Ce este lumenul ANSI (lm, lm), unitatea de măsură? Sens. Codificări: informații utile și o scurtă retrospectivă Codificări: informații utile și o scurtă retrospectivă
ANSI este un standard de afișare a caracterelor dezvoltat de Institutul Național American de Standarde (cod 1251). Standardul ANSI folosește doar un octet pentru a reprezenta fiecare caracter și, prin urmare, este limitat la maximum 256 de caractere, inclusiv punctuația. Codurile de la 32 la 126 urmează standardul ASCII. ASCII (cod 688) a fost folosit în DOS, ANSI este folosit în Windows.
Literatură
Arkhangelsky A.Ya. Programare în C++ Builder6. Ed. BIOM, 2004.
Arkhangelsky A.Ya. C++Builder6. Manual de referință. Moscova, Ed. BIOM, 2004.
Kimmel P. Borland C++5 „BHV-Sankt Petersburg, 2001.
Klimova L.M. C++ Programare practică. Rezolvarea sarcinilor tipice. „KUDITS-IMAGE”, M.2001.
Kultin N. С/С++ în sarcini și exemple. Sankt Petersburg „BHV-Petersburg”, 2003.
Pavlovskaya T.A. Programare C/C++ într-un limbaj de nivel înalt. Peter, Moscova-Sankt Petersburg-... 2005
Pavlovskaya T.A., Shchupak Yu.A. C++. Programare orientată pe obiecte. Atelier. SPb., Peter, 2005.
Podbelsky V.V. Limbajul C++ Finanțe și statistică, Moscova, 2003.
Polyakov A.Yu., Brusentsev V.A. Metode și algoritmi de grafică pe computer în exemple Visual++. SPb BHI-Petersburg, 2003
Savitch W. Limbaj C++ curs de programare orientată pe obiecte. Editura Williams. Moscova-Sankt Petersburg-Kiev, 2001
Wellin S. Cum să nu programezi în C++. "Petru". Moscova-Sankt Petersburg-Nijni Novgorod-Voronezh-Novosibirsk-Rostov-pe-Don-Ekaterinburg-Samara-Kiev-Harkov-Minsk, 2004.
Schildt G. Ghidul complet pentru C++. Ed. Casa „Williams” Moscova-Sankt Petersburg-Kiev, 2003.
Schildt G. Autotutor C/C++. Sankt Petersburg, BHV-Petersburg, 2004.
Schildt G. Ghidul programatorului pentru C/C++ Ed. Casa „Williams” Moscova-Sankt Petersburg-Kiev, 2003.
Shimanovici.L. С/С++ în exemple și sarcini. Minsk, Cunoștințe noi, 2004.
Stern V. Fundamentele C++. Metode de inginerie software. Ed. Lori.
De ce este afișat gunoiul în loc de litere rusești în aplicația de consolă?
si corect! Ați introdus textul programului în editorul nativ Visual Studio folosind pagina de cod 1251, iar rezultatul textului din aplicația consolă folosește pagina de cod 866. Ce să faceți cu această rușine? După cum știți, din orice impas există cel puțin 3 ieșiri. Să le considerăm în ordine.
Ieșirea 1
Tastați textul programului în editorul oricărui manager de fișiere din consolă.
Dar cum rămâne cu evidențierea sintaxei, afișarea ajutorului pentru funcția selectată folosind F1 și alte mici farmece care luminează viața sumbră a unui programator simplu? Nu, aceasta nu este o opțiune pentru noi.
Ieșirea 2
Dacă ați început să scrieți un program de consolă de la zero, s-ar putea să vi se potrivească. Să rescriem mica noastră capodopera astfel:
|
#include „stdafx.h” #include „windows.h” int main(int argc, char* argv) char s="Bună ziua tuturor!"; printf("%s\n", s); |
Cuvântul cheie aici este CharToOem - această funcție va converti șirul nostru în pagina de coduri dorită. Cu rezultatul programului nostru, totul este bine acum.
