практике.
Зрение компьютеров превосходит зрение людей
В чем именно и почему, с примером
Юрий Минкин
Системы компьютерного зрения по основным принципам работы похожи на человеческое зрение. Как у человека, у них есть устройства, которые отвечают за сбор информации, это видеокамеры, аналог глаз, и ее обработку - вычислитель, аналог мозга. Но у компьютерного зрения есть существенное преимущество над человеческим.
У человека есть определенный порог того, что он может увидеть и какую информацию извлечь из изображения. Превзойти этот порог нельзя чисто по физиологическим причинам. А алгоритмы компьютерного зрения будут только совершенствоваться. У них безграничные возможности для обучения
Юрий Минкин
Руководитель департамента Cognitive Technologies
Хороший пример - технологии компьютерного зрения в беспилотных автомобилях. Если один человек может обучить своим знаниям о дорожной ситуации лишь небольшое, значительно ограниченное количество людей, то машины весь существующий опыт детекции тех или иных объектов могут передать сразу всем новым системам, которые будут установлены на многотысячный или даже миллионный парк автомобилей.
Пример
В конце прошлого года специалисты Cognitive Technologies проводили эксперименты по сравнению возможностей человека и искусственного интеллекта в задачах детекции объектов дорожной сцены. И уже сейчас ИИ в отдельных случаях не только не уступал, но и превосходил человеческие возможности. Например, он лучше распознавал дорожные знаки, когда они были частично заслонены листвой деревьев. Компьютеры используются в суде
Может ли компьютер свидетельствовать против человека
Сергей Израйлит: Сейчас в законодательстве использование данных, «полученных от компьютеров», для использования в качестве доказательства каких-то существенных обстоятельств, в том числе правонарушений, специально урегулировано только для некоторых случаев. Например, регламентировано использование камер, распознающих номера автомобилей, нарушающих скоростной режим движения.
В общем случае такие данные можно использовать наравне с любыми другими доказательствами, которые следствие или суд может как принять во внимание, так и отклонить. При этом процессуальное законодательство устанавливает общий порядок работы с уликами - экспертиза, в рамках которой устанавливается, действительно ли представленная запись подтверждает какие-то факты или информация была тем или иным образом искажена.
Машинное зрение. Что это и как им пользоваться? Обработка изображений оптического источника
Машинное зрение - это научное направление в области искусственного интеллекта, в частности робототехники, и связанные с ним технологии получения изображений объектов реального мира, их обработки и использования полученных данных для решения разного рода прикладных задач без участия (полного или частичного) человека.

Исторические прорывы в машинном зрении
Компоненты системы машинного зрения
Машинное зрение сосредотачивается на применении, в основном промышленном, например, автономные роботы и системы визуальной проверки и измерений. Это значит, что технологии датчиков изображения и теории управления связаны с обработкой видеоданных для управления роботом и обработка полученных данных в реальном времени осуществляется программно или аппаратно.
- Одна или несколько цифровых или аналоговых камер (черно-белые или цветные) с подходящей оптикой для получения изображений
- Программное обеспечение для изготовления изображений для обработки. Для аналоговых камер это оцифровщик изображений
- Процессор (современный ПК c многоядерным процессором или встроенный процессор, например - ЦСП)
- Программное обеспечение машинного зрения, которое предоставляет инструменты для разработки отдельных приложений программного обеспечения.
- Оборудование ввода-вывода или каналы связи для доклада о полученных результатах
- Умная камера: одно устройство, которое включает в себя все вышеперечисленные пункты.
- Очень специализированные источники света (светодиоды, люминесцентные и галогенные лампы и т. д.)
- Специфичные приложения программного обеспечения для обработки изображений и обнаружения соответствующих свойств.
- Датчик для синхронизации частей обнаружения (часто оптический или магнитный датчик) для захвата и обработки изображений.
- Приводы определенной формы используемые для сортировки или отбрасывания бракованных деталей.
Обработка изображений и анализ изображений в основном сосредоточены на работе с 2D изображениями, т.е. как преобразовать одно изображение в другое. Например, попиксельные операции увеличения контрастности, операции по выделению краёв, устранению шумов или геометрические преобразования, такие как вращение изображения. Данные операции предполагают, что обработка/анализ изображения действуют независимо от содержания самих изображений.
Компьютерное зрение сосредотачивается на обработке трехмерных сцен, спроектированных на одно или несколько изображений. Например, восстановлением структуры или другой информации о 3D сцене по одному или нескольким изображениям. Компьютерное зрение часто зависит от более или менее сложных допущений относительно того, что представлено на изображениях.
Также существует область названная визуализация, которая первоначально была связана с процессом создания изображений, но иногда имела дело с обработкой и анализом. Например, рентгенография работает с анализом видеоданных медицинского применения.
Наконец, распознавание образов является областью, которая использует различные методы для получения информации из видеоданных, в основном, основанные на статистическом подходе. Значительная часть этой области посвящена практическому применению этих методов.
Таким образом, можно сделать вывод, что понятие «машинное зрение» на сегодняшний день включает в себя: компьютерное зрение, распознавание зрительных образов, анализ и обработка изображений и т.д.
Задачи машинного зрения
- Распознавание
- Идентификация
- Обнаружение
- Распознавание текста
- Восстановление 3D формы по 2D изображениям
- Оценка движения
- Восстановление сцены
- Восстановление изображений
- Выделение на изображениях структур определенного вида, сегментация изображений
- Анализ оптического потока
Распознавание

Классическая задача в компьютерном зрении, обработке изображений и машинном зрении это определение содержат ли видеоданные некоторый характерный объект, особенность или активность.
Эта задача может быть достоверно и легко решена человеком, но до сих пор не решена удовлетворительно в компьютерном зрении в общем случае: случайные объекты в случайных ситуациях.
Один или несколько предварительно заданных или изученных объектов или классов объектов могут быть распознаны (обычно вместе с их двухмерным положением на изображении или трехмерным положением в сцене).
Идентификация

Распознается индивидуальный экземпляр объекта принадлежащего к какому-либо классу.
Примеры: идентификация определённого человеческого лица или отпечатка пальцев или автомобиля.
Обнаружение

Видеоданные проверяются на наличие определенного условия.
Обнаружение, основанное на относительно простых и быстрых вычислениях иногда используется для нахождения небольших участков в анализируемом изображении, которые затем анализируются с помощью приемов, более требовательных к ресурсам, для получения правильной интерпретации.
Распознавание текста

Поиск изображений по содержанию: нахождение всех изображений в большом наборе изображений, которые имеют определенное различными путями содержание.
Оценка положения: определение положения или ориентации определенного объекта относительно камеры.
Оптическое распознавание знаков: распознавание символов на изображениях печатного или рукописного текста (обычно для перевода в текстовый формат, наиболее удобный для редактирования или индексации. Например, ASCII).

