Mi az ANSI lumen (lm, lm), mértékegység? Jelentése. Kódolások: hasznos információk és egy rövid visszatekintés Kódolások: hasznos információk és egy rövid visszatekintés
Az ANSI egy karaktermegjelenítési szabvány, amelyet az American National Standards Institute fejlesztett ki (kód: 1251). Az ANSI szabvány csak egy bájtot használ az egyes karakterek megjelenítésére, ezért legfeljebb 256 karakterre korlátozódik, beleértve az írásjeleket is. A 32-től 126-ig terjedő kódok az ASCII szabványt követik. DOS-ban ASCII-t (688-as kód), Windowsban ANSI-t használnak.
Irodalom
Arkhangelsky A.Ya. Programozás C++ Builderben6. Szerk. BINOM, 2004.
Arkhangelsky A.Ya. C++Builder6. Használati útmutató. Moszkva, szerk. BINOM, 2004.
Kimmel P. Borland C++5 "BHV-St. Petersburg, 2001.
Klimova L.M. C++ Gyakorlati programozás. Tipikus feladatok megoldása. "KUDITS-IMAGE", M.2001.
Kultin N. С/С++ feladatokban és példákban. Szentpétervár "BHV-Petersburg", 2003.
Pavlovskaya T.A. C/C++ Programozás magas szintű nyelven. Péter, Moszkva-Szentpétervár-… 2005
Pavlovskaya T.A., Shchupak Yu.A. C++. Objektumorientált programozás. Műhely. SPb., Péter, 2005.
Podbelsky V.V. C++ nyelv Pénzügy és statisztika, Moszkva, 2003.
Polyakov A. Yu., Brusentsev V.A. A számítógépes grafika módszerei és algoritmusai Visual++ példákban. SPb BHI-Pétervár, 2003
Savitch W. C++ nyelvi objektum-orientált programozási tanfolyam. Williams Kiadó. Moszkva-Szentpétervár-Kijev, 2001
Wellin S. Hogyan ne programozzon C++ nyelven. "Péter". Moszkva-Szentpétervár-Nizsnyij Novgorod-Voronyezs-Novoszibirszk-Rosztov-Don-Jekatyerinburg-Szamara-Kijev-Harkov-Minszk, 2004.
Schildt G. A C++ teljes útmutatója. Szerk. "Williams" ház Moszkva-Szentpétervár-Kijev, 2003.
Schildt G. Öntanár C/C++. Szentpétervár, BHV-Petersburg, 2004.
Schildt G. Programozói útmutató a C/C++ nyelvhez Szerk. "Williams" ház Moszkva-Szentpétervár-Kijev, 2003.
Shimanovich.L. С/С++ példákban és feladatokban. Minszk, Új ismeretek, 2004.
Stern V. A C++ alapjai. A szoftverfejlesztés módszerei. Szerk. Lori.
Miért jelenik meg a szemét az orosz betűk helyett a konzolalkalmazásban?
és helyes! A program szövegét a natív Visual Studio szerkesztőben az 1251-es kódlap használatával írta be, a konzolalkalmazás szövegkimenete pedig a 866-os kódlapot használja. Mi a teendő ezzel a szégyennel? Mint tudod, bármely patthelyzetből legalább 3 kijárat van. Tekintsük őket sorrendben.
Kilépés 1
Írja be a program szövegét bármelyik konzolfájlkezelő szerkesztőjébe.
De mi a helyzet a szintaktikai kiemeléssel, az F1 segítségével a kiválasztott funkció súgójának megjelenítésével és más apró varázslatokkal, amelyek feldobják egy egyszerű programozó sivár életét? Nem, ez nem választható számunkra.
Kilépés 2
Ha a nulláról kezdtél el írni egy konzolprogramot, az megfelelhet neked. Írjuk át kis remekművünket így:
|
#include "stdafx.h" #include "windows.h" int main(int argc, char* argv) char s="Szia mindenkinek!"; printf("%s\n", s); |
A kulcsszó itt a CharToOem - ez a függvény konvertálja a karakterláncunkat a kívánt kódlappá. A programunk eredményével most minden rendben van.
