Технология DLP. DLP — что это значит? Актуализировать правила безопасности с определенной периодичностью
28.01.2014 Сергей Кораблев
Выбор любого продукта корпоративного уровня является для технических специалистов и сотрудников, принимающих решения, задачей нетривиальной. Выбор системы предотвращения утечек данных Data Leak Protection (DLP) – еще сложнее. Отсутствие единой понятийной системы, регулярных независимых сравнительных исследований и сложность самих продуктов вынуждают потребителей заказывать у производителей пилотные проекты и самостоятельно проводить многочисленные тестирования, определяя круг собственных потребностей и соотнося их с возможностями проверяемых систем
Подобный поход, безусловно, правильный. Взвешенное, а в некоторых случаях даже выстраданное решение упрощает дальнейшее внедрение и позволяет избежать разочарования при эксплуатации конкретного продукта. Однако процесс принятия решений в данном случае может затягиваться если не на годы, то на многие месяцы. Кроме того, постоянное расширение рынка, появление новых решений и производителей еще более усложняют задачу не только выбора продукта для внедрения, но и создание предварительного шорт-листа подходящих DLP-систем. В таких условиях актуальные обзоры DLP-систем имеют несомненную практическую ценность для технических специалистов. Стоит ли включать конкретное решение в список для тестирования или оно будет слишком сложным для внедрения в небольшой организации? Может ли решение быть масштабировано на компанию из 10 тыс. сотрудников? Сможет ли DLP-система контролировать важные для бизнеса CAD-файлы? Открытое сравнение не заменит тщательного тестирования, но поможет ответить на базовые вопросы, возникающие на начальном этапе работ по выбору DLP.
Участники
В качестве участников были выбраны наиболее популярные (по версии аналитического центра Anti-Malware.ru на середину 2013 года) на российском рынке информационной безопасности DLP-системы компаний InfoWatch, McAfee, Symantec, Websense, Zecurion и «Инфосистем Джет».
Для анализа использовались коммерчески доступные на момент подготовки обзора версии DLP-систем, а также документация и открытые обзоры продуктов.
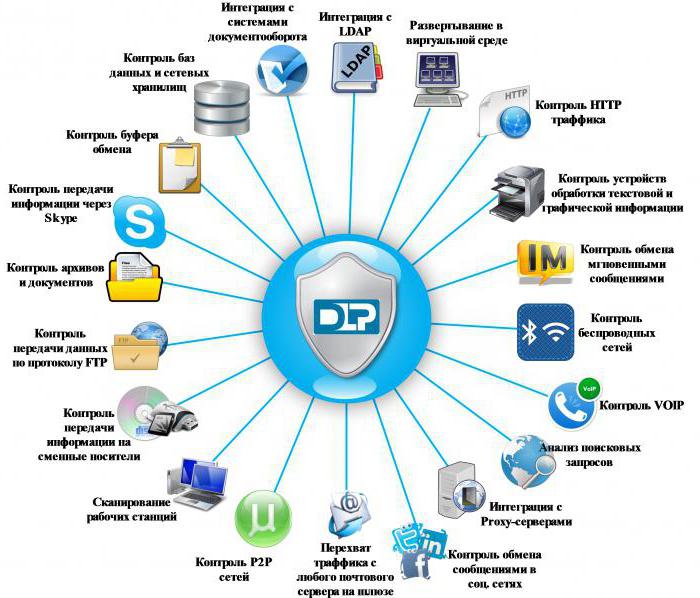
Критерии сравнения DLP-систем выбирались, исходя из потребностей компаний различного размера и разных отраслей. Под основной задачей DLP-систем подразумевается предотвращение утечек конфиденциальной информации по различным каналам.
Примеры продуктов этих компаний представлены на рисунках 1–6.
.jpg) |
| Рисунок 3. Продукт компании Symantec |
.jpg) |
| Рисунок 4. Продукт компании InfoWatch |
.jpg) |
| Рисунок 5. Продукт компании Websense |
.jpg) |
| Рисунок 6. Продукт компании McAfee |
Режимы работы
Два основных режима работы DLP-систем – активный и пассивный. Активный – обычно основной режим работы, при котором происходит блокировка действий, нарушающих политики безопасности, например отправка конфиденциальной информации на внешний почтовый ящик. Пассивный режим чаще всего используется на этапе настройки системы для проверки и корректировки настроек, когда высока доля ложных срабатываний. В этом случае нарушения политик фиксируются, но ограничения на перемещение информации не налагаются (таблица 1).
.jpg) |
В данном аспекте все рассматриваемые системы оказались равнозначны. Каждая из DLP умеет работать как в активном, так и в пассивном режимах, что дает заказчику определенную свободу. Не все компании готовы начать эксплуатацию DLP сразу в режиме блокировки – это чревато нарушением бизнес-процессов, недовольством со стороны сотрудников контролируемых отделов и претензиями (в том числе обоснованными) со стороны руководства.
Технологии
Технологии детектирования позволяют классифицировать информацию, которая передается по электронным каналам и выявлять конфиденциальные сведения. На сегодня существует несколько базовых технологий и их разновидностей, сходных по сути, но различных по реализации. Каждая из технологий имеет как преимущества, так и недостатки. Кроме того, разные типы технологий подходят для анализа информации различных классов. Поэтому производители DLP-решений стараются интегрировать в свои продукты максимальное количество технологий (см. таблицу 2).
В целом, продукты предоставляют большое количество технологий, позволяющих при должной настройке обеспечить высокий процент распознавания конфиденциальной информации. DLP McAfee, Symantec и Websense довольно слабо адаптированы для российского рынка и не могут предложить пользователям поддержку «языковых» технологий – морфологии, анализа транслита и замаскированного текста.
Контролируемые каналы
Каждый канал передачи данных – это потенциальный канал утечек. Даже один открытый канал может свести на нет все усилия службы информационной безопасности, контролирующей информационные потоки. Именно поэтому так важно блокировать неиспользуемые сотрудниками для работы каналы, а оставшиеся контролировать с помощью систем предотвращения утечек.
Несмотря на то, что лучшие современные DLP-системы способны контролировать большое количество сетевых каналов (см. таблицу 3), ненужные каналы целесообразно блокировать. К примеру, если сотрудник работает на компьютере только с внутренней базой данных, имеет смысл вообще отключить ему доступ в Интернет.
Аналогичные выводы справедливы и для локальных каналов утечки. Правда, в этом случае бывает сложнее заблокировать отдельные каналы, поскольку порты часто используются и для подключения периферии, устройств ввода-вывода и т. д.
Особую роль для предотвращения утечек через локальные порты, мобильные накопители и устройства играет шифрование. Средства шифрования достаточно просты в эксплуатации, их использование может быть прозрачным для пользователя. Но в то же время шифрование позволяет исключить целый класс утечек, связанных с несанкционированным доступом к информации и утерей мобильных накопителей.
Ситуация с контролем локальных агентов в целом хуже, чем с сетевыми каналами (см. таблицу 4). Успешно контролируются всеми продуктами только USB-устройства и локальные принтеры. Также, несмотря на отмеченную выше важность шифрования, такая возможность присутствует только в отдельных продуктах, а функция принудительного шифрования на основе контентного анализа присутствует только в Zecurion DLP.
Для предотвращения утечек важно не только распознавание конфиденциальных данных в процессе передачи, но и ограничение распространения информации в корпоративной среде. Для этого в состав DLP-систем производители включают инструменты, способные выявлять и классифицировать информацию, хранящуюся на серверах и рабочих станциях в сети (см. таблицу 5). Данные, которые нарушают политики информационной безопасности, должны быть удалены или перемещены в безопасное хранилище.
Для выявления конфиденциальной информации на узлах корпоративной сети используются те же самые технологии, что и для контроля утечек по электронным каналам. Главное отличие – архитектурное. Если для предотвращения утечки анализируется сетевой трафик или файловые операции, то для обнаружения несанкционированных копий конфиденциальных данных исследуется хранимая информация – содержимое рабочих станций и серверов сети.
