Что такое ANSI-люмен (лм, lm), единица измерения? Значение. Кодировки: полезная информация и краткая ретроспектива Кодировки: полезная информация и краткая ретроспектива
ANSI это стандарт отображения символов, разработанный American National Standards Institute (код1251). Стандарт ANSI использует только один байт, чтобы представить каждый знак, соответственно ограничен максимумом 256 знаками, в том числе и пунктуации. Коды от 32 до 126 совпадают со стандартом ASCII. Стандарт ASCII (код 688) использовался в DOS, ANSI используется в Windows.
Литература
Архангельский А.Я. Программирование в С++ Builder6. Изд. БИНОМ, 2004.
Архангельский А.Я. С++ Builder6. Справочное пособие. Москва, Изд. БИНОМ, 2004.
Киммел П. BorlandC++5 «BHV-Санкт-Петербург, 2001г.
Климова Л.М. СИ++ Практическое программирование. Решение типовых задач. «КУДИЦ-ОБРАЗ», М.2001.
Культин Н. С/С++ в задачах и примерах. Санкт-Петербург «БХВ-Петербург», 2003.
Павловская Т.А. C/C++ Программирование на языке высокого уровня. Питер, Москва-Санкт-Петербург-… 2005г.
Павловская Т.А., Щупак Ю.А. С++. Объектно-ориентированное программирование. Практикум. СПб., Питер, 2005.
Подбельский В.В. Язык С++ Финансы и статистика, Москва, 2003г.
Поляков А.Ю., Брусенцев В.А. Методы и алгоритмы компьютерной графики в примерах на VisualС++. СПб БХИ-Петербург, 2003г.
Савитч У. Язык С++ курс объектно-ориентированного программирования. Издательский дом Вильямс. Москва-Санкт-Петербург-Киев, 2001г.
Уэллин С. Как не надо программировать на С++. «Питер». Москва-Санкт-Петербург-Нижний Новгород-Воронеж-Новосибирск-Ростов-на-Дону-Екатеринбург-Самара-Киев-Харьков-Минск, 2004.
Шилдт Г. Полный справочник по С++. Изд. Дом «Вильямс» Москва-Санкт-Перербург-Киев, 2003.
Шилдт Г. Самоучитель С/С++ . Санкт-Петербург, «БХВ-Петербург», 2004.
Шилдт Г. Справочник программиста по С/С++ Изд. Дом «Вильямс» Москва-Санкт-Перербург-Киев, 2003.
Шиманович.Л. С/С++ в примерах и задачах. Минск, Новое знание, 2004.
Штерн В. Основы С++. Методы программной инженерии. Изд. Лори.
Почему вместо русских букв в консольном приложении выводится мусор?
и правильно! Текст программы Вы набирали в родном редакторе Visual Studio, используя кодовую страницу 1251, а вывод текста в консольном приложении идет с использованием кодовой страницы 866. Что же делать с этим безобразием? Как известно из любого безвыходного положенния есть по крайней мере 3 выхода. Рассмотрим их по-порядку.
Выход 1
Набрать текст программы в редакторе любого консольного файл-менеджера.
А как же подсветка синтаксиса, вывод по F1 справки по выбранной функции и прочие маленькие прелести, скрашивающие безрадостную жизнь простого программиста? Нет, это выход не для нас.
Выход 2
Если Вы начали писать консольную программу с нуля, он может Вам подойти. Перепишем наш маленький шедевр вот так:
|
#include "stdafx.h" #include "windows.h" int main(int argc, char* argv) char s="Привет всем!"; printf("%s\n", s); |
Ключевое слово здесь CharToOem - именно эта функция и преобразует нашу строку в нужную кодовую страницу. С выводом у нашей программы теперь все нормально.
Но встает следующий вопрос - что делать, если надо перекомпилировать в консольное Windows-приложение Вашу старую DOS-программу на 100000 строк, написанную на Borland C++ 3.1, в которой такая ситуация встречается в каждой второй строке. А ведь придется еще подгонять ее под MS-компилятор, да и пару кусочков кода хочется соптимизировать...
Здесь пожалуй имеет смысл применить ход конем, в смысле
Reg.ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
*Наведите курсор мыши для приостановки прокрутки.