De felvetődik a következő kérdés – mit tegyünk, ha a régi, 100 000 soros, Borland C++ 3.1-ben írt DOS programunkat újra kell fordítanunk egy Windows konzolalkalmazásba, amelyben minden második sorban előfordul ilyen helyzet. De még hozzá kell igazítani az MS fordítóhoz, és optimalizálni is akarsz pár kódrészletet...
Itt valószínűleg van értelme a lovag mozdulatát használni, abban az értelemben
Reg.ru: domainek és tárhely
A legnagyobb regisztrátor és tárhelyszolgáltató Oroszországban.
Több mint 2 millió domain név használatban.
Promóció, levelezés domainhez, megoldások üzleti célokra.
Világszerte több mint 700 ezer ügyfél választotta már.
*Vigye az egeret a görgetés szüneteltetéséhez.
Vissza előre
Kódolások: hasznos információk és egy rövid visszatekintés
Úgy döntöttem, hogy ezt a cikket egy kis áttekintésként írom meg a kódolás kérdéséről.
Meg fogjuk érteni, mi a kódolás általában, és megérintjük egy kicsit az elvi megjelenésük történetét.
Szó lesz néhány jellemzőjükről, és figyelembe vesszük azokat a pontokat is, amelyek lehetővé teszik, hogy tudatosabban dolgozzunk a kódolásokkal, és elkerüljük, hogy az oldalon megjelenjenek az ún. krakozyabrov, azaz olvashatatlan karakterek.
Akkor gyerünk...
Mi az a kódolás?
Egyszerűen fogalmazva, kódolás egy táblázat a karakter-leképezésekről, amelyeket a képernyőn láthatunk bizonyos numerikus kódokhoz.
Azok. minden karakter, amelyet a billentyűzetről beírunk, vagy amit a monitor képernyőjén látunk, egy bizonyos bitsorozat (nullák és egyesek) kódolja. A 8 bit, amint azt valószínűleg tudja, 1 bájtnyi információnak felel meg, de erről később.
Maguk a karakterek megjelenését a fontfájlok határozzák meg amelyek telepítve vannak a számítógépére. Ezért a szöveg képernyőn történő megjelenítésének folyamata úgy írható le, mint a nullák és egyesek sorozatainak állandó párosítása bizonyos karakterekkel, amelyek a betűtípus részét képezik.
Minden modern kódolás elődjének tekinthető ASCII.
Ez a rövidítés azt jelenti Amerikai szabványos információcsere kód(Amerikai szabványos kódolási táblázat a nyomtatható karakterekhez és néhány speciális kódhoz).
Ez egybájtos kódolás, amely eredetileg mindössze 128 karaktert tartalmazott: a latin ábécé betűit, arab számokat stb.

Később kibővítették (eleinte nem használta mind a 8 bitet), így lehetővé vált nem 128, hanem 256 (2-től 8-ig) különböző, egy bájt információba kódolható karakter használata.
Ez a fejlesztés lehetővé tette az ASCII hozzáadását nemzeti nyelvek szimbólumai, a már meglévő latin ábécé mellett.
Rengeteg lehetőség van a kiterjesztett ASCII kódolásra, annak köszönhetően, hogy sok nyelv is létezik a világon. Azt hiszem, sokan hallottatok már ilyen kódolásról, mint pl A KOI8-R is egy kiterjesztett ASCII kódolás, amelyet orosz karakterekkel való együttműködésre terveztek.
A kódolások fejlesztésének következő lépésének tekinthető az ún ANSI kódolások.
Lényegében ugyanazok voltak Az ASCII kiterjesztett változatai, azonban eltávolítottak belőlük különféle pszeudografikus elemeket, és nyomdai szimbólumokat adtak hozzá, amelyekhez korábban nem volt elég "szabad hely".