Из рассматриваемых DLP-систем только InfoWatch и «Дозор-Джет» игнорируют использование средств выявления мест хранения информации. Это не является критичной функцией для предотвращения утечки по электронным каналам, но существенно ограничивает возможности DLP-систем в отношении проактивного предотвращения утечек. К примеру, когда конфиденциальный документ находится в пределах корпоративной сети, это не является утечкой информации. Однако если место хранения этого документа не регламентировано, если о местонахождении этого документа не знают владельцы информации и офицеры безопасности, это может привести к утечке. Возможен несанкционированный доступ к информации или к документу не будут применены соответствующие правила безопасности.
Удобство управления
Такие характеристики как удобство использования и управления могут быть не менее важными, чем технические возможности решений. Ведь действительно сложный продукт будет трудно внедрить, проект отнимет больше времени, сил и, соответственно, финансов. Уже внедренная DLP-система требует к себе внимания со стороны технических специалистов. Без должного обслуживания, регулярного аудита и корректировки настроек качество распознавания конфиденциальной информации будет со временем сильно падать.
Интерфейс управления на родном для сотрудника службы безопасности языке – первый шаг для упрощения работы с DLP-системой. Он позволит не только облегчить понимание, за что отвечает та или иная настройка, но и значительно ускорит процесс конфигурирования большого количества параметров, которые необходимо настроить для корректной работы системы. Английский язык может быть полезен даже для русскоговорящих администраторов для однозначной трактовки специфических технических понятий (см. таблицу 6).
Большинство решений предусматривают вполне удобное управление из единой (для всех компонентов) консоли c веб-интерфейсом (см. таблицу 7). Исключение составляют российские InfoWatch (отсутствует единая консоль) и Zecurion (нет веб-интерфейса). При этом оба производителя уже анонсировали появление веб-консоли в своих будущих продуктах. Отсутствие же единой консоли у InfoWatch обусловлено различной технологической основой продуктов. Разработка собственного агентского решения была на несколько лет прекращена, а нынешний EndPoint Security является преемником продукта EgoSecure (ранее известного как cynapspro) стороннего разработчика, приобретенного компанией в 2012 году.
Еще один момент, который можно отнести к недостаткам решения InfoWatch, состоит в том, что для настройки и управления флагманским DLP-продуктом InfoWatch TrafficMonitor необходимо знание специального скриптового языка LUA, что усложняет эксплуатацию системы. Тем не менее, для большинства технических специалистов перспектива повышения собственного профессионального уровня и изучение дополнительного, пусть и не слишком ходового языка должна быть воспринята позитивно.
Разделение ролей администратора системы необходимо для минимизации рисков предотвращения появления суперпользователя с неограниченными правами и других махинаций с использованием DLP.
Журналирование и отчеты
Архив DLP – это база данных, в которой аккумулируются и хранятся события и объекты (файлы, письма, http-запросы и т. д.), фиксируемые датчиками системы в процессе ее работы. Собранная в базе информация может применяться для различных целей, в том числе для анализа действий пользователей, для сохранения копий критически важных документов, в качестве основы для расследования инцидентов ИБ. Кроме того, база всех событий чрезвычайно полезна на этапе внедрения DLP-системы, поскольку помогает проанализировать поведение компонентов DLP-системы (к примеру, выяснить, почему блокируются те или иные операции) и осуществить корректировку настроек безопасности (см. таблицу 8).
.jpg) |
В данном случае мы видим принципиальное архитектурное различие между российскими и западными DLP. Последние вообще не ведут архив. В этом случае сама DLP становится более простой для обслуживания (отсутствует необходимость вести, хранить, резервировать и изучать огромный массив данных), но никак не для эксплуатации. Ведь архив событий помогает настраивать систему. Архив помогает понять, почему произошла блокировка передачи информации, проверить, сработало ли правило корректно, внести в настройки системы необходимые исправления. Также следует заметить, что DLP-системы нуждаются не только в первичной настройке при внедрении, но и в регулярном «тюнинге» в процессе эксплуатации. Система, которая не поддерживается должным образом, не доводится техническими специалистами, будет много терять в качестве распознавания информации. В результате возрастет и количество инцидентов, и количество ложных срабатываний.
Отчетность – немаловажная часть любой деятельности. Информационная безопасность – не исключение. Отчеты в DLP-системах выполняют сразу несколько функций. Во-первых, краткие и понятные отчеты позволяют руководителям служб ИБ оперативно контролировать состояние защищенности информации, не вдаваясь в детали. Во-вторых, подробные отчеты помогают офицерам безопасности корректировать политики безопасности и настройки систем. В-третьих, наглядные отчеты всегда можно показать топ-менеджерам компании для демонстрации результатов работы DLP-системы и самих специалистов по ИБ (см. таблицу 9).
Почти все конкурирующие решения, рассмотренные в обзоре, предлагают и графические, удобные топ-менеджерам и руководителям служб ИБ, и табличные, более подходящие техническим специалистам, отчеты. Графические отчеты отсутствуют только в DLP InfoWatch, за что им и была снижена оценка.
Сертификация
Вопрос о необходимости сертификации для средств обеспечения информационной безопасности и DLP в частности является открытым, и в рамках профессиональных сообществ эксперты часто спорят на эту тему. Обобщая мнения сторон, следует признать, что сама по себе сертификация не дает серьезных конкурентных преимуществ. В то же время, существует некоторое количество заказчиков, прежде всего, госорганизаций, для которых наличие того или иного сертификата является обязательным.
Кроме того, существующий порядок сертификации плохо соотносится с циклом разработки программных продуктов. В результате потребители оказываются перед выбором: купить уже устаревшую, но сертифицированную версию продукта или актуальную, но не прошедшую сертификацию. Стандартный выход в этой ситуации – приобретение сертифицированного продукта «на полку» и использование нового продукта в реальной среде (см. таблицу 10).
Результаты сравнения
Обобщим впечатления от рассмотренных DLP-решений. В целом, все участники произвели благоприятное впечатление и могут использоваться для предотвращения утечек информации. Различия продуктов позволяют конкретизировать область их применения.
DLP-система InfoWatch может быть рекомендована организациям, для которых принципиально важно наличие сертификата ФСТЭК. Впрочем, последняя сертифицированная версия InfoWatch Traffic Monitor проходила испытания еще в конце 2010 года, а срок действия сертификата истекает в конце 2013 года. Агентские решения на базе InfoWatch EndPoint Security (известного также как EgoSecure) больше подходят предприятиям малого бизнеса и могут использоваться отдельно от Traffic Monitor. Совместное использование Traffic Monitor и EndPoint Security может вызвать проблемы с масштабированием в условиях крупных компаний.
Продукты западных производителей (McAfee, Symantec, Websense), по данным независимых аналитических агентств, значительно менее популярны, нежели российские. Причина - в низком уровне локализации. Причем дело даже не в сложности интерфейса или отсутствии документации на русском языке. Особенности технологий распознавания конфиденциальной информации, преднастроенные шаблоны и правила «заточены» под использование DLP в западных странах и нацелены на выполнение западных же нормативных требований. В результате в России качество распознавания информации оказывается заметно хуже, а выполнение требований иностранных стандартов зачастую неактуально. При этом сами по себе продукты вовсе не плохие, но специфика применения DLP-систем на российском рынке вряд ли позволит им в обозримом будущем стать более популярными, чем отечественные разработки.
Zecurion DLP отличается хорошей масштабируемостью (единственная российская DLP-система с подтвержденным внедрением на более чем 10 тыс. рабочих мест) и высокой технологической зрелостью. Однако удивляет отсутствие веб-консоли, что помогло бы упростить управление корпоративным решением, нацеленным на различные сегменты рынка. Среди сильных сторон Zecurion DLP – высокое качество распознавания конфиденциальной информации и полная линейка продуктов для предотвращения утечек, включая защиту на шлюзе, рабочих станциях и серверах, выявление мест хранения информации и инструменты для шифрования данных.
