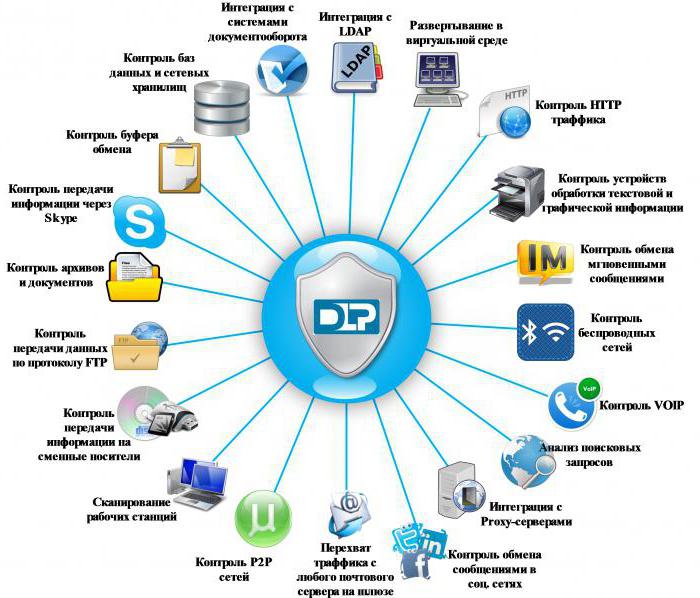
DLP technology. DLP - what does it mean? Update security rules at regular intervals
28.01.2014 Sergei Korablev
The choice of any enterprise-level product is not a trivial task for technical specialists and decision makers. Choosing a Data Leak Protection (DLP) data loss prevention system is even more difficult. The lack of a unified conceptual system, regular independent comparative studies and the complexity of the products themselves force consumers to order pilot projects from manufacturers and independently conduct numerous tests, determining the range of their own needs and correlating them with the capabilities of the systems being tested
Such an approach is certainly correct. A balanced, and in some cases even a hard-won decision simplifies further implementation and avoids disappointment in the operation of a particular product. However, the decision-making process in this case can be delayed, if not for years, then for many months. In addition, the constant expansion of the market, the emergence of new solutions and manufacturers further complicate the task of not only choosing a product for implementation, but also creating a preliminary shortlist of suitable DLP systems. Under such conditions, up-to-date reviews of DLP systems are of undoubted practical value for technical specialists. Should a particular solution be included in the test list, or would it be too complex to implement in a small organization? Can the solution be scaled to a company of 10,000 employees? Can a DLP system control business-critical CAD files? An open comparison will not replace thorough testing, but will help answer basic questions that arise at the initial stage of the DLP selection process.
Members
The most popular (according to the Anti-Malware.ru analytical center as of mid-2013) DLP systems of InfoWatch, McAfee, Symantec, Websense, Zecurion and Jet Infosystem companies in the Russian information security market were selected as participants.
For the analysis, commercially available versions of DLP systems were used at the time of preparation of the review, as well as documentation and open reviews of products.
Criteria for comparing DLP systems were selected based on the needs of companies of various sizes and industries. The main task of DLP systems is to prevent leaks of confidential information through various channels.
Examples of products from these companies are shown in Figures 1-6.
.jpg) |
| Figure 3 Symantec product |
.jpg) |
| Figure 4. InfoWatch product |
.jpg) |
| Figure 5. Websense product |
.jpg) |
| Figure 6. McAfee product |
Operating modes
Two main operating modes of DLP systems are active and passive. Active - usually the main mode of operation, which blocks actions that violate security policies, such as sending sensitive information to an external mailbox. Passive mode is most often used at the stage of system configuration to check and adjust settings when the proportion of false positives is high. In this case, policy violations are recorded, but restrictions on the movement of information are not imposed (Table 1).
.jpg) |
In this aspect, all the considered systems turned out to be equivalent. Each of the DLPs can work both in active and passive modes, which gives the customer a certain freedom. Not all companies are ready to start operating DLP immediately in blocking mode - this is fraught with disruption of business processes, dissatisfaction on the part of employees of controlled departments and claims (including justified ones) from management.