Dar apare următoarea întrebare - ce să faceți dacă trebuie să recompilați vechiul program DOS de 100.000 de linii scris în Borland C++ 3.1 într-o aplicație de consolă Windows, în care o astfel de situație apare în fiecare a doua linie. Dar tot trebuie să-l adaptezi la compilatorul MS și, de asemenea, vrei să optimizezi câteva bucăți de cod...
Aici probabil că are sens să folosești mișcarea cavalerului, în sensul respectiv
Reg.ru: domenii si gazduire
Cel mai mare furnizor de înregistrare și găzduire din Rusia.
Peste 2 milioane de nume de domenii în serviciu.
Promovare, mail pentru domeniu, solutii pentru afaceri.
Peste 700 de mii de clienți din întreaga lume și-au făcut deja alegerea.
* Treceți cu mouse-ul pentru a întrerupe derularea.
Inapoi inainte
Codificări: informații utile și o scurtă retrospectivă
Am decis să scriu acest articol ca o mică recenzie despre problema codificărilor.
Vom înțelege ce este codificarea în general și vom atinge puțin istoria modului în care au apărut în principiu.
Vom vorbi despre unele dintre caracteristicile lor și vom lua în considerare, de asemenea, punctele care ne permit să lucrăm cu codificări mai conștient și să evităm așa-numitele krakozyabrov, adică caractere imposibil de citit.
Deci să mergem...
Ce este o codificare?
Pur și simplu pune, codificare este un tabel de mapări de caractere pe care le putem vedea pe ecran, la anumite coduri numerice.
Acestea. fiecare caracter pe care îl introducem de la tastatură, sau îl vedem pe ecranul monitorului, este codificat de o anumită secvență de biți (zerouri și uni). 8 biți, după cum probabil știți, sunt egali cu 1 octet de informații, dar mai multe despre asta mai târziu.
Aspectul caracterelor în sine este determinat de fișierele cu fonturi care sunt instalate pe computerul dvs. Prin urmare, procesul de afișare a textului pe ecran poate fi descris ca o mapare constantă a secvențelor de zerouri și unu la unele caractere specifice care fac parte din font.
Progenitorul tuturor codificărilor moderne poate fi considerat ASCII.
Această abreviere reprezintă Codul American Standard pentru Schimbul de Informații(Tabel de codificare standard american pentru caractere imprimabile și unele coduri speciale).
Acest codificare pe un singur octet, care conținea inițial doar 128 de caractere: litere ale alfabetului latin, cifre arabe etc.

Ulterior a fost extins (inițial nu a folosit toți cei 8 biți), așa că a devenit posibil să se utilizeze nu 128, ci 256 (2 până la 8) caractere diferite care pot fi codificate într-un octet de informații.
Această îmbunătățire a făcut posibilă adăugarea la ASCII simboluri ale limbilor naționale, pe lângă alfabetul latin deja existent.
Există o mulțime de opțiuni pentru codificarea ASCII extinsă, datorită faptului că există și o mulțime de limbi în lume. Cred că mulți dintre voi ați auzit de o astfel de codificare ca KOI8-R este, de asemenea, o codificare ASCII extinsă, conceput pentru a funcționa cu caractere rusești.
Următorul pas în dezvoltarea codificărilor poate fi considerat apariția așa-numitului codificări ANSI.
În esență, erau la fel versiuni extinse de ASCII, din ele au fost însă eliminate diverse elemente pseudografice și au fost adăugate simboluri tipografice, pentru care anterior nu existau suficiente „spații libere”.
Un exemplu de astfel de codificare ANSI este binecunoscutul Windows-1251. Pe lângă simbolurile tipografice, această codificare includea și litere din alfabetele limbilor apropiate rusă (ucraineană, belarusă, sârbă, macedoneană și bulgară).

Codarea ANSI este numele colectiv pentru. În realitate, codificarea reală atunci când utilizați ANSI va fi determinată de ceea ce este specificat în registrul sistemului dumneavoastră de operare Windows. În cazul limbii ruse, acesta va fi Windows-1251, cu toate acestea, pentru alte limbi, va fi un alt fel de ANSI.
După cum înțelegeți, o grămadă de codificări și lipsa unui singur standard nu au adus la bine, ceea ce a fost motivul întâlnirilor frecvente cu așa-numitul krakozyabry- un set de caractere necitit și fără sens.