DLP-система «Дозор-Джет», один из пионеров отечественного рынка DLP, широко распространена среди российских компаний и продолжает наращивать клиентскую базу за счет обширных связей системного интегратора «Инфосистемы Джет», по совместительству и разработчика DLP. Хотя технологически DLP несколько отстает от более мощных собратьев, ее использование может быть оправдано во многих компаниях. Кроме того, в отличие от иностранных решений, «Дозор Джет» позволяет вести архив всех событий и файлов.
Каналами утечки, приводящими к выведению информации за пределы информационной системы компании, могут стать сетевые утечки (например, электронная почта или ICQ), локальные (использование внешних USB-накопителей), хранимые данные (базы данных). Отдельно можно выделить утрату носителя (флэш-память, ноутбук). К классу DLP систему можно отнести, если она соответствует следующим критериям: многоканальность (мониторинг нескольких возможных каналов утечки данных); унифицированный менеджмент (унифицированные средства управления по всем каналам мониторинга); активная защита (соблюдение политики безопасности); учет как содержания, так и контекста.
Конкурентным преимуществом большинства систем является модуль анализа. Производители настолько выпячивают этот модуль, что часто называют по нему свои продукты, например «DLP-решение на базе меток». Поэтому пользователь выбирает решения зачастую не по производительности, масштабируемости или другим, традиционным для корпоративного рынка информационной безопасности критериям, а именно на основе используемого типа анализа документов.
Очевидно, что, поскольку каждый метод имеет свои достоинства и недостатки, использование только одного метода анализа документов ставит решение в технологическую зависимость от него. Большинство производителей используют несколько методов, хотя один из них обычно является «флагманским». Данная статья представляет собой попытку классификации методов, используемых при анализе документов. Дается оценка их сильных и слабых сторон на опыте практического применения нескольких типов продуктов. В статье принципиально не рассматриваются конкретные продукты, т.к. основной задачей пользователя при их выборе является отсев маркетинговых лозунгов типа «мы защитим все от всего», «уникальная запатентованная технология» и осознание того, с чем он останется, когда уйдут продавцы.
Контейнерный анализ

Этот метод анализирует свойства файла или другого контейнера (архива, криптодиска и т.п.), в котором находится информация. Просторечное название таких методов - «решения на метках», что довольно полно отражает их суть. Каждый контейнер содержит некую метку, которая однозначно определяет тип содержащегося внутри контейнера контента. Упомянутые методы практически не требуют вычислительных ресурсов для анализа перемещаемой информации, поскольку метка полностью описывает права пользователя на перемещение контента по любому маршруту. В упрощенном виде такой алгоритм звучит так: «есть метка - запрещаем, нет метки - пропускаем».
Плюсы такого подхода очевидны: быстрота анализа и полное отсутствие ошибок второго рода (когда открытый документ система ошибочно детектирует как конфиденциальный). Такие методы в некоторых источниках называют «детерминистскими».
Очевидны и минусы - система заботится только о помеченной информации: если метка не поставлена, контент не защищен. Необходимо разрабатывать процедуру расстановки меток на новые и входящие документы, а также систему противодействия переносу информации из помеченного контейнера в непомеченный посредством операций с буфером, файловых операций, копирования информации из временных файлов и т.д.
Слабость таких систем проявляется и в организации расстановки меток. Если их расставляет автор документа, то по злому умыслу он имеет возможность не пометить информацию, которую собирается похитить. При отсутствии злого умысла рано или поздно проявятся небрежность или беспечность. Если обязать расставлять метки определенного сотрудника, например офицера информационной безопасности или системного администратора, то он не всегда сможет отличить конфиденциальный контент от открытого, поскольку не знает досконально всех процессов в компании. Так, «белый» баланс должен быть выложен на сайте компании, а «серый» или «черный» нельзя выносить за пределы информационной системы. Но один от другого может отличить только главбух, т.е. один из авторов.
Метки обычно подразделяют на атрибутные, форматные и внешние. Как следует из названия, первые размещаются в атрибутах файлов, вторые - в полях самого файла и третьи - прикрепляются к файлу (ассоциируются с ним) внешними программами.
Контейнерные структуры в ИБ
Иногда плюсами решений на метках считаются также низкие требования к производительности перехватчиков, ведь они лишь проверяют метки, т.е. действуют как турникеты в метро: «есть билет - проходи». Однако не стоит забывать, что чудес не бывает - вычислительная нагрузка в этом случае перекладывается на рабочие станции.
Место решений на метках, какими бы они ни были - защита документных хранилищ. Когда компания имеет документное хранилище, которое, с одной стороны, пополняется достаточно редко, а с другой стороны - точно известны категория и уровень конфиденциальности каждого документа, то организовать его защиту проще всего как раз с использованием меток. Организовать расстановку меток на документах, поступающих в хранилище можно с помощью организационной процедуры. Например, перед тем как отправить документ в хранилище, сотрудник, отвечающий за его функционирование, может обратиться к автору и специалисту с вопросом, какой уровень конфиденциальности документу выставить. Особенно удачно эта задача решается с помощью форматных меток, т.е. каждый входящий документ сохраняется в защищенном формате и затем выдается по запросу сотрудника с указанием его в качестве допущенного к чтению. Современные решения позволяют присваивать право доступа на ограниченное время, а по истечении действия ключа документ просто перестает читаться. Именно по этой схеме организована, например, выдача документации на конкурсы по госзакупкам в США: система управления закупками генерирует документ, который могут прочитать без возможности изменить или скопировать содержимое только перечисленные в этом документе участники конкурса. Ключ на доступ действует только до срока подачи документов на конкурс, после чего документ перестает читаться.
Также с помощью решений, базирующихся на метках, компании организуют документооборот в закрытых сегментах сети, в которой обращаются интеллектуальная собственность и государственная тайна. Вероятно, теперь по требованиям ФЗ «О персональных данных» так же будет организован документооборот в отделах кадров крупных компаний.
Контентный анализ
При реализации описываемых в этом разделе технологий, в отличие от описанных ранее, напротив, совершенно безразлично, в каком контейнере хранится контент. Задача этих технологий - извлечь значащий контент из контейнера или перехватить передачу по каналу связи и проанализировать информацию на наличие запрещенного содержимого.
Основными технологиями в определении запрещенного контента в контейнерах являются контроль сигнатур, контроль на основе хеш-функций и лингвистические методы.
Сигнатуры
Самый простой метод контроля - поиск в потоке данных некоторой последовательности символов. Иногда запрещенную последовательность символов называют «стоп-словом», но в более общем случае она может быть представлена не словом, а произвольным набором символов, например той же меткой. Вообще этот метод не во всех его реализациях можно отнести к контентному анализу. Например, в большинстве устройств класса UTM поиск запрещенных сигнатур в потоке данных происходит без извлечения текста из контейнера, при анализе потока «as is». Или, если система настроена только на одно слово, то результат ее работы - определение 100%-го совпадения, т.е. метод можно отнести к детерминистским.
Однако чаще поиск определенной последовательности символов все же применяют при анализе текста. В подавляющем большинстве случаев сигнатурные системы настроены на поиск нескольких слов и частоту встречаемости терминов, т.е. мы будем все же относить эту систему к системам анализа контента.
К достоинствам этого метода можно отнести независимость от языка и простоту пополнения словаря запрещенных терминов: если вы хотите воспользоваться этим методом для поиска в потоке данных слова на языке пушту, вам не обязательно владеть этим языком, достаточно лишь знать, как оно пишется. Так же легко добавляется, например, транслитерированный русский текст или «олбанский» язык, что немаловажно, например, при анализе SMS -текстов, сообщений ICQ или постов в блогах.