Ilyen ANSI-kódolásra példa a jól ismert Windows-1251. Ez a kódolás a tipográfiai szimbólumokon kívül az oroszhoz közeli nyelvek (ukrán, fehérorosz, szerb, macedón és bolgár) ábécéjének betűit is tartalmazta.

Az ANSI kódolás a gyűjtőneve. A valóságban az ANSI használatakor a tényleges kódolást a Windows operációs rendszer beállításjegyzékében megadottak határozzák meg. Az orosz esetében ez Windows-1251 lesz, más nyelveknél viszont másfajta ANSI.
Mint érti, a sok kódolás és az egységes szabvány hiánya nem hozott jót, ez volt az oka a gyakori találkozásoknak az ún. krakozyabry- olvashatatlan, értelmetlen karakterkészlet.
Megjelenésük oka egyszerű – az próbálja meg megjeleníteni az egyik kódolási táblával kódolt karaktereket egy másik kódolási tábla használatával.
A webfejlesztés kapcsán hibákkal találkozhatunk, amikor pl. Az orosz szöveget a rendszer tévedésből a szerveren használt rossz kódolással menti.
Természetesen nem ez az egyetlen eset, amikor olvashatatlan szöveget kaphatunk - itt rengeteg lehetőség van, főleg, ha figyelembe vesszük, hogy van olyan adatbázis is, amiben bizonyos kódolásban is tárolódnak az információk, van adatbázis kapcsolat térképezés stb.
Mindezen problémák felbukkanása ösztönzőként szolgált valami új létrehozására. Egy olyan kódolásnak kellett volna lennie, amely a világ bármely nyelvét képes kódolni (végül is, az egybájtos kódolások segítségével, minden vágy mellett lehetetlen leírni mondjuk a kínai nyelv összes karakterét, ahol egyértelműen több mint 256), további speciális karakterek és tipográfia.
Egyszóval alkotni kellett egy univerzális kódolás, amely egyszer s mindenkorra megoldja a hibák problémáját.
Unicode – univerzális szövegkódolás (UTF-32, UTF-16 és UTF-8)
Magát a szabványt 1991-ben egy nonprofit szervezet javasolta "Unicode konzorcium"(Unicode Consortium, Unicode Inc.), és munkája első eredménye egy kódolás megalkotása volt. UTF-32.
Mellesleg a rövidítés UTF jelentése Unicode transzformációs formátum(Unicode konverziós formátum).
Ebben a kódolásban egy karakter kódolásához annyit kellett volna használnia, mint 32 bites, azaz 4 bájtnyi információ. Ha összehasonlítjuk ezt a számot az egybájtos kódolásokkal, akkor egyszerű következtetésre jutunk: 1 karakter kódolásához ebben az univerzális kódolásban kell 4-szer több bit, amely 4-szer "súlyozza" a fájlt.
Az is nyilvánvaló, hogy az ezzel a kódolással potenciálisan leírható karakterek száma túllép minden ésszerű határt, és technikailag 2-vel egyenlő számra korlátozódik 32 hatványával. Nyilvánvaló, hogy ez egyértelmű túlzás és pazarlás volt a fájlok súlyát tekintve, ezért ezt a kódolást nem alkalmazták széles körben.
Felváltotta egy új fejlesztés - UTF-16.
Ahogy a név is sugallja, ebben a kódolásban egy karakter van kódolva már nem 32 bites, hanem csak 16(azaz 2 bájt). Nyilvánvalóan ettől bármely karakter kétszer "könnyebb" lesz, mint az UTF-32-ben, de kétszer "nehezebb" is, mint bármely, egybájtos kódolással kódolt karakter.