Восстановление 3D формы по 2D изображениям осуществляется с помощью стереореконструкции карты глубины, реконструкции поля нормалей и карты глубины по закраске полутонового изображения, реконструкции карты глубины по текстуре и определения формы по перемещению
Пример восстановления 3D формы по 2D изображеню

Оценка движения
Несколько задач, связанных с оценкой движения, в которых последовательность изображений (видеоданные) обрабатываются для нахождения оценки скорости каждой точки изображения или 3D сцены. Примерами таких задач являются: определение трехмерного движения камеры, слежение, то есть следование за перемещениями объекта (например, машин или людей)Восстановление сцены
Даны два или больше изображения сцены, или видеоданные. Восстановление сцены имеет задачей воссоздать трехмерную модель сцены. В простейшем случае, моделью может быть набор точек трехмерного пространства. Более сложные методы воспроизводят полную трехмерную модель.Восстановление изображений

Задача восстановления изображений это удаление шума (шум датчика, размытость движущегося объекта и т.д.).
Наиболее простым подходом к решению этой задачи являются различные типы фильтров, таких как фильтры нижних или средних частот.
Более высокий уровень удаления шумов достигается в ходе первоначального анализа видеоданных на наличие различных структур, таких как линии или границы, а затем управления процессом фильтрации на основе этих данных.
Восстановление изображений
Анализ оптического потока (нахождения перемещения пикселей между двумя изображениями).Несколько задач, связанных с оценкой движения, в которых последовательность изображений (видеоданные) обрабатываются для нахождения оценки скорости каждой точки изображения или 3D сцены.
Примерами таких задач являются: определение трехмерного движения камеры, слежение, т.е. следование за перемещениями объекта (например, машин или людей).
Методы обработки изображений
Счетчик пикселей
Подсчитывает количество светлых или темных пикселей.С помощью счетчика пикселей пользователь может выделить на экране прямоугольную область в интересующем месте, например там, где он ожидает увидеть лица проходящих людей. Камера в ответ немедленно даст сведения о количестве пикселей, представленных сторонами прямоугольника.
Счетчик пикселей дает возможность быстро проверить, соответствует ли смонтированная камера нормативным требованиям или требованиям заказчика относительно пиксельного разрешения, например, для лиц людей, входящих в двери, которые контролируются камерой, или в целях распознавания номерных знаков.
Бинаризация

Преобразует изображение в серых тонах в бинарное (белые и черные пиксели).
Значения каждого пикселя условно кодируются, как «0» и «1». Значение «0» условно называют задним планом или фоном а «1» - передним планом.
Часто при хранении цифровых бинарных изображений применяется битовая карта, где используют один бит информации для представления одного пикселя.
Также, особенно на ранних этапах развития техники, двумя возможными цветами были чёрный и белый, что не является обязательным.
Сегментация
Используется для поиска и (или) подсчета деталей.Цель сегментации заключается в упрощении и/или изменении представления изображения, чтобы его было проще и легче анализировать.
Сегментация изображений обычно используется для того, чтобы выделить объекты и границы (линии, кривые, и т. д.) на изображениях. Более точно, сегментация изображений - это процесс присвоения таких меток каждому пикселю изображения, что пиксели с одинаковыми метками имеют общие визуальные характеристики.
Результатом сегментации изображения является множество сегментов, которые вместе покрывают всё изображение, или множество контуров, выделенных из изображения. Все пиксели в сегменте похожи по некоторой характеристике или вычисленному свойству, например, по цвету, яркости или текстуре. Соседние сегменты значительно отличаются по этой характеристике.
Чтение штрих-кодов

Штрих-код - графическая информация, наносимая на поверхность, маркировку или упаковку изделий, представляющая возможность считывания её техническими средствами - последовательность чёрных и белых полос либо других геометрических фигур.
В машинном зрении штрих-коды используют для декодирования 1D и 2D кодов, разработанных для считывания или сканирования машинами.
Оптическое распознавание символов
Оптическое распознавание символов: автоматизированное чтение текста, например, серийных номеров.Распознавание используется для конвертации книг и документов в электронный вид, для автоматизации систем учёта в бизнесе или для публикации текста на веб-странице.
Оптическое распознавание текста позволяет редактировать текст, осуществлять поиск слов или фраз, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тексту электронный перевод, форматирование или преобразование в речь.
Моя программа, написанная на LabView по работе с изображениями
Использовано компьютерное зрение для неразрушающего контроля качества сверхпроводящих материалов.Введение. Решение задач обеспечения комплексной безопасности (как антитеррористической и механической безопасности объектов, так и технологической безопасности инженерных систем), в настоящее время, требует системной организации контроля, текущего состояния объектов. Одними из наиболее перспективных способов контроля текущего состояния объектов являются оптические и оптико-электронные методы, основанные на технологиях обработки видеоизображений оптического источника. К ним относятся: программы по работе с изображениями; новейшие способы обработки изображений; оборудования для получения, анализа и обработки изображений, т.е. комплекс средств и методов относящихся к области компьютерного и машинного зрения. Компьютерное зрение - это общий набор методов, позволяющих компьютерам видеть и распознавать трех- или двухмерные объекты, как инженерного направления, так и нет. Для работы с компьютерным зрение требуются цифровые или аналоговые устройства ввода-вывода, а также вычислительные сети и IP анализаторы локаций, предназначенные для контроля производственного процесса и подготовки информации для принятия оперативных решений в кратчайшие сроки.
Постановка проблемы. На сегодняшний день, главной задачей для проектируемых комплексов машинного зрения остаётся обнаружение, распознавание, идентификация и квалификация объектов потенциального риска, находящихся в случайном месте в зоне оперативной ответственности комплекса. Существующие на данный момент программные продукты, направленные на решение перечисленных задач обладают рядом существенных недостатков, а именно: значительная сложность, связанная с высокой детализацией оптических образов; высокая потребляемая мощность и достаточно узкий спектр возможностей. Расширение задач обнаружения объектов потенциального риска, до области поиска случайных объектов в случайных ситуациях, находящихся в случайном месте, имеющимися программными продуктами не возможно, даже с задействованием суперкомпьютера.
Цель. Разработка универсальной программы обработки изображений оптического источника, с возможностью потокового анализа данных, то есть программа должна быть лёгкой и быстрой для того, чтобы её можно было записать на малогабаритное ЭВМ устройство.
Задачи:
- разработка математической модели программы;
- написание программы;
- опробирование программы в условиях лабораторного эксперимента, с полной подготовкой и проведением эксперимента;
- исследование возможности применения программы в смежных областях деятельности.
Актуальность программы определяется:
- высокой стоимостью профессиональных программ обработки визуальной информации.
Анализ актуальности разработки программы.
- отсутствием на рынке программного обеспечения программ обработки изображений с выводом подробного анализа инженерных составляющих объектов;
- постоянно растущими требованиями к качеству и скорости получения визуальной информации, резко повышающими востребованность программ обработки изображений;
- существующей потребность в программах высокой производительности, надежных и простых с точки зрения пользователя;
- существует потребность программ высокой производительности и простого управления, чего добиться в наше время крайне сложно. Для примера я взял Adobe Photoshop. Данный графический редактор обладает гармоничным сочетанием функциональности и простоты использования для рядового пользователя, но в данной программе невозможно работать со сложными инструментами по обработке изображения (например, анализ изображения путём построения математической зависимости (функции) или же интегральной обработкой изображений);
- высокой стоимостью профессиональных программ обработки визуальной информации. Если программное обеспечение качественно, то цена на него крайне высока, вплоть до отдельных функции того или иного набора программ. На графике ниже представлена зависимость цены/качества простых аналогов программы.
Для упрощения решения задач данного типа, мною была разработана математическая модель и написана программа для ЭВМ устройства по анализу изображения при помощи простейших преобразований исходных изображений.
Программа работает с преобразованиями типа бинаризации, яркости, контраста изображения и т.д. Принцип действия программы продемонстрирован на примере анализа сверхпроводящих материалов.
При создании композиционных сверхпроводников на основе Nb3Sn варьируется объемное соотношение бронзы и ниобия, размер и количество волокон в нем, равномерность их распределения по сечению бронзовой матрицы, наличие диффузионных барьеров и стабилизирующих материалов. При заданной объемной доле ниобия в проводнике увеличение количества волокон приводит, соответственно, к уменьшению их диаметра. Это ведет к заметному возрастанию поверхности взаимодействия Nb / Cu-Sn, что в значительной степени ускоряет процесс нарастания сверхпроводящей фазы. Такое увеличение количества сверхпроводящей фазы при повышении числа волокон в проводнике обеспечивает возрастание критических характеристик сверхпроводника. В связи с этим необходимо наличие инструмента для контроля объемной доли сверхпроводящей фазы в конечном продукте (композиционном сверхпроводнике).
При создании программы учитывалась важность проведения исследований материалов, из которых создаётся сверхпроводящие кабели, так как при неправильном соотношении ниобия к бронзе возможен взрыв проводов, а, следовательно, людские жертвы, денежные затраты и потеря времени. Данная программа позволяет определить качество проводов на основе химическо физического анализа объекта.
Блок-диаграмма программы