Недостатки становятся очевидными при использования не-английского языка. К сожалению, большинство производителей систем анализа текстов работают для американского рынка, а английский язык очень «сигнатурен» - формы слов чаще всего образуются с помощью предлогов без изменения самого слова. В русском языке все гораздо сложнее. Возьмем, к примеру, милое сердцу сотрудника информационной безопасности слово «secret» (секрет). В английском оно означает и существительное «секрет», и прилагательное «секретный», и глагол «засекретить». В русском языке из корня «секрет» можно образовать несколько десятков различных слов. Т.е. если в англоговорящей организации сотруднику информационной безопасности достаточно ввести одно слово, в русскоговорящей придется вводить пару десятков слов и затем еще изменять их в шести различных кодировках.
Кроме того, такие методы неустойчивы к примитивному кодированию. Практически все они пасуют перед любимым приемом начинающих спамеров - заменой символов на похожие по начертанию. Автор неоднократно демонстрировал офицерам безопасности элементарный прием - проход конфиденциального текста через сигнатурные фильтры. Берется текст, содержащий, например, фразу «совершенно секретно», и почтовый перехватчик, настроенный на эту фразу. Если текст открыть в MS Word, то двухсекундная операция: Ctrl+F, «найти "o" (русской раскладки)», «заменить на "o" (английской раскладки)», «заменить все», «отослать документ» - делает документ абсолютно невидимым для этого фильтра. Тем более обидно, что такая замена проводится штатными средствами MS Word или любого другого текстового редактора, т.е. они доступны пользователю, даже если у него нет прав локального администратора и возможности запускать программы шифрования.
Чаще всего сигнатурный контроль потоков входит в функционал UTM-устройств, т.е. решений, очищающих трафик от вирусов, спама, вторжений и любых других угроз, детектирование которых происходит по сигнатурам. Поскольку эта функция является «бесплатной», зачастую пользователи считают, что этого достаточно. Такие решения действительно защищают от случайных утечек, т.е. в тех случаях, когда исходящий текст не изменяется отправителем с целью обойти фильтр, но против злонамеренных пользователей они бессильны.
Маски
Расширением функционала поиска сигнатур «стоп-слов» является поиск их масок. Он представляет собой поиск такого содержания, которое невозможно точно указать в базе «стоп-слов», но можно указать его элемент или структуру. К такой информации следует отнести любые коды, характеризующие персону или предприятие: ИНН, номера счетов, документов и т.д. Искать их с помощью сигнатур невозможно.
Неразумно задавать номер конкретной банковской карты в качестве объекта поиска, а хочется находить любой номер кредитной карты, как бы он не был написан - с пробелами или слитно. Это не просто желание, а требование стандарта PCI DSS : незашифрованные номера пластиковых карт запрещено посылать по электронной почте, т.е. обязанностью пользователя является находить такие номера в электронной почте и сбрасывать запрещенные сообщения.
Вот, например, маска, задающая такое стоп-слово, как название конфиденциального или секретного приказа, номер которого начинается с нуля. Маска учитывает не только произвольный номер, но и любой регистр и даже подмену русских букв латинскими. Маска записана в стандартной нотации «REGEXP», хотя у различных DLP-систем могут быть собственные, более гибкие нотации. Еще хуже дело обстоит с номерами телефонов. Эта информация отнесена к персональным данным, а писать ее можно десятком способов - с использованием различных сочетаний пробелов, разных типов скобок, плюса и минуса и т.д. Здесь, пожалуй, единственной маской не обойтись. Например, в антиспамовых системах, где приходится решать сходную задачу, для детектирования телефонного номера используют несколько десятков масок одновременно.
Множество различных кодов, вписанных в деятельность компаний и ее сотрудников, охраняются многими законами и представляют собой коммерческую тайну, банковскую тайну, персональные данные и другую защищаемую законом информацию, поэтому проблема детектирования их в трафике является обязательным условием любого решения.
Хеш-функции
Различного типа хеш-функции образцов конфиденциальных документов одно время считались новым словом на рынке защиты от утечек, хотя сама технология существует с 1970-х годов. На Западе этот метод иногда называется «digital fingerprints», т.е. «цифровые отпечатки пальцев», или «шиндлы» на научном сленге.
Суть всех методов одна и та же, хотя конкретные алгоритмы у каждого производителя могут существенно отличаться. Некоторые алгоритмы даже патентуются, что подтверждает уникальность реализации. Общий сценарий действия такой: набирается база образцов конфиденциальных документов. С каждого из них снимается «отпечаток», т.е. из документа извлекается значимое содержимое, которое приводится к некоторому нормальному, например (но не обязательно) текстовому виду, затем снимаются хеши всего содержимого и его частей, например абзацев, предложений, пятерок слов и т.д., детализация зависит от конкретной реализации. Эти отпечатки хранятся в специальной базе данных.
Перехваченный документ точно так же очищается от служебной информации и приводится к нормальному виду, затем с него по тому же алгоритму снимаются отпечатки-шиндлы. Полученные отпечатки ищутся в базе данных отпечатков конфиденциальных документов, и если находятся - документ считается конфиденциальным. Поскольку этот метод применяется для нахождения прямых цитат из документа-образца, технология иногда называется «антиплагиатной».
Большинство преимуществ такого метода являются одновременно его недостатками. Прежде всего, это требование использования образцов документов. С одной стороны, пользователю не надо беспокоиться о стоп-словах, значимых терминах и другой информации, совершенно неспецифической для офицеров безопасности деятельности. С другой стороны, «нет образца - нет защиты», что порождает те же самые проблемы с новыми и входящими документами, что и при обращении к технологиям, базирующимся на метках. Очень важным плюсом такой технологии является ее нацеленность на работу с произвольными последовательностями символов. Из этого следует, в первую очередь, независимость от языка текста - хоть иероглифы, хоть пушту. Далее, одно из главных следствий этого свойства - возможность снятия отпечатков с нетекстовой информации - баз данных, чертежей, медиафайлов. Именно эти технологии применяют голливудские студии и мировые студии звукозаписи для защиты медиаконтента в своих цифровых хранилищах.
К сожалению, низкоуровневые хеш-функции неустойчивы к примитивному кодированию, рассматривавшемуся в примере с сигнатурами. Они легко справляются с изменением порядка слов, перестановкой абзацев и другими ухищрениями «плагиаторов», но, например, изменение букв по всему документу разрушает хеш-образец и такой документ становится невидимым для перехватчика.
Использование только этого метода осложняет работу с формами. Так, пустая форма заявления на кредит является свободно распространяемым документом, а заполненная - конфиденциальным, поскольку содержит персональные данные. Если просто снять отпечаток с пустой формы, то перехваченный заполненный документ будет содержать всю информацию из пустой формы, т.е. отпечатки будут во многом совпадать. Таким образом, система либо пропустит конфиденциальную информацию, либо воспрепятствует свободному распространению пустых форм.
Несмотря на упомянутые недостатки, этот метод имеет широкое распространение, особенно в таком бизнесе, который не может себе позволить квалифицированных сотрудников, а действует по принципу «сложи всю конфиденциальную информацию в эту папку и спи спокойно». В этом смысле требование конкретных документов для их защиты чем-то похоже на решения, базирующиеся на метках, только хранящихся отдельно от образцов и сохраняющихся при изменении формата файла, копировании части файла и т.д. Однако крупный бизнес, имеющий в обороте сотни тысяч документов, зачастую просто не в состоянии предоставить образцы конфиденциальных документов, т.к. бизнес-процессы компании этого не требуют. Единственное, что есть (или, честнее, должно быть) на каждом предприятии, - «Перечень информации, составляющей коммерческую тайну». Сделать из нее образцы - нетривиальная задача.
Простота добавления образцов к базе контролируемого контента зачастую играет с пользователями злую шутку. Это ведет к постепенному увеличению базы отпечатков, существенно влияющему на производительность системы: чем больше образцов, тем больше сравнений каждого перехваченного сообщения. Поскольку каждый отпечаток занимает от 5 до 20% оригинала, база отпечатков постепенно разрастается. Пользователи отмечают резкое падение производительности, когда база начинает превышать объем оперативной памяти фильтрующего сервера. Обычно проблема решается регулярным аудитом образцов документов и удалением устаревших или дублирующихся образцов, т.е. экономя на внедрении, пользователи теряют на эксплуатации.