Motivul pentru apariția lor este simplu - este încercați să afișați caractere codificate cu un tabel de codificare folosind un alt tabel de codare.
În contextul dezvoltării web, putem întâlni erori atunci când, de exemplu, Textul rusesc este salvat din greșeală într-o codificare greșită folosită pe server.
Bineînțeles, acesta nu este singurul caz în care putem obține text ilizibil - există o mulțime de opțiuni aici, mai ales când iei în considerare că există și o bază de date în care informațiile sunt stocate și într-o anumită codificare, există o conexiune de bază de date cartografiere etc.
Apariția tuturor acestor probleme a servit ca un stimulent pentru a crea ceva nou. Trebuia să fie o codificare care ar putea codifica orice limbă din lume (la urma urmei, cu ajutorul codificărilor pe un singur octet, cu toată dorința, este imposibil să descriem toate caracterele, să zicem, ale limbii chineze, unde sunt în mod clar mai mult de 256), orice caractere speciale suplimentare și tipografie.
Într-un cuvânt, a fost necesar să se creeze o codificare universală care ar rezolva problema erorilor o dată pentru totdeauna.
Unicode - codificare universală a textului (UTF-32, UTF-16 și UTF-8)
Standardul în sine a fost propus în 1991 de o organizație non-profit „Consorțiul Unicode”(Unicode Consortium, Unicode Inc.), iar primul rezultat al muncii sale a fost crearea unei codificări UTF-32.
De altfel, abrevierea UTF reprezintă Format de transformare Unicode(Format de conversie Unicode).
În această codificare, pentru a codifica un caracter, trebuia să folosească cât mai multe 32 de biți, adică 4 octeți de informații. Dacă comparăm acest număr cu codificări pe un singur octet, atunci vom ajunge la o concluzie simplă: pentru a codifica 1 caracter în această codificare universală, trebuie De 4 ori mai mulți biți, care „cântărește” fișierul de 4 ori.
De asemenea, este evident că numărul de caractere care ar putea fi descrise folosind această codificare depășește toate limitele rezonabile și este limitat din punct de vedere tehnic la un număr egal cu 2 la puterea lui 32. Este clar că aceasta a fost o exagerare clară și o risipă în ceea ce privește greutatea fișierelor, așa că această codificare nu a fost utilizată pe scară largă.
A fost înlocuit cu o nouă dezvoltare - UTF-16.
După cum sugerează și numele, în această codificare este codificat un caracter nu mai este 32 de biți, ci doar 16(adică 2 octeți). Evident, acest lucru face ca orice caracter să fie de două ori mai „ușor” decât în UTF-32, dar și de două ori mai „greu” decât orice caracter codificat folosind o codificare pe un singur octet.
Numărul de caractere disponibile pentru codificare în UTF-16 este de cel puțin 2 la puterea lui 16, adică 65536 caractere. Totul pare să fie bine, în plus, valoarea finală a spațiului de cod în UTF-16 a fost extinsă la mai mult de 1 milion de caractere.
Cu toate acestea, această codificare nu a satisfăcut pe deplin nevoile dezvoltatorilor. Să presupunem că dacă scrieți folosind exclusiv caractere latine, atunci după trecerea de la versiunea extinsă a codificării ASCII la UTF-16, greutatea fiecărui fișier s-a dublat.
Ca rezultat, s-a făcut o altă încercare de a crea ceva universal, iar acest lucru a devenit binecunoscuta codificare UTF-8.
UTF-8- acest codificare de caractere multiocteți cu lungime variabilă a caracterelor. Privind numele, ați putea crede, prin analogie cu UTF-32 și UTF-16, că 8 biți sunt folosiți pentru a codifica un caracter, dar nu este așa. Mai precis, nu chiar așa.
Acest lucru se datorează faptului că UTF-8 oferă cea mai bună compatibilitate cu sisteme mai vechi care foloseau caractere pe 8 biți. Pentru a codifica un singur caracter în UTF-8 este de fapt folosit 1 până la 4 octeți(ipotetic posibil până la 6 octeți).