Az UTF-16 kódoláshoz rendelkezésre álló karakterek száma legalább 2 16 hatványig, azaz. 65536 karakter. Úgy tűnik, minden rendben van, ráadásul az UTF-16 kódterületének végleges mérete több mint 1 millió karakterre bővült.
Ez a kódolás azonban nem elégítette ki teljesen a fejlesztők igényeit. Tegyük fel, hogy ha kizárólag latin karakterekkel írunk, akkor az ASCII kódolás kiterjesztett verziójáról UTF-16-ra váltás után az egyes fájlok súlya megduplázódott.
Ennek eredményeként újabb kísérlet történt valami univerzális létrehozására, és ez a valami a jól ismert UTF-8 kódolás lett.
UTF-8- ezt többbyte-os karakterkódolás változó karakterhosszúsággal. Ha a nevet nézzük, az UTF-32 és UTF-16 analógiájára azt gondolhatnánk, hogy egy karakter kódolására 8 bitet használnak, de ez nem így van. Pontosabban nem egészen így.
Ennek az az oka, hogy az UTF-8 biztosítja a legjobb kompatibilitást a régebbi, 8 bites karaktereket használó rendszerekkel. Valójában egyetlen karakter UTF-8 kódolása használatos 1-4 bájt(hipotetikusan 6 bájtig lehetséges).
Az UTF-8-ban minden latin karakter 8 bittel van kódolva, akárcsak az ASCII kódolásnál.. Vagyis az ASCII kódolás alap része (128 karakter) átkerült az UTF-8-ra, amivel csak 1 bájtot lehet "költeni" az ábrázolásukra, miközben megőrzi a kódolás univerzalitását, amiért minden elkezdődött.
Tehát, ha az első 128 karakter 1 bájttal van kódolva, akkor az összes többi karakter már 2 vagy több bájttal van kódolva. Különösen minden cirill karakter pontosan 2 bájttal van kódolva.
Így egy univerzális kódolást kaptunk, amely lehetővé teszi, hogy minden lehetséges karaktert lefedjünk, amit szükségtelenül "nehezebb" fájlok nélkül kell megjeleníteni.
BOM-mal vagy darabjegyzék nélkül?
Ha szövegszerkesztőkkel (kódszerkesztőkkel) dolgozott, mint pl Jegyzettömb++, phpDesigner, gyors PHP stb., valószínűleg figyelt arra, hogy az oldal létrehozásának kódolásának beállításakor általában 3 lehetőséget választhat:
ANSI
-UTF-8
- UTF-8 anyagjegyzék nélkül

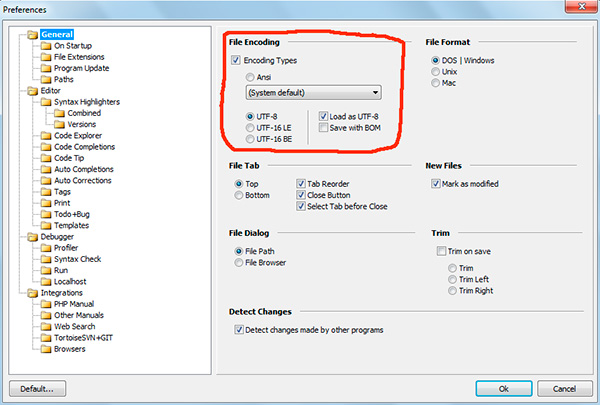

Azonnal meg kell mondanom, hogy mindig érdemes az utolsó lehetőséget választani - UTF-8 anyagjegyzék nélkül.
Tehát mi az a BOM, és miért nincs rá szükségünk?
BOM jelentése Byte Order Mark. Ez egy speciális Unicode karakter, amely a szöveges fájl bájtsorrendjét jelzi. A specifikáció szerint használata nem kötelező, de ha BOM használatban van, akkor a szövegfájl elején kell beállítani.
A munka részleteibe nem térünk ki BOM. Számunkra a fő következtetés a következő: ennek a szolgáltatáskarakternek az UTF-8-cal együtt történő használata megakadályozza, hogy a programok normálisan beolvassák a kódolást, ami szkripthibákat eredményez.