Лингвистические методы
Самым распространенным на сегодняшний день методом анализа является лингвистический анализ текста. Он настолько популярен, что зачастую именно он в просторечье именуется «контентной фильтрацией», т.е. несет на себе характеристику всего класса методов анализа содержимого. С точки зрения классификации и хеш-анализ, и анализ сигнатур, и анализ масок являются «контентной фильтрацией», т.е. фильтрацией трафика на основе анализа содержимого.
Как понятно из названия, метод работает только с текстами. Вы не защитите с его помощью базу данных, состоящую только из чисел и дат, тем более - чертежи, рисунки и коллекцию любимых песен. Зато с текстами этот метод творит чудеса.
Лингвистика как наука состоит из многих дисциплин - от морфологии до семантики. Поэтому лингвистические методы анализа тоже различаются между собой. Есть методы, использующие лишь стоп-слова, только вводящиеся на уровне корней, а сама система уже составляет полный словарь; есть базирующиеся на расставлении весов встречающихся в тексте терминов. Есть в лингвистических методах и свои отпечатки, базирующиеся на статистике; например, берется документ, считаются пятьдесят самых употребляемых слов, затем выбирается по 10 самых употребляемых из них в каждом абзаце. Такой «словарь» представляет собой практически уникальную характеристику текста и позволяет находить в «клонах» значащие цитаты.
Анализ всех тонкостей лингвистического анализа не входит в рамки этой статьи, поэтому сосредоточимся на достоинствах и недостатках.
Достоинством метода является полная нечувствительность к количеству документов, т.е. редкая для корпоративной информационной безопасности масштабируемость. База контентной фильтрации (набор ключевых словарных классов и правил) не меняется в размере от появления новых документов или процессов в компании.
Кроме того, пользователи отмечают в этом методе сходство со «стоп-словами» в той части, что если документ задержан, то сразу видно, из-за чего это произошло. Если система, базирующаяся на отпечатках, сообщает, что какой-то документ похож на другой, то офицеру безопасности придется самому сравнивать два документа, а при лингвистическом анализе он получит уже размеченный контент. Лингвистические системы наряду с сигнатурной фильтрацией так распространены, поскольку позволяют начать работать без изменений в компании сразу после инсталляции. Нет нужды возиться с расстановкой меток и снятием отпечатков, инвентаризировать документы и делать другую неспецифическую для офицера безопасности работу.
Недостатки столь же очевидны, и первый - зависимость от языка. В каждой стране, язык которой поддерживается производителем, это не является недостатком, однако с точки зрения глобальных компаний, имеющих кроме единого языка корпоративного общения (например, английского), еще множество документов на локальных языках в каждой стране, это явный недостаток.
Еще один недостаток - высокий процент ошибок второго рода, для снижения которого требуется квалификация в области лингвистики (для тонкой настройки базы фильтрации). Стандартные отраслевые базы обычно дают точность фильтрации 80-85%. Это означает, что каждое пятое-шестое письмо перехвачено ошибочно. Настройка базы до приемлемых 95-97% точности срабатывания связана обычно с вмешательством специально обученного лингвиста. И хотя для обучения корректировке базы фильтрации достаточно иметь два дня свободного времени и владеть языком на уровне выпускника средней школы, эту работу, кроме офицера безопасности, делать некому, а он обычно считает такую работу непрофильной. Привлекать же человека со стороны всегда рискованно - ведь работать ему придется с конфиденциальной информацией. Выходом из этой ситуации обычно является покупка дополнительного модуля - самообучающегося «автолингвиста», которому «скармливаются» ложные срабатывания, и он автоматически адаптирует стандартную отраслевую базу.
Лингвистические методы выбирают тогда, когда хотят минимизировать вмешательство в бизнес, когда служба защиты информации не имеет административного ресурса изменить существующие процессы создания и хранения документов. Они работают всегда и везде, хотя и с упомянутыми недостатками.
Популярные каналы случайных утечек мобильные носители информации
Аналитики InfoWatch считают, что наиболее популярным каналом для случайных утечек остаются мобильные носители информации (ноутбуки, флеш-накопители, мобильные коммуникаторы и др.), поскольку пользователи подобных устройств зачастую пренебрегают средствами шифрования данных.
Другой частой причиной случайных утечек становится бумажный носитель: его проконтролировать сложнее, чем электронный, так как, например, после выхода листа из принтера следить за ним можно лишь «вручную»: контроль за бумажными носителями слабее контроля за компьютерной информацией. Многие средства защиты от утечек (назвать их полноценными DLP-системами нельзя) не контролируют канал вывода информации на принтер – так конфиденциальные данные легко выходят за пределы организации.
Решить данную проблему позволяют многофункциональные DLP-системы, которые блокируют отправку на печать недозволенной информации и проверяют соответствие почтового адреса и адресата.
Помимо этого, обеспечение защиты от утечек значительно усложняется растущей популярностью мобильных устройств, ведь соответствующих DLP-клиентов пока нет. Кроме того, очень тяжело выявить утечку в случае применения криптографии или стеганографии. Инсайдер, чтобы обойти какой-то фильтр, всегда может обратиться за «лучшими практиками» в Интернет. То есть от организованной умышленной утечки DLP-средства защищают довольно плохо.
Эффективности инструментов DLP могут мешать их очевидные изъяны: современные решения защиты от утечек не позволяют контролировать и перекрывать все имеющиеся информационные каналы. Системы DLP проконтролируют корпоративную почту, использование веб-ресурсов, мгновенный обмен сообщениями, работу с внешними носителями, печать документов и содержимое жестких дисков. Но не подконтрольным для систем DLP пока остается Skype. Только Trend Micro успела заявить, что умеет контролировать работу этой программы коммуникации. Остальные разработчики обещают, что соответствующий функционал будет обеспечен в следующей версии их защитного ПО.
Но если Skype обещает открыть свои протоколы для разработчиков DLP, то другие решения, например Microsoft Collaboration Tools для организации совместной работы, остаются закрытыми для сторонних программистов. Как контролировать передачу информации по этому каналу? Между тем в современном мире получает развитие практика, когда специалисты удаленно объединяются в команды для работы над общим проектом и распадаются после его завершения.
Основными источниками утечек конфиденциальной информации в первой половине 2010 года по-прежнему остаются коммерческие (73,8%) и государственные (16%) организации. Около 8% утечек происходят из образовательных учреждений. Характер утекающей конфиденциальной информации – персональные данные (почти 90% всех информационных утечек).
Лидерами по утечкам в мире традиционно являются США и Великобритания (также в пятерку стран по наибольшему количеству утечек вошли Канада, Россия и Германия с существенно более низкими показателями), что связанно с особенностью законодательства данных стран, предписывающего сообщать обо всех инцидентах утечки конфиденциальных данных. Аналитики Infowatch прогнозируют в будущем году сокращение доли случайных утечек и рост доли умышленных.
Трудности внедрения
Помимо очевидных трудностей внедрению DLP препятствует и сложность выбора подходящего решения, поскольку различные поставщики систем DLP исповедуют собственные подходы к организации защиты. У одних запатентованы алгоритмы анализа контента по ключевым словам, а кто-то предлагает метод цифровых отпечатков. Как в этих условиях выбрать оптимальный продукт? Что эффективнее? Ответить на эти вопросы очень сложно, так как внедрений систем DLP на сегодня крайне мало, а реальных практик их использования (на которые можно было бы полагаться) еще меньше. Но те проекты, которые все же были реализованы, показали, что более половины объема работ и бюджета в них составляет консалтинг, и это обычно вызывает большой скепсис у руководства. Кроме того, как правило, под требования DLP приходится перестраивать существующие бизнес-процессы предприятия, а на это компании идут с трудом.