În UTF-8, toate caracterele latine sunt codificate cu 8 biți, la fel ca în codificarea ASCII.. Cu alte cuvinte, partea de bază a codificării ASCII (128 de caractere) s-a mutat în UTF-8, ceea ce vă permite să „cheltuiți” doar 1 octet pe reprezentarea lor, păstrând în același timp universalitatea codificării, pentru care totul a fost început.
Deci, dacă primele 128 de caractere sunt codificate cu 1 octet, atunci toate celelalte caractere sunt deja codificate cu 2 octeți sau mai mult. În special, fiecare caracter chirilic este codificat cu exact 2 octeți.
Astfel, am obținut o codificare universală care ne permite să acoperim toate caracterele posibile care trebuie afișate fără fișiere „mai grele” în mod inutil.
Cu BOM sau fără BOM?
Dacă ați lucrat cu editori de text (editoare de cod) precum Notepad++, phpDesigner, PHP rapid etc., atunci probabil că au acordat atenție faptului că atunci când setați codificarea în care va fi creată pagina, puteți alege de obicei 3 opțiuni:
ANSI
-UTF-8
- UTF-8 fără BOM

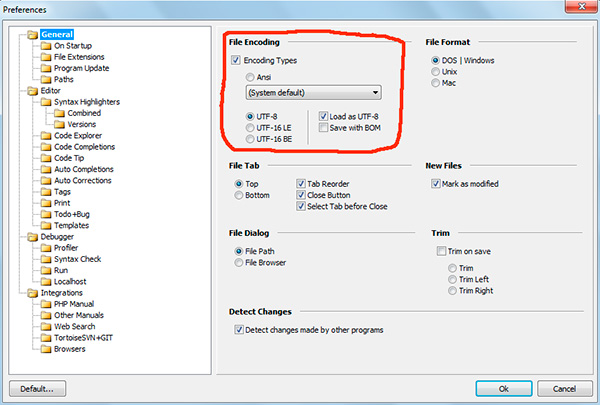

Trebuie să spun imediat că întotdeauna merită să alegeți ultima opțiune - UTF-8 fără BOM.
Deci, ce este BOM și de ce nu avem nevoie de el?
BOM reprezintă Marca de ordine a octetilor. Acesta este un caracter Unicode special folosit pentru a indica ordinea octeților unui fișier text. Conform caietului de sarcini, utilizarea sa este opțională, dar dacă BOM este utilizat, trebuie setat la începutul fișierului text.
Nu vom intra în detaliile lucrării BOM. Pentru noi, concluzia principală este următoarea: utilizarea acestui caracter de serviciu împreună cu UTF-8 împiedică programele să citească codificarea în mod normal, rezultând erori de script.
Institutul Național American de Standarde(Engleză) A american n ational s standardele i institut, ANSI) este o asociație a grupurilor industriale și de afaceri americane care dezvoltă standarde comerciale și de comunicare. Este membru ISO și IEC, reprezentând interesele SUA acolo.
Istorie
ANSI a fost înființată inițial în 1918, când cinci societăți de inginerie și trei agenții guvernamentale au fondat „Comitetul american de standarde de inginerie” ( AESC- Engleză. Comitetul american de standarde de inginerie). În 1928, comitetul a devenit cunoscut sub numele de Asociația Americană de Standarde. CA- Engleză. Asociația Americană de Standarde). În 1966, ASA a fost reorganizată și a devenit „Institutul de Standarde al Statelor Unite ale Americii” ( USASI- Engleză. Institutul de standarde al Statelor Unite ale Americii). Numele actual a fost adoptat în 1969.
Până în 1918, au existat cinci societăți de inginerie implicate în dezvoltarea standardelor tehnice:
- Institutul American de Ingineri Electrici (AIEE, acum IEEE)
- Societatea Americană a Inginerilor Mecanici (ASME)
- Societatea Americană a Inginerilor Civili (ASCE)
- Institutul American de Ingineri Mineri (AIME, acum Institutul American de Ingineri Mineri, Metalurgici și Petrolieri)
- Societatea Americană pentru Testare și Materiale (acum ASTM)
În 1916, Institutul American de Ingineri Electrici (acum IEEE) a luat inițiativa de a combina eforturile acestor organizații pentru a crea un organism național independent care să coordoneze elaborarea standardelor, armonizarea și aprobarea standardelor naționale. Cele cinci organizații de mai sus au devenit membrii principali ai United Engineering Society (United Engineering Society - UES), ulterior Departamentul de Război al SUA, Marina (fuzionat în 1947 pentru a deveni Departamentul de Apărare al SUA) și Comerțul au fost invitați să participe în calitate de fondatori.