Technologies
Detection technologies make it possible to classify information transmitted via electronic channels and identify confidential information. Today, there are several basic technologies and their varieties, similar in essence, but different in implementation. Each technology has both advantages and disadvantages. In addition, different types of technologies are suitable for analyzing information of different classes. Therefore, manufacturers of DLP solutions try to integrate the maximum number of technologies into their products (see Table 2).
In general, the products provide a large number of technologies that, if properly configured, provide a high percentage of recognition of confidential information. DLP McAfee, Symantec and Websense are rather poorly adapted for the Russian market and cannot offer users support for "language" technologies - morphology, transliteration analysis and masked text.
Controlled channels
Each data transmission channel is a potential channel for leaks. Even one open channel can negate all the efforts of the information security service that controls information flows. That is why it is so important to block channels that are not used by employees for work, and control the rest with the help of leak prevention systems.
Despite the fact that the best modern DLP systems are capable of monitoring a large number of network channels (see Table 3), it is advisable to block unnecessary channels. For example, if an employee works on a computer only with an internal database, it makes sense to disable his access to the Internet altogether.
Similar conclusions are also valid for local leakage channels. True, in this case it can be more difficult to block individual channels, since ports are often used to connect peripherals, I / O devices, etc.
Encryption plays a special role in preventing leaks through local ports, mobile drives and devices. Encryption tools are quite easy to use, their use can be transparent to the user. But at the same time, encryption eliminates a whole class of leaks associated with unauthorized access to information and the loss of mobile drives.
The situation with the control of local agents is generally worse than with network channels (see Table 4). Only USB devices and local printers are successfully controlled by all products. Also, despite the importance of encryption noted above, such a possibility is present only in certain products, and the forced encryption function based on content analysis is present only in Zecurion DLP.
To prevent leaks, it is important not only to recognize sensitive data during transmission, but also to limit the distribution of information in a corporate environment. To do this, manufacturers include tools in DLP systems that can identify and classify information stored on servers and workstations in the network (see Table 5). Data that violates information security policies must be deleted or moved to secure storage.
To detect confidential information on the corporate network nodes, the same technologies are used as to control leaks through electronic channels. The main difference is architectural. If network traffic or file operations are analyzed to prevent leakage, then stored information, the contents of workstations and network servers, is examined to detect unauthorized copies of confidential data.
Of the considered DLP systems, only InfoWatch and Dozor-Jet ignore the use of means for identifying information storage locations. This is not a critical feature for electronic leak prevention, but it greatly limits the ability of DLP systems to proactively prevent leaks. For example, when a confidential document is located within a corporate network, this is not an information leak. However, if the location of this document is not regulated, if the information owners and security officers do not know about the location of this document, this can lead to a leak. Unauthorized access to information is possible or the appropriate security rules will not be applied to the document.
Ease of management
Characteristics such as ease of use and control can be as important as the technical capabilities of solutions. After all, a really complex product will be difficult to implement, the project will take more time, effort and, accordingly, finances. An already implemented DLP system requires attention from technical specialists. Without proper maintenance, regular auditing and adjustment of settings, the quality of recognition of confidential information will drop significantly over time.
The control interface in the native language of the security officer is the first step to simplify the work with the DLP system. It will not only make it easier to understand what this or that setting is responsible for, but will also significantly speed up the process of configuring a large number of parameters that need to be configured for the system to work correctly. English can be useful even for Russian-speaking administrators for an unambiguous interpretation of specific technical concepts (see Table 6).
Most solutions provide quite convenient management from a single (for all components) console with a web interface (see Table 7). The exceptions are the Russian InfoWatch (there is no single console) and Zecurion (there is no web interface). At the same time, both manufacturers have already announced the appearance of a web console in their future products. The lack of a single console in InfoWatch is due to the different technological basis of the products. The development of its own agency solution was discontinued for several years, and the current EndPoint Security is the successor to a third-party product, EgoSecure (formerly known as cynapspro), acquired by the company in 2012.