Описание этапов исследования.
1 этап. Пробоподготовка: резка композиционного сверхпроводника на электроэрозионном станке; запрессовка образца в пластмассовую матрицу; полировка образца до зеркального состояния; травление образца для выделения волокон ниобия на бронзовой матрице. Получены образцы запрессованных композиционных сверхпроводниковых образцов;
2 этап. Получение изображений: получение металлографических изображений на сканирующем электронном микроскопе.
3 этап. Обработка изображений: создание инструмента для определения объемной доли сверхпроводящей фазы на металлографическом изображении; набор статистически значимых данных на конкретном типе образцов. Созданы математические модели различных инструментов по обработке изображений; создана программная разработка для оценки объемной доли сверхпроводящий фазы; программа была облегчена путём соединения нескольких математических функций в одну; было получено среднее значение объемной доли волокон ниобия в бронзовой матрице 24.7±0,1 %. Низкий процент отклонения свидетельствует о высокой повторяемости структуры композиционного провода.
Электронномикроскопическое изображения композиционных сверхпроводников

Методы обработки изображений в программе.
- Идентификация - распознается индивидуальный экземпляр объекта, принадлежащего к какому-либо классу.
- Бинаризация – процесс перевода цветного (или в градациях серого) изображения в двухцветное черно-белое.
- Сегментация - это процесс разделения цифрового изображения на несколько сегментов (множество пикселей, также называемых суперпикселями).
- Эрозия – сложный процесс, при выполнении которого структурный элемент проходит по всем пикселам изображения. Если в некоторой позиции каждый единичный пиксел структурного элемента совпадет с единичным пикселом бинарного изображения, то выполняется логическое сложение центрального пиксела структурного элемента с соответствующим пикселом выходного изображения.
- Дилатация - свертка изображения или выделенной области изображения с некоторым ядром. Ядро может иметь произвольную форму и размер. При этом в ядре выделяется единственная ведущая позиция, которая совмещается с текущим пикселем при вычислении свертки.
Формулы работы программы
Формула бинаризации (метод Оцу):

Формула эрозии:
Формула дилатации:
Схема дилатации и эрозии

Формулы сегментации порогами цвета:
Определение модуля градиента яркости для каждого пикселя изображения:
Вычисление порога: 
Использованное оборудование
Интерфейс программы

Давайте вернемся в детство, и вспомним фантастику. Ну, хотя бы Звездные войны, где есть такой желтый человекообразый робот. Он каким-то волшебным образом ходит и ориентируется в пространстве. По сути, у этого робота есть «глаза» и он «видит» окружающее пространство. Но как компьютеры могут что-либо видеть? Когда мы смотрим на что-то, мы понимаем, что мы видим, для нас зрительная информация осмысленна. Но подключив к компьютеру видеокамеры, мы получим лишь набор нулей и единиц, которые он с этой видеокамеры будет считывать. Как компьютеру «понять», что он «видит»? Для ответа на этот вопрос создана такая научная дисциплина, как Computer Vision (Компьютерное зрение). По сути, Computer Vision — это наука о том, как создать алгоритмы, которые анализируют изображения и ищут в них полезную информацию (информацию, которая необходима роботу для ориентации по данным, поступающим с видеокамеры). Задача компьютерного зрения является, по сути, задачей .
Существует несколько направлений и подходов в Computer Vision:
- Предобработка изображений.
- Сегментация.
- Выделение контуров.
- Нахождение особых точек.
- Нахождение объектов на изображении.
- Распознавание образов.
Разберем их более подробно.
Предобработка изображений. Как правило, перед тем как анализировать изображение, необходимо провести предварительную обработку, которая облегчит анализ. Например, удалить шумы, либо какие-то мелкие незначительные детали, которые мешают анализу, либо провести еще какую-либо обработку, которая облегчит анализ. В частности, для подавления шумов и мелких деталей используют фильтр размытия изображения.
Пример, зашумленное изображение:
После применения размытия по гауссу

Однако у него есть существенный недостаток: вместе с подавлением шумов размываются границы между областями изображение, а мелкие детали не исчезают, они просто превращаться в пятна. Для устранения данных недостатков используют медианную фильтрацию. Она хорошо справляется с импульсным шумом и удалением мелких деталей, причем, границы не размываются. Однако медианная фильтрация не справятся с гауссовым шумом.
Сегментация. Сегментация — это разделение изображение на области. Например, одна область — фон, другая конкретный объект. Или, например, есть у нас фотография, где морской пляж. Мы делим ее на области: море, пляж, небо. Для чего нужна сегментация? Ну например, у нас есть задача найти на изображении объект. Для ускорения мы ограничиваем область поиска определенным сегментом, если точно знаем, что объект может быть только в этой области. Или, например, в геоинформатике может быть задача сегментации спутниковых или аэро фотоснимков.
Пример. Вот у нас исходное изображение:

А вот его сегментация:

В данном случае при сегментации использовались текстурные признаки.
Выделение контуров. Для чего на изображении выделять контур? Давайте предположим, что нам надо решить задачу поиска на фотографии лица человека. Допустим, мы сначала попытались решить эту задачу «в лоб» — тупым перебором. Берем «квадратик» с изображением лица и попиксельно сравниваем его с изображением, перемещая квадратик попиксельно слева направо и так по каждой строке пикселей. Понятно, что так будет работать слишком долго, к тому-же, такой алгоритм найдет не любое лицо, а только одно конкретное. И то, если его чуть-чуть повернуть или изменить масштаб, то все, поиск перестанет работать. Другое дело, если у нас есть контур изображения и контур лица. Мы сможем линии контура описать каким-то иным способом, кроме растровой картинки, например, в виде списка координат его точек, в виде группы линий, описанных разными математическими формулами. Короче говоря, выделим контур, мы можем его векторизовать и производить уже не поиск растра среди растра, а векторного объекта среди векторных объектов. Это гораздо быстрее, кроме того, тогда описание объектов может быть инвариантным к поворотам и/или масштабу (то есть, мы можем находить объекты даже если они повернуты или масштабированы).
Теперь возникает вопрос: а как выделить контур? Как правило, сначала получают так называемый контурный препарат, чаще всего это градиент (скорость изменения яркости). То есть, получив градиент изображения, мы увидим белыми те области, где у нас резкие перепады яркости, и черными где яркость меняется плавно или вообще не меняется. Иными словами, все границы у нас будут выделены белыми полосами. Дальше эти белые полосы мы сужаем и получаем контур (если описать кратко что делает алгоритм получения контура). В настоящее время существует ряд стандартных алгоритмов выделения контура, например, алгоритм Кэнни, который реализован в библиотеке OpenCV.
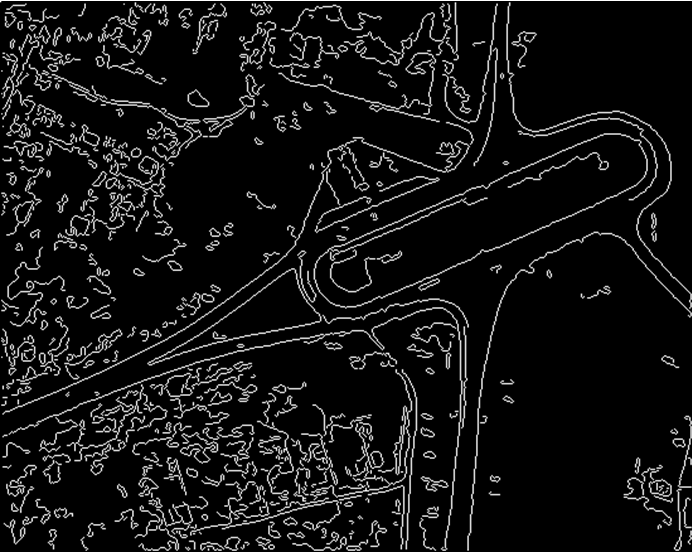
Пример выделения контуров.
Исходное изображение:

Выделенные контуры:
Нахождение особых точек. Другой метод анализа изображения — это нахождение на нем особых точек. В качестве особых точек могут быть, например, углы, экстремумы яркости, а также другие особенности изображения. С особыми точками можно делать примерно тоже, что и с контурами — описать в векторном виде. Например, можно описать взаимное расположение точек в виде расстояний между точками. При повороте объектов расстояние не меняется — значит, такое описание будет инвариантно к повороту. А чтобы сделать модель еще и инвариантной к масштабу, можно описать не расстояние, а отношения между расстояниями — действительно, если расстояние одной пары точек в два раза больше чем другой пары точек, о оно будет всегда в два раза больше, независимо от того, во сколько раз мы увеличили или уменьшили объект. В настоящее время существует много типовых алгоритмов нахождения особых точек, например, детектор Харриса, Моравеца, MSER, AKAZE и так далее. Многие из существующих алгоритмов нахождения особых точек реализованы в OpenCV.
Распознавание образов. Данный процесс происходит когда изображение проанализировано, на нем выделены контуры и преобразованы в векторный вид, либо найден особые точки и вычислено их взаимное расположение (либо и то и другое вместе). В общем, получена совокупность признаков, по которым и происходит определение, какие на картинке есть объекты. Для этого исполняться различные эвристические алгоритмы, например, . Вообще, как распознавать образы — это целая наука, называемая Теория распознавания образов.
Распознавание образов - это отнесение исходных данных к определенному классу с помощью выделения существенных признаков, характеризующих эти данные, из общей массы несущественных данных. При постановке задач распознавания стараются пользоваться математическим языком, стремясь — в отличие от теории искусственных нейронных сетей, где основой является получение результата путём эксперимента, — заменить эксперимент логическими рассуждениями и математическими доказательствами. Классическая постановка задачи распознавания образов: Дано множество объектов. Относительно них необходимо провести классификацию. Множество представлено подмножествами, которые называются классами. Заданы: информация о классах, описание всего множества и описание информации об объекте, принадлежность которого к определенному классу неизвестна. Требуется по имеющейся информации о классах и описании объекта установить — к какому классу относится этот объект.
Существует несколько подходов к распознаванию образов:
- Перечисление. Каждый класс задаётся путём прямого указания его членов. Такой подход используется в том случае, если доступна полная априорная информация о всех возможных объектах распознавания. Предъявляемые системе образы сравниваются с заданными описаниями представителей классов и относятся к тому классу, которому принадлежат наиболее сходные с ними образцы. Такой подход называют методом сравнения с эталоном. Он, к примеру, применим при распознавании машинопечатных символов определённого шрифта. Его недостатком является слабая устойчивость к шумам и искажениям в распознаваемых образах.
- Задание общих свойств . Класс задаётся указанием некоторых признаков, присущих всем его членам. Распознаваемый объект в таком случае не сравнивается напрямую с группой эталонных объектов. В его первичном описании выделяются значения определённого набора признаков, которые затем сравниваются с заданными признаками классов. Такой подход называется сопоставлением по признакам. Он экономичнее метода сравнения с эталоном в вопросе количества памяти, необходимой для хранения описаний классов. Кроме того, он допускает некоторую вариативность распознаваемых образов. Однако, главной сложностью является определение полного набора признаков, точно отличающих членов одного класса от членов всех остальных.
- Кластеризация. В случае, когда объекты описываются векторами признаков или измерений, класс можно рассматривать как кластер. Распознавание осуществляется на основе расчёта расстояния (чаще всего это евклидово расстояние) описания объекта до каждого из имеющихся кластеров. Если кластеры достаточно разнесены в пространстве, при распознавании хорошо работает метод оценки расстояний от рассматриваемого объекта до каждого из кластеров. Сложность распознавания возрастает, если кластеры перекрываются. Обычно это является следствием недостаточности исходной информации и может быть разрешено увеличением количества измерений объектов. Для задания исходных кластеров целесообразно использовать процедуру обучения.
Для того, чтобы провести процедуру распознавание образов, объекты нужно как-то описать. Существует также несколько способов описания объектов:
- Евклидово пространство — объекты представляются точками в евклидовом пространстве их вычисленных параметров, представление в виде набора измерений;
- Списки признаков — выявление качественных характеристик объекта и построение характеризующего вектора;
- Структурное описание — выявление структурных элементов объекта и определение их взаимосвязи.
Нахождение объектов на изображении. Задача нахождения объектов на изображении сводиться к тому, что нам необходимо найти заранее известный объект, например, лицо человека. Для этого данный объект мы описываем какими-либо признаками, и ищем на изображением объект, удовлетворяющий этим признакам. Эта задача похожа на задачу распознавания образов, но с тем лишь отличием, что тут надо не классифицировать неизвестный объект, а найти где на изображении находиться известный объект с заданными признаками. Часто к задаче нахождения объектов на изображениях предъявляют требования по быстродействию, так как это необходимо делать в режиме реального времени.
Классический пример подобных алгоритмов — распознавание лиц по методу Виола Джонсона. Хотя этот метод был разработан и представлен в 2001 году Полом Виолой и Майклом Джонсом, он до сих пор является основополагающим для поиска объектов на изображении в реальном времени. Основные принципы, на которых основан метод, таковы:
- Используются изображения в интегральном представлении, что позволяет вычислять быстро необходимые объекты;
- Используются признаки Хаара, с помощью которых происходит поиск нужного объекта (в данном контексте, лица и его черт);
- Используется бустинг (от англ. boost – улучшение, усиление) для выбора наиболее подходящих признаков для искомого объекта на данной части изображения;
- Все признаки поступают на вход классификатора, который даёт результат «верно» либо «ложь»;
- Используются каскады признаков для быстрого отбрасывания окон, где не найдено лицо.
Скажу пару слов об интегральном изображении. Дело в том, что в задачах компьютерного зрения часто приходиться использовать метод сканирующего окна: мы двигаем окно попиксельно по всему изображению и для каждого пикселя окна выполняем определенный алгоритм. Как я уже говорил в начале статьи, такой подход работает медленно, особенно если размер скользящего окна и изображения большой. Например, если у нас размер изображения 1000 на 1000 то это будет миллион пикселей. А если скользящее окно 10 на 10 в нем 100 пикселей и алгоритм, обрабатывающий сто пикселей надо выполнить миллион раз. При получении интегрального изображения мы пробегам по картинке 1 раз и получаем матрицу, в которой каждый пиксель — это сумма яркостей прямоугольника, ограниченного этим пикселем и началом координат. Благодаря такой матрице, мы можем вычислить всего за 4 операции может вычислить сумму яркостей любого прямоугольника (хоть 10 на 10, хоть 30 на 30, хоть 100 на 50). Как правило, во многих случаях, обработка в скользящем окне как раз сводиться к вычислению суммы яркостей.
Последние лет восемь я активно занимаюсь задачами, связанными с распознаванием образов, компьютерным зрением, машинным обучением. Получилось накопить достаточно большой багаж опыта и проектов (что-то своё, что-то в ранге штатного программиста, что-то под заказ). К тому же, с тех пор, как я написал пару статей на Хабре, со мной часто связываются читатели, просят помочь с их задачей, посоветовать что-то. Так что достаточно часто натыкаюсь на совершенно непредсказуемые применения CV алгоритмов.
Но, чёрт подери, в 90% случаев я вижу одну и ту же системную ошибку. Раз за разом. За последние лет 5 я её объяснял уже десяткам людей. Да что там, периодически и сам её совершаю…
В 99% задач компьютерного зрения то представление о задаче, которое вы сформулировали у себя в голове, а тем более тот путь решения, который вы наметили, не имеет с реальностью ничего общего. Всегда будут возникать ситуации, про которые вы даже не могли подумать. Единственный способ сформулировать задачу - набрать базу примеров и работать с ней, учитывая как идеальные, так и самые плохие ситуации. Чем шире база-тем точнее поставлена задача. Без базы говорить о задаче нельзя.
Тривиальная мысль. Но все ошибаются. Абсолютно все. В статье я приведу несколько примеров таких ситуаций. Когда задача поставлена плохо, когда хорошо. И какие подводные камни вас ждут в формировании ТЗ для систем компьютерного зрения.
Сама по себе задача, на мой взгляд, скорее решаема. Если брать отметки как опорные точки и сравнивать теми же методами, которыми сравнивают . Но, опять же, пока не протестируешь базу хотя бы на пару сотен примеров - никогда не узнаешь, можно ли работу успешно выполнить. Но почему-то такое предложение не понравилось автору статьи… Жаль!
Это два наиболее осмысленных и репрезентативных, на мой взгляд, примера. По ним можно понять, почему нужно абстрагироваться от идеи и смотреть реальные кадры.
Ещё несколько примеров, с которыми я встречался, но уже в двух словах. Во всех этих примерах у людей не было ни единой фотографии на момент, когда они начали спрашивать о реализуемости задачи:
1)
Распознавание номеров у марафонцев на футболках по видеопотоку (картинка из Яндыкса)
Хы
. Пока готовил статью натолкнулся на это . Очень хороший пример, на котором видны все потенциальные проблемы. Это и разные шрифты, это и нестабильный фон с тенями, это нерезкость и замятые углы. И самое главное. Заказчик предлагает идеализированную базу . Снятую на хороший фотоаппарат солнечным днём. Попробуйте посмотреть номера спортсменов на майках поискав поиском яндыкса.
Хы.Хы
За пару часов до публикации автор заказа внезапно вышел на меня сам с предложением взяться за работу, от которого я отказался:) Всё же это карма, добавить это в статью.
2)
Распознавание текста на фотографиях экранов телефонов
3)
И, мой любимый пример. Письмо на почту:
" нужна программа в коммерческий сектор для распознания избражений.
Алгоритм работы такой. оператор программы задает изображения предмета(-ов) в нескольких ракурсах и т.п.
потом при появленини этого или максимально похожего изображения предмета, програма совершает требуемое/заданное действие.
деталей естественно не могу пока рассказать.
" (орфография, пунктуация сохранены)
Хорошие
Но не всё так плохо! Ситуация, когда задача ставится идеально, встречается часто. Моя любимая: «Нужно ПО для автоматического подсчета лосей на фото.Пример фото с лосями высылаю.»