În 1931, organizația (renumită ASA în 1928) a devenit parte a Comitetului Național al Comisiei Electrotehnice Internaționale (IEC) din SUA, care a fost format în 1904 pentru a dezvolta standarde în inginerie electrică și electronică.
Membrii
Membrii ANSI includ agenții guvernamentale, organizații, organizații academice și internaționale și persoane fizice. În total, Institutul reprezintă interesele a peste 270.000 de companii și organizații și a 30 de milioane de profesioniști din întreaga lume /
Activitate
Deși ANSI în sine nu dezvoltă standarde, Institutul supraveghează dezvoltarea și utilizarea standardelor prin acreditarea procedurilor organizațiilor de dezvoltare a standardelor. Acreditarea ANSI înseamnă că procedurile utilizate de organizațiile care dezvoltă standarde îndeplinesc cerințele Institutului pentru deschidere, echilibru, consens și proces echitabil.
ANSI desemnează, de asemenea, standarde specifice ca standarde naționale americane, sau ANS, atunci când Institutul stabilește că standardele au fost dezvoltate într-un mediu care este echitabil, accesibil și receptiv la nevoile diferitelor părți interesate.
Activitate internațională
Pe lângă activitățile de standardizare din SUA, ANSI promovează utilizarea internațională a standardelor SUA, susține poziția politică și tehnică a SUA în organizațiile internaționale și regionale de standardizare și încurajează adoptarea standardelor internaționale ca standarde naționale.
Institutul este reprezentantul oficial al SUA în două mari organizații internaționale de standardizare, Organizația Internațională pentru Standardizare (ISO) ca membru fondator și Comisia Electrotehnică Internațională (IEC) prin Comitetul Național al SUA (USNC). ANSI participă la aproape întregul program tehnic al ISO și IEC și gestionează multe comitete și subgrupuri cheie. În multe cazuri, standardele SUA sunt transmise ISO și IEC prin ANSI sau USNC, unde sunt acceptate în întregime sau parțial ca standarde internaționale.
Acceptarea standardelor ISO și IEC ca standarde americane a crescut de la 0,2% în 1986 la 15,5% în mai 2012.
Direcții de standardizare
Institutul gestionează nouă grupuri de standardizare:
- ANSI Homeland Defence and Security Standardization Collaborative (HDSSC)
- Panoul de standarde pentru nanotehnologie ANSI (ANSI-NSP - Panoul pentru standarde pentru nanotehnologie ANSI)
- Panoul de standarde pentru prevenirea furtului de identitate și managementul ID-ului (IDSP - ID Theft Prevention and ID Management Standards Panel)
- ANSI Energy Efficiency Standardization Coordination Collaborative (EESCC)
- Colaborare de coordonare a standardelor de energie nucleară (NESCC-Colaborare de coordonare a standardelor de energie nucleară)
- Panoul de standarde pentru vehicule electrice (EVSP)
- Rețeaua ANSI-NAM de reglementare a substanțelor chimice
- Panoul de coordonare a standardelor pentru biocombustibili ANSI
- Panoul de standarde pentru tehnologia informației în domeniul sănătății (HITSP)
- Agenția americană de certificare pentru țevi și mașini
Fiecare dintre grupuri este angajat în identificarea, coordonarea și armonizarea standardelor voluntare legate de aceste domenii. În 2009, ANSI și (NIST) au format Nuclear Energy Standards Coordinating Collaboration (NESCC). NESCC este o inițiativă de colaborare pentru a identifica și a satisface nevoia actuală de standarde în industria nucleară.
Standarde
Dintre standardele adoptate de institut se cunosc următoarele:
Spre deosebire de concepția greșită populară, ANSI nu a adoptat standardele paginii de coduri pe 8 biți, deși a fost implicat în dezvoltarea codării ISO-8859-1 și, posibil, a altora.