Amerikai Nemzeti Szabványügyi Intézet(Angol) A merikán n nemzeti s tandardok én intézet, ANSI) amerikai ipari és üzleti csoportok szövetsége, amely kereskedelmi és kommunikációs szabványokat fejleszt. Tagja az ISO-nak és az IEC-nek, ahol az Egyesült Államok érdekeit képviseli.
Történelem
Az ANSI eredetileg 1918-ban alakult, amikor öt mérnöki társaság és három kormányzati ügynökség megalapította az „Amerikai Mérnöki Szabványok Bizottságát” (American Engineering Standards Committee). AESC- Angol. Amerikai Mérnöki Szabványok Bizottsága). 1928-ban a bizottság Amerikai Szabványügyi Szövetség néven vált. MINT A- Angol. Amerikai Szabványügyi Szövetség). 1966-ban az ASA-t átszervezték, és az "Amerikai Egyesült Államok Standard Intézete" lett. USASI- Angol. Amerikai Egyesült Államok Szabványügyi Intézete). A jelenlegi nevet 1969-ben vették fel.
1918-ig öt mérnöki társaság vett részt a műszaki szabványok kidolgozásában:
- American Institute of Electrical Engineers (AIEE, most IEEE)
- Amerikai Gépészmérnökök Társasága (ASME)
- Amerikai Építőmérnökök Társasága (ASCE)
- American Institute of Mining Engineers (AIME, jelenleg az American Institute of Mining, Metallurgical and Petroleum Engineers)
- American Society for Testing and Materials (jelenleg ASTM)
1916-ban az American Institute of Electrical Engineers (jelenleg IEEE) kezdeményezte, hogy e szervezetek erőfeszítéseit egyesítsék egy független nemzeti testület létrehozására, amely koordinálja a szabványok kidolgozását, a nemzeti szabványok harmonizációját és jóváhagyását. A fenti öt szervezet lett a United Engineering Society (United Engineering Society – UES) fő tagja, majd az Egyesült Államok Hadügyminisztériuma, a Haditengerészet (1947-ben egyesült az Egyesült Államok Védelmi Minisztériumává) és a Kereskedelmi meghívást kapott alapítóként.
1931-ben a szervezet (1928-ban ASA néven átkeresztelve) a Nemzetközi Elektrotechnikai Bizottság (IEC) amerikai nemzeti bizottságának része lett, amelyet 1904-ben hoztak létre az elektromos és elektronikai mérnöki szabványok kidolgozására.
tagok
Az ANSI tagjai közé tartoznak a kormányzati szervek, szervezetek, tudományos és nemzetközi szervezetek, valamint magánszemélyek. Az Intézet összesen több mint 270 000 vállalat és szervezet, valamint 30 millió szakember érdekeit képviseli világszerte /
Tevékenység
Bár maga az ANSI nem dolgoz ki szabványokat, az Intézet felügyeli a szabványok kidolgozását és használatát a szabványfejlesztő szervezetek eljárásainak akkreditációja révén. Az ANSI akkreditáció azt jelenti, hogy a szabványfejlesztő szervezetek által alkalmazott eljárások megfelelnek az Intézet nyitottságra, egyensúlyra, konszenzusra és szabályszerű eljárásra vonatkozó követelményeinek.
Az ANSI bizonyos szabványokat amerikai nemzeti szabványnak vagy ANS-nek is jelöl, ha az Intézet megállapítja, hogy a szabványokat olyan környezetben dolgozták ki, amely méltányos, hozzáférhető és reagál a különböző érdekelt felek igényeire.
Nemzetközi tevékenység
Az Egyesült Államok szabványosítási tevékenysége mellett az ANSI támogatja az amerikai szabványok nemzetközi használatát, támogatja az Egyesült Államok politikai és technikai pozícióját a nemzetközi és regionális szabványügyi szervezetekben, és ösztönzi a nemzetközi szabványok nemzeti szabványként való elfogadását.