Оба фото кликабельны.
До сих пор жалею, что с этой задачей не срослось. Сначала кандидатскую защищал и был занят, а потом заказчик как-то энтузиазм потерял (или нашёл других исполнителей).
В постановке нет ни малейшей трактовки решения. Только две вещи: «что нужно сделать», «входные данные». Много входных данных. Всё.
Мысль - вывод
Единственный способ поставить задачу - набрать базу и определить методологию работы по этой базе. Что вы хотите получить? Какие границы применимости алгоритма? Без этого вы не только не сможете подойти к задаче, вы не сможете её сдать. Без базы данных заказчик всегда сможет сказать «У вас не работает такой-то случай. Но это же критичная ситуация! Без него я не приму работу».Как сформировать базу
Наверное, всё это был приквел к статье. Настоящая статья начинается тут. Идея того, что в любой задаче CV и ML нужна база для тестирования - очевидна. Но как набрать такую базу? На моей памяти три-четыре раза первая набранная база спускалась в унитаз. Иногда и вторая. Потому что была нерепрезентативна. В чём сложность?Нужно понимать, что «сбор базы» = «постановка задачи». Собранная база должна:
1. Отражать проблематику задачи;
2. Отражать условия, в которых будет решаться задача;
3. Формулировать задачу как таковую;
4. Приводить заказчика и исполнителя к консенсусу относительно того, что было сделано.
Время года
Пару лет назад мы с другом решили сделать систему, которая могла бы работать на мобильниках и распознавать автомобильные номера.. На тот момент мы были весьма умудрённые в CV системах. Знали, что нужно собирать такую базу, чтобы плохо было. Чтобы посмотрел на неё и сразу понял все проблемы. Мы собрали такую базу:



Сделали алгоритм, и он даже неплохо работал. Давал 80-85% распознавания выделенных номеров.
Ну да… Только летом, когда все номера стали чистые и хорошие точность системы просела процентов на 5…
Биометрия
Достаточно много в своей жизни мы работали с биометрией ( , ). И, кажется, наступили на все возможные грабли при сборе биометрических баз.База должна быть собрана в разных помещениях. Когда аппарат для сбора базы стоит только у разработчиков - рано или поздно выяснится, что он завязан на соседнюю лампу.
В биометрических базах нужно иметь 5-10 снимков для каждого человека. И эти 5-10 снимков должны быть сделаны в разные дни, в разное время дня. Подходя к биометрическому сканеру несколько раз подряд, человек сканируется одним и тем же способом. Подходя в разные дни - по-разному. Некоторые биометрические характеристики могут немножко меняться в течении суток.
База, собранная из разработчиков нерепрезентативна. Они подсознательно считываются так, чтобы всё сработало…
У вас новая модель сканера? А вы уверены, что он работает со старой базой?
Вот глаза собранные с разных сканеров. Разные поля работы, разные блики, разные тени, разные пространственные разрешения, и.т.д.