Note
- Despre ANSI
- RFC
- ANSI: Prezentare istorică (nedefinit) . ansi.org. Preluat la 31 octombrie 2016.
- Istoria ANSI
Adesea, în programarea web și aspectul paginilor html, trebuie să vă gândiți la codificarea fișierului editat - la urma urmei, dacă codarea este selectată incorect, atunci există șansa ca browserul să nu o poată determina automat și ca un rezultat utilizatorul va vedea așa-numitul. „Krakozyabry”.
Poate că ați văzut pe unele site-uri simboluri ciudate și semne de întrebare în loc de text normal. Toate acestea se întâmplă atunci când codificarea paginii html și codificarea fișierului în sine a acestei pagini nu se potrivesc.
Deloc, ce este codificarea textului? Este doar un set de caractere, în engleză „set de caractere” (set de caractere). Este necesar pentru a converti informațiile text în biți de date și pentru a transmite, de exemplu, prin Internet.
De fapt, principalii parametri care disting codificări sunt numărul de octeți și setul de caractere speciale în care este convertit fiecare caracter al textului sursă.
Scurt istoric al codificărilor:
Unul dintre primii care au transmis informații digitale a fost apariția codificării ASCII - Cod standard american pentru schimbul de informații - tabel de coduri standard american, adoptat de Institutul Național American de Standarde - Institutul Național American de Standarde (ANSI).
Aceste abrevieri pot fi confuze Pentru practică, este important să înțelegeți că codificarea inițială a fișierelor text create poate să nu suporte toate caracterele unor alfabete (de exemplu, hieroglife), deci există tendința de a trece la așa- numit. standard Unicode (Unicode), care acceptă codificări universale − utf-8, utf-16, utf-32 si etc.
Cea mai populară codificare Unicode este Utf-8. De obicei, paginile site-ului sunt acum tipărite în el și sunt scrise diferite scripturi. Vă permite să afișați cu ușurință diverse hieroglife, litere grecești și alte caractere imaginabile și de neconceput (dimensiunea caracterelor de până la 4 octeți). În special, toate fișierele WordPress și Joomla sunt scrise în această codificare. Și, de asemenea, unele tehnologii web (în special, AJAX) sunt capabile să proceseze doar caracterele utf-8 în mod normal.
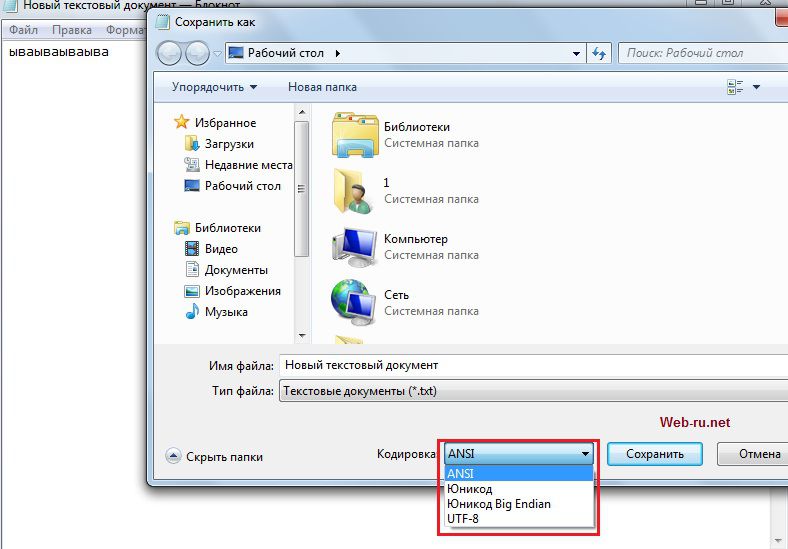
Setați codurile unui fișier text atunci când îl creați cu un blocnotes obișnuit. Se poate face clic
În Runet, puteți găsi în continuare site-uri scrise cu așteptarea codificării Windows-1251 (sau cp-1251). Aceasta este o codificare specială concepută special pentru chirilic.