Назад Вперед
Кодировки: полезная информация и краткая ретроспектива
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых кракозябров , т.е. нечитаемых символов.
Итак, поехали...
Что такое кодировка?
Упрощенно говоря, кодировка - это таблица сопоставлений символов, которые мы можем видеть на экране, определенным числовым кодам.
Т.е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов , которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII .
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это однобайтовая кодировка , в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.

Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII символы национальных языков , помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8-R - это тоже расширенная кодировка ASCII , предназначенная для работы с символами русского языка.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок .
По сути это были те же расширенные версии ASCII , однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало "свободных мест".
Примером такой ANSI-кодировки является всем известная Windows-1251 . Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).

ANSI-кодировка - это собирательное название . В действительности, реальная кодировка при использовании ANSI будет определяться тем, что указано в реестре вашей операционной системы Windows. В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
Как вы понимаете, куча кодировок и отсутствие единого стандарта до добра не довели, что и стало причиной частых встреч с так называемыми кракозябрами - нечитаемым бессмысленным набором символов.
Причина их появления проста - это попытка отобразить символы, закодированные с помощью одной кодировочной таблицы, используя другую кодировочную таблицу .
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере .
Разумеется, это не единственный случай, когда мы можем получить нечитаемый текст - вариантов тут масса, особенно, если учесть, что есть еще база данных, в которой информация также хранится в определенной кодировке, есть сопоставление соединения с базой данных и т.д.
Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда .
Юникод - универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc.), и первым результатом его работы стало создание кодировки UTF-32 .
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита , т.е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно в 4 раза больше битов , что "утяжеляет" файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
На смену ей пришла новая разработка - UTF-16 .
Как очевидно из названия, в этой кодировке один символ кодируют уже не 32 бита, а только 16 (т.е. 2 байта). Очевидно, это делает любой символ вдвое "легче", чем в UTF-32, однако и вдвое "тяжелее" любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т.е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, была предпринята еще одна попытка создания чего-то универсального , и этим чем-то стала всем нам известная кодировка UTF-8.
UTF-8 - это многобайтовая кодировка с переменной длинной символа . Глядя на название, можно по аналогии с UTF-32 и UTF-16 подумать, что здесь для кодирования одного символа используется 8 бит, однако это не так. Точнее, не совсем так.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется от 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII . Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет "тратить" на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не "утяжеляя" без необходимости файлы.
C BOM или без BOM?
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++ , phpDesigner , rapid PHP и т.д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
ANSI
- UTF-8
- UTF-8 без BOM

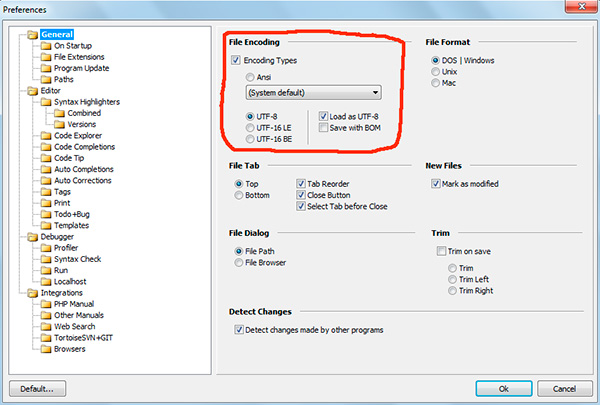

Сразу скажу, что выбирать всегда стоит именно последний вариант - UTF-8 без BOM .
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark . Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM . Для нас главный вывод следующий: использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом , в результате чего возникают ошибки в работе скриптов.
Америка́нский национа́льный институ́т станда́ртов (англ. A merican n ational s tandards i nstitute , ANSI) - объединение американских промышленных и деловых групп, разрабатывающее торговые и коммуникационные стандарты . Входит в организации ISO и IEC , представляя там интересы США .
История
Изначально ANSI была образована в 1918 году, когда пять инженерных обществ и три правительственных учреждения основали «Американский комитет по инженерным стандартам» (AESC - англ. American Engineering Standards Committee ). В 1928 году комитет стал называться "Американской ассоциацией стандартов (ASA - англ. American Standards Association ). В 1966 году ASA была реорганизована и стала «Институтом стандартов Соединенных Штатов Америки» (USASI - англ. United States of America Standards Institute ). Нынешнее название было принято в 1969 году.