База для нейронных сетей и алгоритмов обучения
Если у вас в коде используется какой-то алгоритм обучения - пиши пропало. Вам нужно формировать базу для обучения с его учётом. Предположим, в вашей задаче распознавания имеется два сильно отличающихся шрифта. Первый встречается в 90% случаев, второй в 10%. Если вы нарежете эти два шрифта в данной пропорции и обучитесь по ним единым классификатором, то с высокой вероятностью буквы первого шрифта будут распознаваться, а буквы второго нет. Ибо нейронная сеть/SVM найдёт локальный минимум не там, где распознаётся 97% первого шрифта и 97% второго, а там где распознаётся 99% первого шрифта и 0% второго. В вашей базе должно быть достаточно примеров каждого шрифта, чтобы обучение не ушло в другой минимум.Как сформировать базу при работе с реальным заказчиком
Одна из нетривиальных проблем при сборе базы - кто это должен делать. Заказчик или исполнитель. Сначала приведу несколько печальных примеров из жизни.Я нанимаю вас, чтобы вы решили мне задачу!
Именно такую фразу я услышал однажды. И блин, не поспоришь. Но вот только базу нужно было бы собирать на заводе, куда бы нас никто не пустил. А уж тем более, не дал бы нам монтировать оборудование. Те данные, которые давал заказчик были бесполезны: объект размером в несколько пикселей, сильно зашумлённая камера с импульсными помехами, которая периодически дергается, от силы двадцать тестовых картинок. На предложения поставить более хорошую камеру, выбрать более хороший ракурс для съёмки, сделать базу хотя бы на пару сотен примеров, заказчик ответил фразой из заголовка.У нас нет времени этим заниматься!
Однажды директор весьма крупной компании (человек 100 штата + офисы во многих странах мира) предложил пообщаться. В продукте, который выпускала эта компания часть функционала была реализована очень старыми и очень простыми алгоритмами. Директор рассказал нам, что давно грезит о модификации данного функционала в современные алгоритмы. Даже нанимал две разных команды разработчиков. Но не срослось. Одна команда по его словам слишком теоретизировала, а вторая никакой теории не знала и тривиальщину делала. Мы решили попробовать.На следующий день нам выдали доступ к огромному массиву сырой информации. Сильно больше, чем я бы сумел просмотреть за год. Потратив на анализ информации пару дней мы насторожились спросили: «А что собственно вам нужно от новых алгоритмов?». Нам назвали десятка два ситуаций, когда текущие алгоритмы не работают. Но за пару дней я видел лишь одну-две указных ситуации. Просмотрев ещё пачку данных смог найти ещё одну. На вопрос: «какие ситуации беспокоят ваших клиентов в первую очередь?», - ни директор ни его главные инженеры не смогли дать ответа. У них не было такой статистики.
Мы исследовали вопрос и предложили алгоритм решения, который мог автоматически собрать все возможные ситуации. Но нам нужно было помочь с двумя вещами. Во-первых, развернуть обработку информации на серверах самой фирмы (у нас не было ни достаточной вычислительной мощности, ни достаточного канала к тому месту, где хранились сырые данные). На это бы ушла неделя работы администратора фирмы. А во-вторых, представитель фирмы должен был классифицировать собранную информацию по важности и по тому как её нужно обрабатывать (это ещё дня три). К этому моменту мы уже потратили две-три недели своего времени на анализ данных, изучение статей по тематике и написание программ для сбора информации (никакого договора подписано на этот момент не было, всё делали на добровольных началах).
На что нам было заявлено: «Мы не можем отвлекать на эту задачу никого. Разбирайтесь сами». На чём мы откланялись и удалились.
Заказчик даёт базу
Был и другой случай. На этот раз заказчик поменьше. А система, которой занимается заказчик разбросана по всей территории страны. Зато заказчик понимает, что мы базу не соберём. И из всех сил старается собрать базу. Собирает. Очень большую и разнообразную. И даже уверяет, что база репрезентативна. Начинаем работать. Почти доделываем алгоритм. Перед сдачей выясняется, что на собранной базе-то алгоритм работает. И условиям договора мы удовлетворяем. Но вот база-то была нерепрезентативной. В ней нет 2/3 ситуаций. А те ситуации, что есть - представлены непропорционально. И на реальных данных система работает сильно хуже.Вот и получается. Мы старались. Всё что обещали - сделали, хотя задача оказалась сильно сложнее, чем планировали. Заказчик старался. Потратил много времени на сбор базы.
Но итоговый результат - хреновый. Пришлось что-то придумывать на ходу, хоть как-то затыкать дырки…
Так кто должен сформировать базу?
Проблема в том, что очень часто задачи компьютерного зрения возникают в сложных системах. Системах, которые делались десятки лет многими людьми. И разобраться в такой системе часто сильно дольше, чем решить саму задачу. А заказчик хочет чтобы разработка началась уже завтра. И естественно, предложение заплатить за подготовку ТЗ и базы сумму в 2 раза больше стоимости задачи, увеличить сроки в 3 раза, дать допуск к своим системам и алгоритмам, выделить сотрудника, который всё покажет и расскажет, вызывает у него недоумение.На мой взгляд решение любой задачи компьютерного зрения требует постоянного диалога между заказчиком и исполнителем, а так же желания заказчика сформулировать задачу. Исполнитель не видит всех нюансов бизнеса заказчика, не знает систему изнутри. Я ни разу не видел чтобы подход: «вот вам деньги, завтра сделайте мне решение» сработал. Решение-то было. Но работало ли оно как нужно?
Сам я как огня пытаюсь шарахаться от таких контрактов. Работаю ли я сам, или в какой-то фирме, которая взяла заказ на разработку.
В целом ситуацию можно представить так: предположим, вы хотите устроить свою свадьбу. Вы можете:
Продумать и организовать всё самому от начала до конца. По сути данный вариант - «решать задачу самому».
Продумать всё от начала до конца. Написать все сценарии. И нанять исполнителей для каждой роли. Тамаду для того чтобы гости не скучали, ресторан, чтобы все приготовили и провели. Написать основную канву для тамады, меню для ресторана. Этот вариант - это диалог. Обеспечить данными исполнителя, расписать всё, что требуется.
Можно продумать большими блоками, не вникая в детали. Нанять тамаду, пусть делает, что делает. Не согласовывать меню ресторана. Заказать модельеру подбор платья, причёски, имиджа. Головной боли минимум, но когда начнутся конкурсы на раздевание, то можно понять что что-то было сделано не так. Далеко не факт, что сформулировав задачу в стиле «распознайте мне символ» исполнитель и заказчик поймут одно и то же.
А можно всё заказать свадебному агентству. Дорого, думать совсем не надо. Но вот, что получится - уже не знает никто. Вариант - «сделайте мне хорошо». Скорее всего, качество будет зависеть от стоимости. Но не обязательно
Есть ли задачи, где база не нужна
Есть. Во-первых, в задачах, где база - это слишком сложно. Например, разработка робота, который анализирует видео, и по нему принимает решения. Нужен какой-то тестовый стенд. Можно сделать базы на какие-то отдельные функции. Но сделать базу по полному циклу действий зачастую нельзя. Во-вторых, когда идёт исследовательская работа. Например, идёт разработка не только алгоритмов, но и устройства, которым будет набираться база. Каждый день новое устройство, новые параметры. Когда алгоритм меняется по три раза в день. В таких условиях база бесполезна. Можно создавать какие-то локальные базы, изменяющиеся каждый день. Но что-то глобальное неосмысленно.В-третьих, это задачи, где можно сделать модель. Моделирование это вообще очень большая и сложная тема. Если возможно сделать хорошую модель задёшево, то конечно нужно её делать. Хотите распознать текст, где есть только один шрифт - проще всего создать алгоритм моделирования (
Как научить компьютер понимать, что изображено на картинке или фотографии? Нам это кажется просто, но для компьютера это всего лишь матрица, состоящая из нулей и единиц, из которой нужно извлечь важную информацию.
Что такое компьютерное зрение? Это способность компьютера «видеть»
Зрение — это важный источник информации для человека, с помощью него мы получаем, по разным данным, от 70 до 90% всей информации. И, естественно, если мы хотим создать умную машину, нам необходимо реализовать те же навыки и в компьютере.
Задача компьютерного зрения может быть сформулирована достаточно нечетко. Что такое «видеть»? Это понимать, что где расположено, просто глядя. В этом и заключены различия компьютерного зрения и зрения человека. Зрение для нас - это о мире, а также источник метрической информации - то есть способность понимать расстояния и размеры.
Семантическое ядро изображения
Глядя на изображение, мы можем охарактеризовать его по ряду признаков, так сказать, извлечь семантическую информацию.