Az Intézet az Egyesült Államok hivatalos képviselője két nagy nemzetközi szabványügyi szervezetben, a Nemzetközi Szabványügyi Szervezetben (ISO) alapító tagként, valamint a Nemzetközi Elektrotechnikai Bizottságban (IEC) az Egyesült Államok Nemzeti Bizottságán (USNC) keresztül. Az ANSI részt vesz az ISO és az IEC szinte teljes műszaki programjában, és számos kulcsfontosságú bizottságot és alcsoportot irányít. Az amerikai szabványokat sok esetben ANSI-n vagy USNC-n keresztül nyújtják be az ISO-nak és az IEC-nek, ahol azokat részben vagy egészben elfogadják nemzetközi szabványként.
Az ISO és IEC szabványok amerikai szabványként való elfogadása az 1986-os 0,2%-ról 2012 májusára 15,5%-ra nőtt.
A szabványosítás irányai
Az Intézet kilenc szabványosítási csoportot kezel:
- ANSI Honvédelmi és Biztonsági Szabványügyi Együttműködés (HDSSC)
- ANSI Nanotechnology Standards Panel (ANSI-NSP – ANSI Nanotechnology Standards Panel)
- Azonosítólopás-megelőzési és azonosítókezelési szabványok panelje (IDSP – Azonosítólopás-megelőzési és azonosítókezelési szabványok panelje)
- ANSI Energiahatékonysági Szabványosítási Koordinációs Együttműködés (EESCC)
- Nukleáris Energia Szabványok Koordinációs Együttműködése (NESCC-Nuclear Energy Coordination Collaborative)
- Elektromos járművek szabványügyi panel (EVSP)
- ANSI-NAM kémiai szabályozási hálózat
- ANSI Bioüzemanyag-szabványok Koordinációs Panel
- Egészségügyi Információs Technológiai Szabványok Panel (HITSP)
- Amerikai Csővezetékek és Gépek Tanúsító Ügynöksége
Mindegyik csoport az e területekhez kapcsolódó önkéntes szabványok meghatározásával, koordinálásával és harmonizálásával foglalkozik. 2009-ben az ANSI és (NIST) megalakították a Nukleáris Energia Szabványok Koordináló Együttműködését (NESCC). A NESCC egy együttműködési kezdeményezés a nukleáris iparban meglévő szabványok iránti jelenlegi igények azonosítására és kielégítésére.
Szabványok
Az intézet által elfogadott szabványok közül a következők ismertek:
A közkeletű tévhitekkel ellentétben az ANSI nem vette át a 8 bites kódlapszabványokat, bár részt vett az ISO-8859-1 kódolás és esetleg még néhány más fejlesztésében.
Megjegyzések
- Az ANSI-ról
- RFC
- ANSI: Történelmi áttekintés (határozatlan) . ansi.org. Letöltve: 2016. október 31.
- Az ANSI története
A webes programozásnál és a html oldalak elrendezésénél gyakran gondolni kell a szerkesztett fájl kódolására – elvégre ha rosszul van kiválasztva a kódolás, akkor fennáll annak az esélye, hogy a böngésző nem tudja automatikusan meghatározni, és pl. ennek eredményeként a felhasználó látni fogja az ún. "Krakozyabry".
Talán Ön is látott néhány webhelyen furcsa szimbólumokat és kérdőjeleket a normál szövegek helyett. Mindez akkor fordul elő, ha a html oldal kódolása és magának az oldalnak a kódolása nem egyezik.
Egyáltalán, mi az a szövegkódolás? Ez csak egy karakterkészlet, angolul "karakterkészlet" (karakterkészlet). A szöveges információk adatbitekké alakításához és például az interneten keresztül történő továbbításához szükséges.