Practic, „ANSI” se referă la pagina de coduri moștenită din Windows. Vezi și pe acest subiect. Primele 127 de caractere sunt identice cu ASCII în majoritatea paginilor de cod, însă caracterele de sus sunt diferite.
Cu toate acestea, ANSI automat nu reprezintă CP1252 sau Latin 1.
În ciuda toată confuzia, ar trebui să evitați astfel de probleme pentru moment și să utilizați Unicode.
Care este formatul de codare ANSI? Este acesta formatul implicit de sistem? Cum este diferit de ASCII?
La un moment dat, Microsoft, la fel ca toți ceilalți, folosea seturi de caractere de 7 biți și au venit cu ale lor atunci când li se potriveau, deși au păstrat ASCII ca subsetul principal. Apoi și-au dat seama că lumea a trecut la codificări pe 8 biți și că există standarde internaționale precum familia ISO-8859. În acele vremuri, dacă îți doreai un standard internațional și locuiai în SUA, îl cumpărai de la American National Standards Institute ANSI, care reedia standardele internaționale cu propriile mărci și numere (asta pentru că guvernul SUA vrea standarde americane și nu standardele internaționale). Deci, copia Microsoft ISO-8859 spunea „ANSI” pe coperta. Și pentru că Microsoft nu era foarte obișnuit cu standardele în acele vremuri, ei nu și-au dat seama că ANSI a publicat o mulțime de alte standarde. Așa că s-au referit la familia de standarde ISO-8859 (și la variantele pe care le-au inventat pentru că nu înțelegeau standardele în acele vremuri) prin titlul de copertă „ANSI” și a găsit drum în documentația pentru utilizatori a Microsoft și, prin urmare, în comunitate. . utilizatori. Asta a fost acum aproximativ 30 de ani, dar încă auzi numele ocazional și astăzi.
Sau vă puteți interoga registrul:
C:\>reg interogare HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage /f ACP HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage ACP REG_SZ 1252 Sfârșitul căutării: 1 potrivire. C:\>
Când utilizați caractere pe un singur octet, formatul ASCII definește primele 127 de caractere. Caracterele extinse de la 128 la 255 sunt definite de diferite coduri ANSI pentru a oferi suport limitat pentru alte limbi. Pentru a înțelege codarea ANSI, trebuie să știți ce pagină de coduri folosește.
Din punct de vedere tehnic, ANSI ar trebui să fie același cu US-ASCII. Se referă la standardul ANSI X3.4, care este pur și simplu versiunea ASCII aprobată de organizația ANSI. Utilizarea caracterelor de biți superiori nu este definită în ASCII/ANSI deoarece este un set de caractere de 7 biți.
Cu toate acestea, ani de utilizare greșită a termenului de către DOS și, ulterior, de către comunitatea Windows și-au lăsat sensul practic ca „pagina de cod de sistem a oricărei mașini”. Pagina de coduri de sistem este uneori cunoscută ca „mbcs” ca în sistemele din Asia de Est, care poate fi o codificare cu mai mulți octeți per caracter. Unele pagini de cod pot folosi chiar octeți de biți de top ca octeți de octeți într-o secvență de mai mulți octeți, așa că nici măcar nu este strict compatibil cu ASCII simplu... dar chiar și atunci se mai numește ANSI.
În setările implicite din SUA și Europa de Vest, „ANSI” se mapează la pagina de cod Windows 1252. Acesta nu este același cu ISO-8859-1 (deși este destul de similar). Pe alte mașini ar putea fi orice. Acest lucru face ca ANSI să fie complet inutil ca identificator extern de codificare.
Îmi amintesc când textul ANSI se referea la codurile de evadare pseudo-VT-100 utilizate în DOS prin driverul ANSI.SYS pentru a schimba fluxul de text al fluxului... Probabil că nu despre ceea ce vorbești, dar dacă vede
 Ce indică erorile de paginare?
Ce indică erorile de paginare? I/O sincron și asincron I/O asincron
I/O sincron și asincron I/O asincron Mașini cu stări finite, cum să programați fără a da greșelii
Mașini cu stări finite, cum să programați fără a da greșelii