Например, глядя на эту фотографию, мы можем сказать, что это вне помещения. Что это город, уличное движение. Что здесь есть автомобили. По конфигурации здания и по иероглифам мы можем догадаться, что это Юго-Восточная Азия. По портрету Мао Цзэдуна понимаем, что это Пекин, а если кто видел видеотрансляции или сам там побывал, сможет догадаться, что это знаменитая площадь Тяньаньмэнь.
Что мы можем ещё сказать о картинке, рассматривая её? Можем выделить объекты на изображении, сказать, вот там люди, здесь ближе - ограда. Вот зонтики, вот здание, вот плакаты. Это примеры классов очень важных объектов, поиском которых занимаются на данный момент.
Ещё мы можем извлечь некоторые признаки или атрибуты объектов. Например, здесь мы можем определить, что это не портрет какого-то рядового китайца, а именно Мао Цзэдуна.
По автомобилю можно определить, что это движущийся объект, и он жесткий, то есть во время движения не деформируется. Про флаги можно сказать, что это объекты, они также двигаются, но они не жесткие, постоянно деформируются. А также в сцене присутствует ветер, это можно определить по развивающемуся флагу, и даже можно определить направление ветра, например, он дует слева направо.
Значение расстояний и длин в компьютерном зрении
Очень важной является метрическая информация в науке про компьютерное зрение.Это всевозможные расстояния. Например, для марсохода это особенно важно, потому что команды с Земли идут порядка 20 минут и ответ столько же. Соответственно, связь туда-обратно - 40 минут. И если мы будем составлять план движения по командам Земли, то нужно это учитывать.

Удачно технологии компьютерного зрения интегрированы в видеоиграх. По видео можно построить трёхмерные модели объектов, людей, а по пользовательским фотографиям можно восстановить трёхмерные модели городов. А затем гулять по ним.
Компьютерное зрение- это достаточно широкая область. Она тесно переплетается с разными другими науками. Частично компьютерное зрениезахватывает область и иногда выделяет область машинного зрения, исторически так сложилось.
Анализ, распознавание образов - путь к созданию высшего разума
Разберем эти понятия отдельно.

Обработка изображений - это область алгоритмов, в которых на входе и на выходе - изображение, и мы уже с ним что-то делаем.
Анализ изображения - это область компьютерного зрения, которое фокусируется на работе с двухмерным изображением и делает из этого выводы.
Распознавание образов - это абстрактная математическая дисциплина, которая распознаёт данные в виде векторов. То есть на входе - вектор и нам что-то с ним нужно делать. Откуда этот вектор, нам не так уж принципиально знать.
Компьютерное зрение - это изначально было восстановление структуры из двухмерных изображений. Сейчас эта область стала более широкой и её можно трактовать вообще как принятие решений о физических объектах, основываясь на изображении. То есть искусственного интеллекта.
Параллельно с компьютерным зрением совершенно в другой области, в геодезии, развивалась фотограмметрия — это измерение расстояний между объектами по двухмерным изображениям.
Роботы могут «видеть»
И последнее - это машинное зрение. Под машинным зрением подразумевается зрение роботов. То есть решение некоторых производственных задач. Можно сказать, что компьютерное зрение - это одна большая наука. Она объединяет в себе некоторые другие науки частично. А когда компьютерное зрение получает какое-то конкретное приложение, то оно превращается в машинное зрение.

Область компьютерного зрения имеет массу практических применений. Оно связано с автоматизацией производства. На предприятиях эффективнее становится заменять ручной труд машинным. Машина не устаёт, не спит, у неё ненормированный рабочий график, она готова работать 365 дней в году. А значит, используя машинный труд, мы можем получить гарантированный результат в определённое время, и это достаточно интересно. Все задачи для систем компьютерного зрения имеют наглядное применение. И нет ничего лучше, чем увидеть результат сразу по картинке, только на стадии расчётов.
На пороге в мир искусственного интеллекта
Плюс области - это сложно! Существенная часть мозга отвечает за зрение и считается, что если научить компьютер «видеть», то есть в полной мере применить компьютерное зрение, то это одна из полных задач искусственного интеллекта. Если мы сможем решить проблему на уровне человека, скорее всего, одновременно мы решим задачу ИИ. Что очень хорошо! Или не очень хорошо, если смотреть «Терминатор 2».
Почему зрение — это сложно? Потому что изображение одних и тех же объектов может сильно разниться в зависимости от внешних факторов. В зависимости от точек наблюдения объекты выглядят по-разному.
К примеру, одна и та же фигура, снятая с разных ракурсов. И что самое интересное, у фигуры может быть один глаз, два глаза или полтора. А в зависимости от контекста (если это фото человека в футболке с нарисованными глазами), то глаз может быть и больше двух.
Компьютер ещё не понимает, но уже «видит»
Ещё один фактор, создающий сложности - это освещение. Одна и та же сцена с разным освещением будет выглядеть по-разному. Размер объектов может варьироваться. Причем объектов любых классов. Ну как можно сказать о человеке, что его рост 2 метра? Никак. Рост человека может составлять и 2.3 м, и 80 см. Как и объектов других типов, тем не менее это объекты одного и того же класса.