До 1918 года существовало пять инженерных обществ, участвовавших в разработке технических стандартов:
- Американский институт инженеров-электриков (American Institute of Electrical Engineers - AIEE, сейчас IEEE)
- Американское общество инженеров-механиков (American Society of Mechanical Engineers - ASME)
- Американское общество гражданских инженеров (American Society of Civil Engineers - ASCE)
- Американский институт горных инженеров (American Institute of Mining Engineers - AIME, в настоящее время Американский институт горных, металлургических и нефтяных инженеров)
- Американское общество по испытаниям и материалам (сейчас ASTM)
В 1916 году Американский институт инженеров-электриков (ныне IEEE) выступил с инициативой объединения усилий этих организаций для создания независимого национального органа для координации разработки стандартов, согласования и утверждения национальных стандартов. Вышеуказанные пять организаций стали основными членами Объединённого инженерного общества (United Engineering Society - UES), впоследствии для участия в нём в качестве учредителей были приглашены военное министерство США, военно-морской флот (объединенный в 1947 году, чтобы стать министерством обороны США) и коммерции .
В 1931 году организация (переименованная в ASA в 1928 году) вошла в состав Национального комитета США в Международной электротехнической комиссии (МЭК) , которая был образован в 1904 году для разработки стандартов в области электротехники и электроники
Члены
Членами ANSI являются государственные органы, организации, академические и международные организации, а также частные лица. В общей сложности Институт представляет интересы более 270 000 компаний и организаций и 30 миллионов специалистов по всему миру /
Деятельность
Хотя сама ANSI не разрабатывает стандарты, Институт осуществляет надзор за разработкой и использованием стандартов путем аккредитации процедур организаций, разрабатывающих стандарты. Аккредитация ANSI означает, что процедуры, используемые организациями, разрабатывающими стандарты, соответствуют требованиям Института в отношении открытости, сбалансированности, консенсуса и надлежащей правовой процедуры.
ANSI также определяет конкретные стандарты как Американские национальные стандарты, или ANS, когда Институт определяет, что стандарты были разработаны в справедливой, доступной и отвечающей требованиям различных заинтересованных сторон среде.
Международная деятельность
Помимо деятельности в области стандартизации в США, ANSI способствует международному использованию стандартов США, отстаивает политическую и техническую позицию США в международных и региональных организациях по стандартизации и поощряет принятие международных стандартов в качестве национальных стандартов.
Институт является официальным представителем США в двух основных международных организациях по стандартизации, Международная организация по стандартизации (ИСО), в качестве одного из основателей, и Международная электротехническая комиссия (IEC) через Национальный комитет США (USNC). ANSI участвует почти во всей технической программе ISO и IEC и управляет многими ключевыми комитетами и подгруппами. Во многих случаях стандарты США передаются в ИСО и МЭК через ANSI или USNC, где они полностью или частично принимаются в качестве международных стандартов.
Принятие стандартов ISO и IEC в качестве американских стандартов возросло с 0,2 % в 1986 году до 15,5 % в мае 2012 года.
Направления стандартизации
Институт управляет девятью группами по стандартизации:
- Сотрудничество по стандартизации национальной безопасности и безопасности ANSI (HDSSC - Homeland Defense and Security Standardization Collaborative)
- Группа по стандартам нанотехнологий ANSI (ANSI-NSP - ANSI Nanotechnology Standards Panel)
- Панель стандартов защиты от кражи ID и ID ID (IDSP - ID Theft Prevention and ID Management Standards Panel)
- ANSI Координационное сотрудничество по стандартизации энергоэффективности (EESCC - Energy Efficiency Standardization Coordination Collaborative)
- Сотрудничество по координации стандартов в области ядерной энергии (NESCC- Nuclear Energy Standards Coordination Collaborative)
- Группа по стандартам электромобилей (EVSP - Electric Vehicles Standards Panel)
- Сеть ANSI-NAM по химическому регулированию (ANSI-NAM Network on Chemical Regulation)
- Координационная группа по стандартам на биотопливо (ANSI Biofuels Standards Coordination Panel)
- Панель стандартов медицинской информации в области здравоохранения (HITSP - Healthcare Information Technology Standards Panel)
- Американское агентство сертификации в области трубопроводов и механизмов
Каждая из групп занимается выявлением, координацией и согласованием добровольных стандартов, относящихся к этим областям. В 2009 году ANSI и (NIST) создали Координационное сотрудничество по стандартам в области ядерной энергии (NESCC). NESCC - это совместная инициатива по выявлению и удовлетворению текущей потребности в стандартах в ядерной отрасли.