Another point that can be attributed to the disadvantages of the InfoWatch solution is that to configure and manage the flagship DLP product InfoWatch TrafficMonitor, you need to know a special scripting language LUA, which complicates the operation of the system. Nevertheless, for most technical specialists, the prospect of improving their own professional level and learning an additional, albeit not very common, language should be perceived positively.
The separation of system administrator roles is necessary to minimize the risks of preventing the appearance of a superuser with unlimited rights and other machinations using DLP.
Logging and reporting
The DLP archive is a database that accumulates and stores events and objects (files, letters, http requests, etc.) recorded by the system's sensors during its operation. The information collected in the database can be used for various purposes, including for analyzing user actions, for saving copies of critical documents, as a basis for investigating information security incidents. In addition, the database of all events is extremely useful at the stage of implementing a DLP system, since it helps to analyze the behavior of the DLP system components (for example, to find out why certain operations are blocked) and to adjust security settings (see Table 8).
.jpg) |
In this case, we see a fundamental architectural difference between Russian and Western DLPs. The latter do not archive at all. In this case, DLP itself becomes easier to maintain (there is no need to maintain, store, backup and study a huge amount of data), but not to operate. After all, the archive of events helps to configure the system. The archive helps to understand why the transmission of information was blocked, to check whether the rule worked correctly, and to make the necessary corrections to the system settings. It should also be noted that DLP systems need not only initial configuration during implementation, but also regular “tuning” during operation. A system that is not properly maintained, not brought up by technical specialists, will lose a lot in the quality of information recognition. As a result, both the number of incidents and the number of false positives will increase.
Reporting is an important part of any activity. Information security is no exception. Reports in DLP systems perform several functions at once. First, concise and understandable reports allow heads of information security services to quickly monitor the state of information security without going into details. Second, detailed reports help security officers adjust security policies and system settings. Thirdly, visual reports can always be shown to top managers of the company to demonstrate the results of the DLP system and the information security specialists themselves (see Table 9).
Almost all competing solutions discussed in the review offer both graphical, convenient for top managers and heads of information security services, and tabular reports, more suitable for technical specialists. Graphical reports are missing only in DLP InfoWatch, for which they were lowered.
Certification
The question of the need for certification for information security tools and DLP in particular is open, and experts often argue on this topic within professional communities. Summarizing the opinions of the parties, it should be recognized that certification itself does not provide serious competitive advantages. At the same time, there are a number of customers, primarily government organizations, for which the presence of a particular certificate is mandatory.
In addition, the existing certification procedure does not correlate well with the software development cycle. As a result, consumers are faced with a choice: to buy an already outdated, but certified version of the product or an up-to-date, but not certified version. The standard way out in this situation is to purchase a certified product "on the shelf" and use the new product in a real environment (see Table 10).
Comparison results
Let's summarize the impressions of the considered DLP solutions. In general, all participants made a favorable impression and can be used to prevent information leaks. Differences in products allow you to specify the scope of their application.
The InfoWatch DLP system can be recommended to organizations for which it is fundamentally important to have a FSTEC certificate. However, the latest certified version of InfoWatch Traffic Monitor was tested at the end of 2010, and the certificate expires at the end of 2013. Agent-based solutions based on InfoWatch EndPoint Security (also known as EgoSecure) are more suitable for small businesses and can be used separately from Traffic Monitor. The combined use of Traffic Monitor and EndPoint Security can cause scaling issues in large companies.
Products of Western manufacturers (McAfee, Symantec, Websense), according to independent analytical agencies, are much less popular than Russian ones. The reason is the low level of localization. And it's not even the complexity of the interface or the lack of documentation in Russian. Features of technologies for recognizing confidential information, pre-configured templates and rules are "sharpened" for the use of DLP in Western countries and are aimed at fulfilling Western regulatory requirements. As a result, the quality of information recognition in Russia turns out to be noticeably worse, and compliance with the requirements of foreign standards is often irrelevant. At the same time, the products themselves are not bad at all, but the specifics of using DLP systems on the Russian market are unlikely to allow them to become more popular than domestic developments in the foreseeable future.