Особенно живые объекты претерпевают самые разнообразные деформации. Волосы людей, спортсмены, животные. Посмотрите снимки бегущих лошадей, определить, что происходит с их гривой и хвостом просто невозможно. А перекрытие объектов на изображении? Если подсунуть такую картинку компьютеру, то даже самая мощная машина затруднится выдать правильное решение.

Следующий вид — это маскировка. Некоторые объекты, животные маскируются под окружающую среду, причем достаточно умело. И пятна такие же и расцветка. Но тем не менее мы их видим, хотя не всегда издалека.
Ещё одна проблема - это движение. Объекты в движении претерпевают невообразимые деформации.
Многие объекты очень изменчивы. Вот, к примеру, на двух фото ниже объекты типа "кресло".

И на этом можно сидеть. Но научить машину, что такие разные вещи по форме, цвету, материалу все являются объектом "кресло" - очень сложно. В этом и состоит задача. Интегрировать методы компьютерного зрения - это научить машину понимать, анализировать, предполагать.

Интеграция компьютерного зрения в различные платформы
В массы компьютерное зрение начало проникать ещё в 2001 году, когда создали первые детекторы лиц. Сделали это два автора: Viola, Jones. Это был первый быстрый и достаточно надёжный алгоритм, который продемонстрировал мощь методов машинного обучения.
Сейчас у компьютерного зрения есть достаточно новое практическое применение - распознавание человека по лицу.

Но распознавать человека, как показывают в фильмах - в произвольных ракурсах, с разными условиями освещения - невозможно. Но решить задачу, один это или разные люди с разным освещением или в разной позе, похожие, как на фотографии в паспорте, можно с высокой степенью уверенности.
Требования к паспортным фотографиям во многом обусловлены особенностью алгоритмов распознавания по лицу.
К примеру, если у вас есть биометрический паспорт, то в некоторых современных аэропортах вы можете воспользоваться автоматической системой паспортного контроля.
компьютерного зрения - это способность распознавать произвольный текст
Возможно, кто-то пользовался системой распознавания текста. Одна из таких - это Fine Reader, очень популярная в Рунете система. Есть много форм, где нужно заполнять данные, они прекрасно сканируются, информация распознаётся системой очень хорошо. А вот с произвольным текстом на изображении дело обстоит гораздо хуже. Эта задача пока остаётся нерешенной.
Игры с участием компьютерного зрения, захват движения
Отдельная большая область — это создание трёхмерных моделей и захват движения (который довольно успешно реализован в компьютерных играх). Первая программа, компьютерное зрение использующая, — система взаимодействия с компьютером при помощи жестов. При ее создании было много чего открыто.
Сам алгоритм устроен довольно просто, но для его настройки потребовалось создать генератор искусственных изображений людей, чтобы получить миллион картинок. Суперкомпьютер с их помощью подобрал параметры алгоритма, по которым он теперь работает наилучшим образом.
Вот так миллион изображений и неделя счётного времени суперкомпьютера позволили создать алгоритм, который потребляет 12% мощности одного процессора и позволяет воспринимать позу человека в реальном времени. Это система Microsoft Kinect (2010 год).

Поиск изображений по содержанию позволяет загружать фотографию в систему, и по результатам она выдаст все снимки с таким же содержанием и сделанные с того же ракурса.
Примеры компьютерного зрения: трёхмерные и двухмерные карты сейчас делаются с его помощью. Карты для навигаторов автомобилей регулярно обновляются по данным с видеорегистраторов.
Существует база с миллиардами фотографий с геометками. Загружая снимок в эту базу, можно определить, где он был сделан и даже с какого ракурса. Естественно, при условии, что место достаточно популярное, что в своё время там побывали туристы и сделали ряд фотографий местности.
Роботы повсюду
Робототехника в нынешнее время повсюду, без неё никак. Сейчас существуют автомобили, в которых есть специальные камеры, распознающие пешеходов и дорожные знаки, чтобы передавать команды водителю (такая в некотором смысле компьютерная программа для зрения, помогающая автолюбителю). И есть полностью автоматизированные роботы-автомобили, но они не могут полагаться только на систему видеокамер без использования большого количества дополнительной информации.
Современный фотоаппарат — это аналог камеры-обскура
Поговорим про цифровое изображение. Современные цифровые камеры устроены по принципу камеры-обскуры. Только вместо отверстия, через которое проникает луч света и проецирует на задней стенке камеры контур предмета, у нас имеется специальная оптическая система под названием объектив. Задачей ее является собрать большой пучок света и преобразовать его таким образом, чтобы все лучи проходили через одну виртуальную точку с целью получить проекцию и сформировать изображение на плёнке или матрице.

Современные цифровые фотоаппараты (матрица) состоят из отдельных элементов - пикселей. Каждый пиксель позволяет измерять энергию света, который падает на этот пиксель суммарно, и на выходе выдавать одно число. Поэтому в цифровой камере мы получаем вместо изображения набор измерений яркости света, попавшего в отдельный пиксель — компьютерные Поэтому при увеличении изображения мы видим не плавные линии и четкие контуры, а сетку из окрашенных в различные тона квадратиков - пикселей.
Ниже вы видите первое цифровое изображение в мире.

Но что на этом изображении отсутствует? Цвет. А что такое цвет?
Психологическое восприятие цвета
Цвет - это то, что мы видим. Цвет объекта, одного и того же предмета для человека и кошки будет разным. Так как у нас (у людей) и у животных оптическая система - зрение, отличается. Поэтому цвет - это психологическое свойство нашего зрения, возникающее при наблюдении объектов и света. А не физическое свойство объекта и света. Цвет - это результат взаимодействия компонентов света, сцены и нашей зрительной системы.

Программирование компьютерного зрения на Python с помощью библиотек
Если вы решили всерьёз заняться изучением компьютерного зрения, стоит сразу приготовиться к ряду трудностей, наука эта не самая лёгкая и прячет в себе ряд подводных камней. Но "Программирование компьютерного зрения на Python" в авторстве Яна Эрика Солема - это книга, в которой все излагается максимально простым языком. Здесь вы познакомитесь с методами распознавания различных объектов в 3D, научитесь работать со стереоизображениями, виртуальной реальностью и многими другими приложениями компьютерного зрения. В книге достаточно примеров на языке Python. Но пояснения представлены, так сказать, обобщённо, дабы не перегрузить слишком научной и тяжелой информацией. Труд подойдёт студентам, просто любителям и энтузиастам. Скачать эту книгу и другие про компьютерное зрение (pdf-формата) можно в сети.
На данный момент существуют открытая библиотека алгоритмов компьютерного зрения, а также обработки изображений и численных алгоритмов OpenCV. Это реализовано на большинстве современных языков программирования, имеет открытый исходный код. Если говорить про компьютерное зрение, Python использующее в качестве языка программирования, то это также имеет поддержку данной библиотеки, кроме того, она постоянно развивается и имеет большое сообщество.
Компания "Майкрософт" предоставляет свои Api-сервисы, способные обучить нейросети для работы именно с изображениями лиц. Есть возможность применять также компьютерное зрение, Python использующее в качестве языка программирования.
 Удалить помеченные на удаление файлы в 1с
Удалить помеченные на удаление файлы в 1с Прикольные картинки на аву пацану
Прикольные картинки на аву пацану 1с склад создание конфигурации с нуля
1с склад создание конфигурации с нуля