Стандарты
Из принятых институтом стандартов известны:
Вопреки распространённому заблуждению, ANSI не принимал стандарты 8-битных кодовых страниц , хотя и участвовал в разработке кодировки ISO-8859-1 и, возможно, некоторых других.
Примечания
- About ANSI
- RFC
- ANSI:Исторический обзор (неопр.) . ansi.org . Дата обращения 31 октября 2016.
- История ANSI
Часто в веб-программировании и вёрстке html-страниц приходится думать о кодировке редактируемого файла — ведь если кодировка выбрана неверная, то есть вероятность, что браузер не сможет автоматически её определить и в результате пользователь увидит т.н. «кракозябры» .
Возможно, вы сами видели на некоторых сайтах вместо нормального текста непонятные символы и знаки вопроса. Всё это возникает тогда, когда кодировка html-страницы и кодировка самого файла этой страницы не совпадают.
Вообще, что такое кодировка текста? Это просто набор символов, по-английски «charset » (character set). Нужна она для того, чтобы текстовую информацию преобразовывать в биты данных и передавать, например, через Интернет.
Собственно, основные параметры, которыми различаются кодировки — это количество байтов и набор спец.символов, в которые преобразуется каждый символ исходного текста.
Краткая история кодировок:
Одной из первых для передачи цифровой информации стало появление кодировки ASCII — American Standard Code for Information Interchange — Американская стандартная кодировочная таблица, принятая Американским национальным институтом стандартов — American National Standards Institute (ANSI) .
В этих аббревиатурах можно запутаться Для практики же важно понимать, что исходная кодировка создаваемых текстовых файлов может не поддерживать все символы некоторых алфавитов (к примеру, иероглифы), потому идёт тенденция к переходу к т.н. стандарту Юникод (Unicode) , который поддерживает универсальные кодировки — Utf-8, Utf-16, Utf-32 и др.
Самая популярная из кодировок Юникода — кодировка Utf-8. Обычно в ней сейчас верстаются страницы сайтов и пишутся разные скрипты. Она позволяет без проблем отображать различные иероглифы, греческие буквы и прочие мыслимые и немыслимые символы (размер символа до 4-х байт). В частности, все файлы WordPress и Joomla пишутся именно в этой кодировке. А также некоторые веб-технологии (в частности, AJAX) способны нормально обрабатывать только символы utf-8.
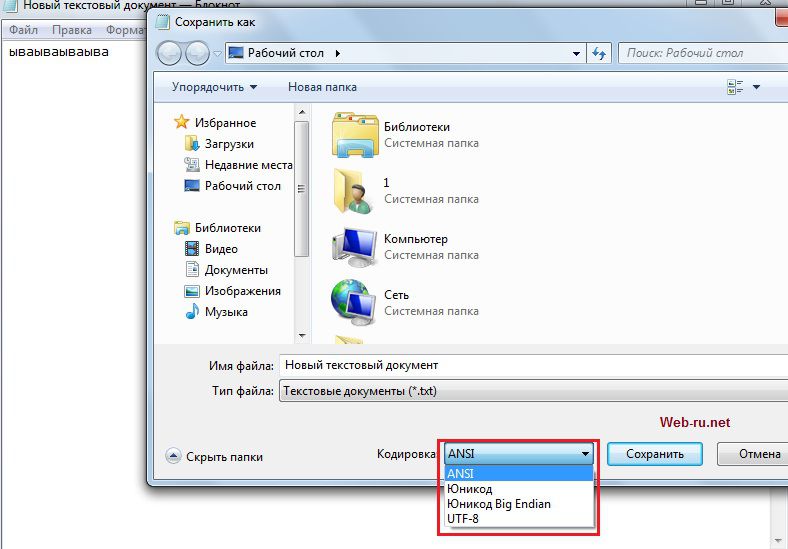
Установка кодировок текстового файла при создании его обычным блокнотом. Кликабельно
В Рунете же ещё можно встретить сайты, написанные с расчётом на кодировку Windows-1251 (или cp-1251). Это специальная кодировка, предназначенная специально для кириллицы.