Насколько внедрение DLP помогает соответствовать действующим требованиям регуляторов? На Западе внедрение DLP-систем мотивируют законы, стандарты, отраслевые требования и другие нормативные акты. По мнению экспертов, имеющиеся за рубежом четкие требования законодательства, методические указания по обеспечению требований являются реальным двигателем рынка DLP, так как внедрение специальных решений исключает претензии со стороны регуляторов. У нас в этой сфере положение совсем иное, и внедрение DLP-систем не помогает соответствовать законодательству.
Неким стимулом для внедрения и использования DLP в корпоративной среде может стать необходимость защищать коммерческие секреты компаний и выполнить требования федерального закона «О коммерческой тайне».
Почти на каждом предприятии приняты такие документы, как «Положение о коммерческой тайне» и «Перечень сведений, составляющих коммерческую тайну», и их требования следует выполнять. Существует мнение, что закон «О коммерческой тайне» (98-ФЗ) не работает, тем не менее руководители компаний хорошо осознают, что им важно и нужно защищать свои коммерческие секреты. Причем это осознание гораздо выше понимания важности закона «О персональных данных» (152-ФЗ), и любому руководителю намного проще объяснить необходимость внедрить конфиденциальный документооборот, чем рассказывать про защиту персональных данных.
Что мешает использовать DLP в процессах автоматизации защиты коммерческой тайны? По гражданскому кодексу РФ, для введения режима защиты коммерческой тайны необходимо лишь, чтобы информация обладала некой ценностью и была включена в соответствующий перечень. В этом случае обладатель такой информации по закону обязан принять меры к охране конфиденциальных сведений.
Вместе с тем очевидно, что и DLP не сможет решить всех вопросов. В частности, прикрыть доступ к конфиденциальной информации третьим лицам. Но для этого существуют другие технологии. Многие современные DLP-решения умеют с ними интегрироваться. Тогда при выстраивании этой технологической цепочки может получиться работающая система защиты коммерческой тайны. Такая система будет более понятной для бизнеса, и именно бизнес сможет выступить заказчиком системы защиты от утечек.
Россия и Запад
По мнению аналитиков, В России иное отношение к безопасности и иной уровень зрелости компаний, поставляющих решения DLP. Рынок России ориентируется на специалистов по безопасности и узкоспециализированные проблемы. Люди, занимающиеся предотвращением утечки данных, не всегда понимают, какие данные имеют ценность. В России «милитаристский» подход к организации систем безопасности: прочный периметр с межсетевыми экранами и все усилия прилагаются к тому, чтобы не допустить проникновения внутрь.
Но если сотрудник компании имеет доступ к количеству информации, которое не требуется для выполнения его обязанностей? С другой стороны, если посмотреть, какой подход формировался на Западе в последние 10-15 лет, то можно сказать, что больше внимания уделяется ценности информации. Ресурсы направляются туда, где находится ценная информация, а не на всю информацию подряд. Пожалуй, это самая большая культурологическая разница между Западом и Россией. Однако, говорят аналитики, ситуация меняется. Информация начинает восприниматься как деловой актив, а на эволюцию потребуется какое-то время.
Не существует всеобъемлющего решения
Стопроцентной защиты от утечек еще не разработал ни один производитель. Проблемы с использованием DLP-продуктов некоторые эксперты формулируют примерно так: эффективное использование опыта борьбы с утечками, применяемого в DLP-системах, требует понимания, что значительная работа по обеспечению защиты от утечек должна быть проведена на стороне заказчика, поскольку никто лучше него не знает собственных информационных потоков.
Другие считают, что защититься от утечек нельзя: предотвратить утечку информации невозможно. Поскольку информация имеет для кого-нибудь ценность, она будет получена раньше или позже. Программные средства могут сделать получение этой информации более дорогостоящим и требующим больших временных затрат процессом. Это может значительно снизить выгоду обладания информацией, ее актуальность. Значит, эффективность работы DLP-систем стоит контролировать.
»С егодня рынок DLP-систем является одним из самых быстрорастущих среди всех средств обеспечения информационной безопасности. Впрочем, отечественная ИБ-сфера пока не совсем успевает за мировыми тенденциями, в связи с чем у рынка DLP-систем в нашей стране есть свои особенности.
Что такое DLP и как они работают?
Прежде чем говорить о рынке DLP-систем, необходимо определиться с тем, что, собственно говоря, подразумевается, когда речь идёт о подобных решениях. Под DLP-системами принято понимать программные продукты, защищающие организации от утечек конфиденциальной информации. Сама аббревиатура DLP расшифровывается как Data Leak Prevention, то есть, предотвращение утечек данных.
Подобного рода системы создают защищенный цифровой «периметр» вокруг организации, анализируя всю исходящую, а в ряде случаев и входящую информацию. Контролируемой информацией должен быть не только интернет-трафик, но и ряд других информационных потоков: документы, которые выносятся за пределы защищаемого контура безопасности на внешних носителях, распечатываемые на принтере, отправляемые на мобильные носители через Bluetooth и т.д.
Поскольку DLP-система должна препятствовать утечкам конфиденциальной информации, то она в обязательном порядке имеет встроенные механизмы определения степени конфиденциальности документа, обнаруженного в перехваченном трафике. Как правило, наиболее распространены два способа: путём анализа специальных маркеров документа и путём анализа содержимого документа. В настоящее время более распространен второй вариант, поскольку он устойчив перед модификациями, вносимыми в документ перед его отправкой, а также позволяет легко расширять число конфиденциальных документов, с которыми может работать система.
«Побочные» задачи DLP
Помимо своей основной задачи, связанной с предотвращением утечек информации, DLP-системы также хорошо подходят для решения ряда других задач, связанных с контролем действий персонала.
Наиболее часто DLP-системы применяются для решения следующих неосновных для себя задач:
- контроль использования рабочего времени и рабочих ресурсов сотрудниками;
- мониторинг общения сотрудников с целью выявления «подковерной» борьбы, которая может навредить организации;
- контроль правомерности действий сотрудников (предотвращение печати поддельных документов и пр.);
- выявление сотрудников, рассылающих резюме, для оперативного поиска специалистов на освободившуюся должность.
За счет того, что многие организации полагают ряд этих задач (особенно контроль использования рабочего времени) более приоритетными, чем защита от утечек информации, возник целый ряд программ, предназначенных именно для этого, однако способных в ряде случаев работать и как средство защиты организации от утечек. От полноценных DLP-систем такие программы отличает отсутствие развитых средств анализа перехваченных данных, который должен производиться специалистом по информационной безопасности вручную, что удобно только для совсем небольших организаций (до десяти контролируемых сотрудников).
Технология DLP
Digital Light Processing (DLP) — передовая технология, изобретенная компанией Texas Instruments . Благодаря ей оказалось возможным создавать очень небольшие, очень легкие (3 кг — разве это вес?) и, тем не менее, достаточно мощные (более 1000 ANSI Lm) мультимедиапроекторы.
Краткая история создания
Давным-давно, в далекой галактике…
В 1987 году Dr. Larry J. Hornbeck изобрел цифровое мультизеркальное устройство (Digital Micromirror Device или DMD). Это изобретение завершило десятилетние исследования Texas Instruments в области микромеханических деформируемых зеркальных устройств (Deformable Mirror Devices или снова DMD). Суть открытия состояла в отказе от гибких зеркал в пользу матрицы жестких зеркал, имеющих всего два устойчивых положения.
В 1989 году Texas Instruments становится одной из четырех компаний, избранных для реализации «проекторной» части программы U.S. High-Definition Display, финансируемой управлением перспективного планирования научно-исследовательских работ (ARPA).
В мае 1992 года TI демонстрирует первую основанную на DMD систему, поддерживающую современный стандарт разрешения для ARPA.
High-Definition TV (HDTV) версия DMD на основе трех DMD высокого разрешения была показана в феврале 1994 года.
Массовые продажи DMD-чипов началиcь в 1995 году.