Zecurion DLP is notable for good scalability (the only Russian DLP system with confirmed implementation for more than 10,000 jobs) and high technological maturity. What is surprising, however, is the lack of a web console that would help simplify the management of an enterprise solution aimed at various market segments. Zecurion DLP's strengths include high-quality confidential information recognition and a full line of leak prevention products, including protection at the gateway, workstations and servers, location detection and data encryption tools.
The Dozor-Jet DLP system, one of the pioneers of the domestic DLP market, is widely distributed among Russian companies and continues to grow its client base due to extensive connections of the Jet Infosystems system integrator, part-time and DLP developer. Although technologically DLP is somewhat behind its more powerful counterparts, its use can be justified in many companies. In addition, unlike foreign solutions, Dozor Jet allows you to archive all events and files.
Leakage channels leading to information being taken out of the company's information system can be network leaks (for example, e-mail or ICQ), local leaks (use of external USB drives), stored data (databases). Separately, you can highlight the loss of media (flash memory, laptop). A system can be attributed to the DLP class if it meets the following criteria: multi-channel (monitoring of several possible channels of data leakage); unified management (unified management tools for all monitoring channels); active protection (compliance with security policy); considering both content and context.
The competitive advantage of most systems is the analysis module. Manufacturers emphasize this module so much that they often name their products after it, for example, “Label-based DLP solution”. Therefore, the user often chooses solutions not based on performance, scalability, or other criteria traditional for the corporate information security market, but on the basis of the type of document analysis used.
Obviously, since each method has its advantages and disadvantages, the use of only one document analysis method makes the solution technologically dependent on it. Most manufacturers use several methods, although one of them is usually the "flagship" method. This article is an attempt to classify the methods used in the analysis of documents. Their strengths and weaknesses are assessed based on the experience of practical application of several types of products. The article fundamentally does not consider specific products, because. the main task of the user when choosing them is to eliminate marketing slogans like “we will protect everything from everything”, “unique patented technology” and realize what he will be left with when the sellers leave.
Container Analysis

This method analyzes the properties of a file or other container (archive, cryptodisk, etc.) that contains information. The colloquial name for such methods is “solutions on labels”, which quite fully reflects their essence. Each container contains a label that uniquely identifies the type of content contained within the container. The mentioned methods practically do not require computing resources to analyze the information being moved, since the label fully describes the user's rights to move content along any route. In a simplified form, such an algorithm sounds like this: “there is a label - we forbid it, there is no label - we skip it.”
The advantages of this approach are obvious: the speed of analysis and the complete absence of errors of the second kind (when the system mistakenly detects an open document as confidential). Such methods are called "deterministic" in some sources.
The disadvantages are also obvious - the system only cares about tagged information: if the tag is not set, the content is not protected. It is necessary to develop a procedure for labeling new and incoming documents, as well as a system to counter the transfer of information from a labeled container to an unlabeled one through buffer operations, file operations, copying information from temporary files, etc.
The weakness of such systems is also manifested in the organization of labeling. If they are placed by the author of the document, then by malicious intent he has the opportunity not to mark the information that he is going to steal. In the absence of malicious intent, sooner or later negligence or carelessness will appear. If you oblige to label a certain employee, for example, an information security officer or a system administrator, then he will not always be able to distinguish confidential content from open content, since he does not know thoroughly all the processes in the company. So, the "white" balance should be posted on the company's website, and the "gray" or "black" balance cannot be taken out of the information system. But only the chief accountant can distinguish one from the other, i.e. one of the authors.
Labels are usually divided into attribute, format and external. As the name suggests, the former are placed in file attributes, the latter are placed in the fields of the file itself, and the third are attached to (associated with) the file by external programs.
Container structures in IB
Sometimes the advantages of solutions based on tags are also low performance requirements for interceptors, because they only check tags, i.e. act like turnstiles in the subway: "if you have a ticket - go through." However, do not forget that miracles do not happen - in this case, the computational load is shifted to workstations.