Valójában a kódolásokat megkülönböztető fő paraméterek a bájtok száma és a speciális karakterek halmaza, amelyekre a forrásszöveg minden karakterét átalakítják.
A kódolások rövid története:
Az elsők között, amely digitális információt továbbított, az ASCII kódolás megjelenése volt. Amerikai szabványos információcsere kód – amerikai szabvány kódtábla, az Amerikai Nemzeti Szabványügyi Intézet által elfogadott - Amerikai Nemzeti Szabványügyi Intézet (ANSI).
Ezek a rövidítések zavaróak lehetnek. A gyakorlat szempontjából fontos megérteni, hogy a létrehozott szövegfájlok kezdeti kódolása nem feltétlenül támogatja egyes ábécék (például hieroglifák) összes karakterét, ezért hajlamos az ún. hívott. alapértelmezett Unicode (Unicode), amely támogatja az univerzális kódolásokat − utf-8, utf-16, utf-32 satöbbi.
A legnépszerűbb Unicode kódolás az Utf-8. Általában a webhely oldalait most beírják, és különféle szkripteket írnak. Lehetővé teszi a különféle hieroglifák, görög betűk és egyéb elképzelhető és elképzelhetetlen karakterek (karakterméret akár 4 bájt) egyszerű megjelenítését. Különösen az összes WordPress és Joomla fájl ebben a kódolásban van írva. És néhány webes technológia (különösen az AJAX) csak az utf-8 karakterek normál feldolgozására képes.
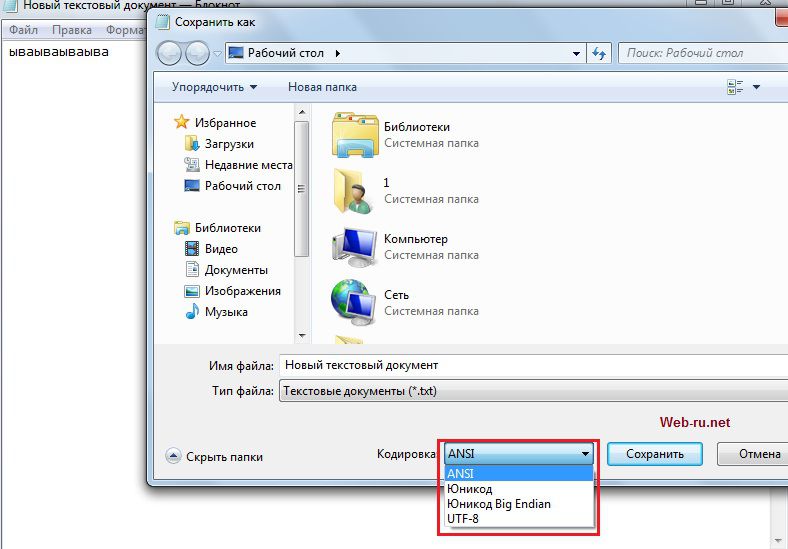
Állítsa be a szöveges fájl kódolását, ha normál jegyzettömbbel hoz létre. Kattintható
A Runetben továbbra is találhat olyan webhelyeket, amelyek a kódolás elvárásainak megfelelően készültek Windows-1251 (vagy cp-1251). Ez egy speciális kódolás, amelyet kifejezetten cirill betűhöz terveztek.
Alapvetően az „ANSI” a Windows örökölt kódlapjára utal. Lásd még ebben a témában. Az első 127 karakter megegyezik az ASCII karakterével a legtöbb kódlapon, azonban a felső karakterek eltérőek.
Az ANSI azonban automatikusan nem a CP1252 vagy a latin 1 rövidítése.
A zűrzavar ellenére egyelőre csak kerülje el az ilyen problémákat, és használja a Unicode-ot.
Mi az ANSI kódolási formátum? Ez az alapértelmezett rendszerformátum? Miben különbözik az ASCII-től?