Технология DLP
Ключевым элементом мультимедиапроекторов, созданных по технологии DLP, является матрица микроскопических зеркал (DMD-элементов) из алюминиевого сплава, обладающего очень высоким коэффициентом отражения. Каждое зеркало крепится к жесткой подложке, которая через подвижные пластины соединяется с основанием матрицы. Под противоположными углами зеркал размещены электроды, соединенные с ячейками памяти CMOS SRAM. Под действием электрического поля подложка с зеркалом принимает одно из двух положений, отличающихся точно на 20° благодаря ограничителям, расположенным на основании матрицы.
Два этих положения соответствуют отражению поступающего светового потока соответственно в объектив и эффективный светопоглотитель, обеспечивающий надежный отвод тепла и минимальное отражение света.
Шина данных и сама матрица сконструированы так, чтобы обеспечивать до 60 и более кадров изображения в секунду с разрешением 16 миллионов цветов.
Матрица зеркал вместе с CMOS SRAM и составляют DMD-кристалл — основу технологии DLP.
Впечатляют небольшие размеры кристалла. Площадь каждого зеркала матрицы составляет 16 микрон и менее, а расстояние между зеркалами около 1 микрона. Кристалл, да и не один, легко помещается на ладони.
Всего, если Texas Instruments нас не обманывает, выпускаются три вида кристаллов (или чипов) c различными разрешениями. Это:
- SVGA: 848×600; 508,800 зеркал
- XGA: 1024×768 с черной апертурой (межщелевым пространством); 786,432 зеркал
- SXGA: 1280×1024; 1,310,720 зеркал
 |
 |
Итак, у нас есть матрица, что мы можем с ней сделать? Ну конечно, осветить ее световым потоком помощнее и поместить на пути одного из направлений отражений зеркал оптическую систему, фокусирующую изображение на экран. На пути другого направления разумным будет поместить светопоглотитель, чтобы ненужный свет не причинял неудобств. Вот мы уже и можем проецировать одноцветные картинки. Но где же цвет? Где яркость?

А вот в этом, похоже, и заключалось изобретение товарища Larry, речь о котором шла в первом абзаце раздела истории создания DLP. Если вы так и не поняли, в чем дело, — приготовьтесь, ибо сейчас с вами может случиться шок:), т. к. это само собой напрашивающееся элегантное и вполне очевидное решение является на сегодня самым передовым и технологичным в области проецирования изображения.
Вспомните детский фокус с вращающимся фонариком, свет от которого в некоторый момент сливается и превращается в светящийся круг. Эта шутка нашего зрения и позволяет окончательно отказаться от аналоговых систем построения изображения в пользу полностью цифровых. Ведь даже цифровые мониторы на последнем этапе имеют аналоговую природу.
Но что произойдет, если мы заставим зеркало с большой частотой переключаться из одного положения в другое? Если пренебречь временем переключения зеркала (а благодаря его микроскопическим размерам этим временем вполне можно пренебречь), то видимая яркость упадет не иначе как в два раза. Изменяя отношение времени, в течение которого зеркало находится в одном и другом положении, мы легко можем изменять и видимую яркость изображения. А так как частота циклов очень и очень большая, никакого видимого мерцания не будет и в помине. Эврика. Хотя ничего особенного, это всё давно известно:)
Ну, а теперь последний штрих. Если скорость переключения достаточно высока, то на пути светового потока мы можем последовательно помещать светофильтры и тем самым создавать цветное изображение.
Вот, собственно, и вся технология. Дальнейшее ее эволюционное развитие мы проследим на примере устройства мультимедиапроекторов.
Устройство DLP-проекторов
Texas Instruments не занимается производством DLP-проекторов, этим занимается множество других компаний, таких, как 3M, ACER, PROXIMA, PLUS, ASK PROXIMA, OPTOMA CORP., DAVIS, LIESEGANG, INFOCUS, VIEWSONIC, SHARP, COMPAQ, NEC, KODAK, TOSHIBA, LIESEGANG и др. Большинство выпускаемых проекторов относятся к портативным, обладающим массой от 1,3 до 8 кг и мощностью до 2000 ANSI lumens. Проекторы делятся на три типа.
Одноматричный проектор
Самый простой тип, который мы уже описали, это — одноматричный проектор , где между источником света и матрицей помещается вращающийся диск с цветными светофильтрами — синим, зеленым и красным. Частота вращения диска определяет привычную нам частоту кадров.

Изображение формируется поочередно каждым из основных цветов, в результате получается обычное полноцветное изображение.
Все, или почти все портативные проекторы построены по одноматричному типу.
Дальнейшим развитием этого типа проекторов стало введение четвертого, прозрачного светофильтра, позволяющего ощутимо увеличить яркость изображения.
Трехматричный проектор
Самым сложным типом проекторов является трехматричный проектор , где свет расщепляется на три цветовых потока и отражается сразу от трех матриц. Такой проектор имеет самый чистый цвет и частоту кадров, не ограниченную скоростью вращения диска, как у одноматричных проекторов.

Точное соответствие отраженного потока от каждой матрицы (сведение) обеспечивается с помощью призмы, как вы можете видеть на рисунке.
Двухматричный проектор
Промежуточным типом проекторов является двухматричный проектор . В данном случае свет расщепляется на два потока: красный отражается от одной DMD-матрицы, а синий и зеленый — от другой. Светофильтр, соответственно, удаляет из спектра синюю либо зеленую составляющие поочередно.

Двухматричный проектор обеспечивает промежуточное качество изображения по сравнению с одноматричным и трехматричным типом.
Сравнение LCD и DLP-проекторов
По сравнению с LCD-проекторами DLP-проекторы обладают рядом важных преимуществ:

Есть ли недостатки у технологии DLP?
Но теория теорией, а на практике еще есть над чем поработать. Основной недостаток заключается в несовершенстве технологии и как следствие — проблеме залипания зеркал.
Дело в том, что при таких микроскопических размерах мелкие детали норовят «слипнуться», и зеркало с основанием тому не исключение.
Несмотря на приложенные компанией Texas Instruments усилия по изобретению новых материалов, уменьшающих прилипание микрозеркал, такая проблема существует, как мы увидели при тестировании мультимедиапроектора Infocus LP340 . Но, должен заметить, жить она особо не мешает.
Другая проблема не так очевидна и заключается в оптимальном подборе режимов переключения зеркал. У каждой компании, производящей DLP-проекторы, на этот счет свое мнение.
Ну и последнее. Несмотря на минимальное время переключения зеркал из одного положения в другое, едва заметный шлейф на экране этот процесс оставляет. Эдакий бесплатный antialiasing.
Развитие технологии
- Помимо введения прозрачного светофильтра постоянно ведутся работы по уменьшению межзеркального пространства и площади столбика, крепящего зеркало к подложке (черная точка посередине элемента изображения).
- Путем разбиения матрицы на отдельные блоки и расширения шины данных увеличивается частота переключения зеркал.
- Ведутся работы по увеличению количества зеркал и уменьшению размера матрицы.
- Постоянно повышается мощность и контрастность светового потока. В настоящее время уже существуют трехматричные проекторы мощностью свыше 10000 ANSI Lm и контрастностью более 1000:1, нашедшие свое применение в ультрасовременных кинотеатрах, использующих цифровые носители.
- Технология DLP полностью готова заменить CRT-технологию показа изображения в домашних кинотеатрах.
Заключение
Это далеко не все, что можно было бы рассказать о технологии DLP, например, мы не затронули тему использования DMD-матриц в печати. Но мы подождем, пока компания Texas Instruments не подтвердит информацию, доступную из других источников, дабы не подсунуть вам «липу». Надеюсь, этого небольшого рассказа вполне достаточно, чтобы получить пусть не самое полное, но достаточное представление о технологии и не мучать продавцов расспросами о преимуществе DLP-проекторов над другими.
Спасибо Алексею Слепынину за помощь в оформлении материала
В наши дни можно часто услышать о такой технологии, как DLP-системы. Что это такое, и где это используется? Это программное обеспечение, предназначенное для предотвращения потери данных путем обнаружения возможных нарушений при их отправке и фильтрации. Кроме того, такие сервисы осуществляют мониторинг, обнаружение и блокирование при ее использовании, движении (сетевом трафике), а также хранении.