В основном «ANSI» относится к устаревшей кодовой странице в Windows. См. Также по этой теме. Первые 127 символов идентичны ASCII на большинстве кодовых страниц, однако верхние символы различаются.
Однако ANSI автоматически не означает CP1252 или Latin 1.
Несмотря на всю путаницу, вы должны просто избегать таких проблем в настоящее время и использовать Unicode.
Что такое формат кодировки ANSI? Это системный формат по умолчанию? Чем он отличается от ASCII?
Когда-то Microsoft, как и все остальные, использовала 7-битные наборы символов, и они придумали свои собственные, когда они им подошли, хотя они сохранили ASCII в качестве основного подмножества. Затем они поняли, что мир перешел к 8-битным кодировкам и что существуют международные стандарты, такие как семейство ISO-8859. В те дни, если вы хотели получить международный стандарт, и вы жили в США, вы купили его у Американского национального института стандартов ANSI, который переиздал международные стандарты со своим собственным брендингом и цифрами (это потому, что правительство США хочет соответствие американским стандартам, а не международным стандартам). Итак, копия Microsoft ISO-8859 сказала «ANSI» на обложке. И поскольку Microsoft в те дни не очень привыкла к стандартам, они не понимали, что ANSI опубликовала множество других стандартов. Поэтому они ссылались на стандарты семейства ISO-8859 (и варианты, которые они изобрели, потому что в те дни они не понимали стандартов) по названию на обложке «ANSI», и он нашел свой путь в Microsoft пользовательскую документацию и, следовательно, в сообщество пользователей. Это было около 30 лет назад, но вы все еще иногда слышите это имя сегодня.
Или вы можете запросить свой реестр:
C:\>reg query HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage /f ACP HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage ACP REG_SZ 1252 End of search: 1 match(es) found. C:\>
При использовании однобайтовых символов формат ASCII определяет первые 127 символов. Расширенные символы из 128-255 определяются различными кодами ANSI, чтобы обеспечить ограниченную поддержку других языков. Чтобы понять кодировку ANSI, вам нужно знать, какую кодовую страницу она использует.
Технически ANSI должен быть таким же, как US-ASCII. Он относится к стандарту ANSI X3.4, который является просто утвержденной версией ASCII организации ANSI . Использование символов с верхним битом не определено в ASCII / ANSI, так как это 7-разрядный набор символов.
Однако годы неправильного использования термина DOS и впоследствии сообщества Windows оставили свое практическое значение как «системную кодовую страницу какой бы то ни было машины». Системная кодовая страница также иногда известна как «mbcs», так как в системах Восточной Азии, которая может быть кодировкой с несколькими байтами на символ. Некоторые кодовые страницы могут даже использовать байты с верхним битом в качестве байтов байтов в многобайтовой последовательности, поэтому он даже не является строго совместимым с простым ASCII ... но даже тогда он по-прежнему называется ANSI.
В настройках по умолчанию в США и Западной Европе «ANSI» сопоставляется с кодовой страницей Windows 1252. Это не то же самое, что и ISO-8859-1 (хотя это довольно похоже). На других машинах это могло быть что угодно. Это делает ANSI совершенно бесполезным в качестве внешнего идентификатора кодирования.
Я помню, когда текст ANSI ссылался на escape-коды псевдо-VT-100, используемые в DOS через драйвер ANSI.SYS, чтобы изменить поток потокового текста.... Вероятно, это не то, о чем вы говорите, но если он видит
 Блокчейн – что это понятным языком
Блокчейн – что это понятным языком Технические средства информатизации – аппаратный базис информационных технологий 1 назначение технических средств информации
Технические средства информатизации – аппаратный базис информационных технологий 1 назначение технических средств информации Что делать, если меню «Пуск» не открывается
Что делать, если меню «Пуск» не открывается