Egy időben a Microsoft, mint mindenki más, 7 bites karakterkészleteket használt, és akkor találták ki a sajátjukat, amikor nekik megfelelt, bár az ASCII-t tartották a fő részhalmaznak. Aztán rájöttek, hogy a világ átállt a 8 bites kódolásra, és léteznek olyan nemzetközi szabványok, mint az ISO-8859 család. Abban az időben, ha nemzetközi szabványt akart, és az Egyesült Államokban élt, akkor az American National Standards Institute ANSI-tól vásárolta meg, amely újra kiadta a nemzetközi szabványokat saját márkajelzéssel és számokkal (ez azért van, mert az Egyesült Államok kormánya amerikai szabványokat akar, és nem nemzetközi szabványok). Tehát a Microsoft ISO-8859-es példányán az „ANSI” felirat állt a borítón. És mivel a Microsoft akkoriban nem nagyon volt hozzászokva a szabványokhoz, nem vették észre, hogy az ANSI sok más szabványt is közzétett. Így hát az ISO-8859 szabványcsaládra (és az általuk kitalált változatokra, mert akkoriban nem értették a szabványokat) az „ANSI” borítócímmel hivatkoztak, és bekerült a Microsoft felhasználói dokumentációjába, így a közösségbe. felhasználók. Ez körülbelül 30 évvel ezelőtt történt, de még ma is hallod ezt a nevet.
Vagy lekérdezheti a rendszerleíró adatbázisát:
C:\>reg lekérdezés HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage /f ACP HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage ACP REG_SZ)1 találat: 1251 találat. C:\>
Egybájtos karakterek használatakor az ASCII formátum határozza meg az első 127 karaktert. A 128-tól 255-ig terjedő kiterjesztett karaktereket különböző ANSI-kódok határozzák meg, hogy korlátozott támogatást nyújtsanak más nyelvekhez. Az ANSI kódolás megértéséhez tudnia kell, hogy milyen kódlapot használ.
Technikailag az ANSI-nek meg kell egyeznie az US-ASCII-vel. Az ANSI X3.4 szabványra utal, amely egyszerűen az ANSI szervezet által jóváhagyott ASCII-verzió. A felső bites karakterek használata nincs meghatározva az ASCII/ANSI-ban, mivel ez egy 7 bites karakterkészlet.
Azonban a kifejezéssel éveken át a DOS, majd a Windows közösség általi visszaélése miatt a gyakorlati jelentésük „bármely gép rendszerkódlapja” maradt. A rendszer kódlapját néha "mbcs"-nek is nevezik, mint a kelet-ázsiai rendszerekben, amely lehet karakterenként több bájtot tartalmazó kódolás. Egyes kódlapok még a felső bit bájtjait is használhatják bájtként többbájtos sorozatban, így még csak nem is kompatibilis a sima ASCII-vel... de még akkor is ANSI-nak hívják.
Az Egyesült Államok és Nyugat-Európa alapértelmezett beállításaiban az "ANSI" a Windows 1252-es kódlapjára vonatkozik. Ez nem ugyanaz, mint az ISO-8859-1 (bár eléggé hasonló). Más gépeken bármi lehet. Ez teljesen használhatatlanná teszi az ANSI-t külső kódolási azonosítóként.
Emlékszem, amikor az ANSI szöveg a DOS-ban az ANSI.SYS illesztőprogramon keresztül használt pszeudo-VT-100 escape kódokra utalt az adatfolyam szövegfolyamának megváltoztatására... Valószínűleg nem az, amiről beszélsz, de ha látja
 Mit mondanak a lap elfogyott memória hibák?
Mit mondanak a lap elfogyott memória hibák? Szinkron és aszinkron I/O Aszinkron I/O
Szinkron és aszinkron I/O Aszinkron I/O Véges állapotú gépek, hogyan kell programozni rontás nélkül
Véges állapotú gépek, hogyan kell programozni rontás nélkül