Как правило, утечка конфиденциальных данных происходит по причине работы с техникой неопытных пользователей либо является результатом злонамеренных действий. Такая информация в виде частных или корпоративных сведений, объектов интеллектуальной собственности (ИС), финансовой или медицинской информации, сведений кредитных карт и тому подобное нуждается в усиленных мерах защиты, которые могут предложить современные информационные технологии.
Термины «потеря данных» и «утечка данных» связаны между собой и часто используются как синонимы, хотя они несколько отличаются. Случаи утери информации превращаются в ее утечку тогда, когда источник, содержащий конфиденциальные сведения, пропадает и впоследствии оказывается у несанкционированной стороны. Тем не менее утечка данных возможна без их потери.
Категории DLP
Технологические средства, используемые для борьбы с утечкой данных, можно разделить на следующие категории: стандартные меры безопасности, интеллектуальные (продвинутые) меры, контроль доступа и шифрование, а также специализированные DLP-системы (что это такое - подробно описано ниже).

Стандартные меры
Такие стандартные меры безопасности, как системы обнаружения вторжений (IDS) и антивирусное программное обеспечение, представляют собой обычные доступные механизмы, которые охраняют компьютеры от аутсайдера, а также инсайдерских атак. Подключение брандмауэра, к примеру, исключает доступ к внутренней сети посторонних лиц, а система обнаружения вторжений обнаруживает попытки проникновения. Внутренние атаки возможно предотвратить путем проверки антивирусом, обнаруживающих установленных на ПК, которые отправляют конфиденциальную информацию, а также за счет использования сервисов, которые работают в архитектуре клиент-сервер без каких-либо личных или конфиденциальных данных, хранящихся на компьютере.
Дополнительные меры безопасности
Дополнительные меры безопасности используют узкоспециализированные сервисы и временные алгоритмы для обнаружения ненормального доступа к данным (т. е. к базам данных либо информационно-поисковых системам) или ненормального обмена электронной почтой. Кроме того, такие современные информационные технологии выявляют программы и запросы, поступающие с вредоносными намерениями, и осуществляют глубокие проверки компьютерных систем (например, распознавание нажатий клавиш или звуков динамика). Некоторые такие сервисы способны даже проводить мониторинг активности пользователей для обнаружения необычного доступа к данным.

Специально разработанные DLP-системы - что это такое?
Разработанные для защиты информации DLP-решения служат для обнаружения и предотвращения несанкционированных попыток копировать или передавать конфиденциальные данные (преднамеренно или непреднамеренно) без разрешения или доступа, как правило, со стороны пользователей, которые имеют право доступа к конфиденциальным данным.
Для того чтобы классифицировать определенную информацию и регулировать доступ к ней, эти системы используют такие механизмы, как точное соответствие данных, структурированная дактилоскопия, прием правил и регулярных выражений, опубликований кодовых фраз, концептуальных определений и ключевых слов. Типы и сравнение DLP-систем можно представить следующим образом.
Network DLP (также известная как анализ данных в движении или DiM)
Как правило, она представляет собой аппаратное решение либо программное обеспечение, которое устанавливается в точках сети, исходящих вблизи периметра. Она анализирует сетевой трафик для обнаружения конфиденциальных данных, отправляемых в нарушение

Endpoint DLP (данные при использовании )
Такие системы функционируют на рабочих станциях конечных пользователей или серверов в различных организациях.
Как и в других сетевых системах, конечная точка может быть обращена как к внутренним, так и к внешним связям и, следовательно, может быть использована для контроля потока информации между типами либо группами пользователей (например, «файерволы»). Они также способны осуществлять контроль за электронной почтой и обменом мгновенными сообщениями. Это происходит следующим образом - прежде, чем сообщения будут загружены на устройство, они проверяются сервисом, и при содержании в них неблагоприятного запроса они блокируются. В результате они становятся неоправленными и не подпадают под действие правил хранения данных на устройстве.
DLP-система (технология) имеет преимущество в том, что она может контролировать и управлять доступом к устройствам физического типа (к примеру, мобильные устройства с возможностями хранения данных), а также иногда получать доступ к информации до ее шифрования.

Некоторые системы, функционирующие на основе конечных точек, также могут обеспечить контроль приложений, чтобы блокировать попытки передачи конфиденциальной информации, а также обеспечить незамедлительную обратную связь с пользователем. Вместе с тем они имеют недостаток в том, что они должны быть установлены на каждой рабочей станции в сети, и не могут быть использованы на мобильных устройствах (например, на сотовых телефонах и КПК) или там, где они не могут быть практически установлены (например, на рабочей станции в интернет-кафе). Это обстоятельство необходимо учитывать, делая выбор DLP-системы для каких-либо целей.
Идентификация данных
DLP-системы включают в себя несколько методов, направленных на выявление секретной либо конфиденциальной информации. Иногда этот процесс путают с расшифровкой. Однако идентификация данных представляет собой процесс, посредством которого организации используют технологию DLP, чтобы определить, что искать (в движении, в состоянии покоя или в использовании).
Данные при этом классифицируются как структурированные или неструктурированные. Первый тип хранится в фиксированных полях внутри файла (например, в виде электронных таблиц), в то время как неструктурированный относится к свободной форме текста (в форме текстовых документов или PDF-файлов).
По оценкам специалистов, 80% всех данных - неструктурированные. Соответственно, 20% - структурированные. основывается на контент-анализе, ориентированном на структурированную информацию и контекстный анализ. Он делается по месту создания приложения или системы, в которой возникли данные. Таким образом, ответом на вопрос «DLP-системы - что это такое?» послужит определение алгоритма анализа информации.
Используемые методы
Методы описания конфиденциального содержимого на сегодняшний день многочисленны. Их можно разделить на две категории: точные и неточные.
Точные методы - это те, которые связаны с анализом контента и практически сводят к нулю ложные положительные ответы на запросы.
Все остальные являются неточными и могут включать в себя: словари, ключевые слова, регулярные выражения, расширенные регулярные выражения, мета-теги данных, байесовский анализ, статистический анализ и т. д.

Эффективность анализа напрямую зависит от его точности. DLP-система, рейтинг которой высок, имеет высокие показатели по данному параметру. Точность идентификации DLP имеет важное значение для избегания ложных срабатываний и негативных последствий. Точность может зависеть от многих факторов, некоторые из которых могут быть ситуативными или технологическими. Тестирование точности может обеспечить надежность работы DLP-системы - практически нулевое количество ложных срабатываний.
Обнаружение и предотвращение утечек информации
Иногда источник распределения данных делает конфиденциальную информацию доступной для третьих лиц. Через некоторое время часть ее, вероятнее всего, обнаружится в несанкционированном месте (например, в интернете или на ноутбуке другого пользователя). DLP-системы, цена которых предоставляется разработчиками по запросу и может составлять от нескольких десятков до нескольких тысяч рублей, должны затем исследовать, как просочились данные - от одного или нескольких третьих лиц, было ли это независимо друг от друга, не обеспечивалась ли утечка какими-то другими средствами и т. д.
Данные в покое
«Данные в состоянии покоя» относятся к старой архивной информации, хранящейся на любом из жестких дисков клиентского ПК, на удаленном файловом сервере, на диске Также это определение относится к данным, хранящимся в системе резервного копирования (на флешках или компакт-дисках). Эти сведения представляют большой интерес для предприятий и государственных учреждений просто потому, что большой объем данных содержится неиспользованным в устройствах памяти, и более вероятно, что доступ к ним может быть получен неуполномоченными лицами за пределами сети.
 Полное обучение работы с wix
Полное обучение работы с wix Лучшие поисковые системы интернета Search создать свою поисковую систему
Лучшие поисковые системы интернета Search создать свою поисковую систему Биржа криптовалют C-Cex: особые черты и принципы работы
Биржа криптовалют C-Cex: особые черты и принципы работы