The place of decisions on labels, whatever they may be, is the protection of document storages. When a company has a document storage, which, on the one hand, is replenished quite rarely, and on the other hand, the category and confidentiality level of each document are precisely known, then it is easiest to organize its protection using labels. You can organize the placement of labels on documents entering the repository using an organizational procedure. For example, before sending a document to the repository, the employee responsible for its functioning can contact the author and the specialist with the question of what level of confidentiality to set for the document. This task is especially successfully solved with the help of format marks, i.e. each incoming document is stored in a secure format and then issued at the request of the employee, indicating it as allowed to read. Modern solutions allow you to assign access rights for a limited time, and after the expiration of the key, the document simply stops being read. It is according to this scheme that, for example, the issuance of documentation for public procurement tenders in the United States is organized: the procurement management system generates a document that can be read without the possibility of changing or copying the contents only of the tender participants listed in this document. The access key is valid only until the deadline for submitting documents to the competition, after which the document ceases to be read.
Also, with the help of solutions based on tags, companies organize document circulation in closed segments of the network in which intellectual property and state secrets circulate. Probably, now, according to the requirements of the Federal Law “On Personal Data”, the document flow in the personnel departments of large companies will also be organized.
Content analysis
When implementing the technologies described in this section, unlike those described earlier, on the contrary, it is completely indifferent in which container the content is stored. The purpose of these technologies is to extract meaningful content from a container or intercept a transmission over a communication channel and analyze the information for prohibited content.
The main technologies in detecting prohibited content in containers are signature control, hash-based control, and linguistic methods.
Signatures
The simplest control method is to search the data stream for some sequence of characters. Sometimes a forbidden sequence of characters is called a "stop word", but in a more general case it can be represented not by a word, but by an arbitrary set of characters, for example, by the same label. In general, this method can not be attributed to content analysis in all its implementations. For example, in most devices of the UTM class, the search for forbidden signatures in the data stream occurs without extracting the text from the container, when analyzing the stream "as is". Or, if the system is configured for only one word, then the result of its work is the determination of a 100% match, i.e. method can be classified as deterministic.
However, more often the search for a specific sequence of characters is still used in text analysis. In the vast majority of cases, signature systems are configured to search for several words and the frequency of occurrence of terms, i.e. we will still refer this system to content analysis systems.
The advantages of this method include independence from the language and ease of replenishing the dictionary of prohibited terms: if you want to use this method to search for a word in Pashto in the data stream, you do not need to know this language, you just need to know how it is written. It is also easy to add, for example, transliterated Russian text or "Albanian" language, which is important, for example, when analyzing SMS texts, ICQ messages or blog posts.
The disadvantages become apparent when using a non-English language. Unfortunately, most manufacturers of text analysis systems work for the American market, and the English language is very "signature" - word forms are most often formed using prepositions without changing the word itself. In Russian, everything is much more complicated. Take, for example, the word "secret" dear to the heart of an information security officer. In English, it means both the noun "secret", the adjective "secret", and the verb "to keep secret". In Russian, several dozen different words can be formed from the root “secret”. Those. if in an English-speaking organization it is enough for an information security officer to enter one word, in a Russian-speaking organization they will have to enter a couple of dozen words and then change them in six different encodings.
In addition, such methods are unstable to primitive coding. Almost all of them give in to the favorite trick of novice spammers - replacing characters with similar ones. The author repeatedly demonstrated to security officers an elementary trick - the passage of confidential text through signature filters. A text containing, for example, the phrase "top secret" is taken, and a mail interceptor configured for this phrase. If the text is opened in MS Word, then a two-second operation: Ctrl + F, "find "o" (Russian layout)", "replace with "o" (English layout)", "replace all", "send document" - makes the document absolutely invisible to this filter. It is all the more disappointing that such a replacement is carried out by regular means of MS Word or any other text editor, i.e. they are available to the user, even if he does not have local administrator rights and the ability to run encryption programs.
Most often, signature-based flow control is included in the functionality of UTM devices, i.e. solutions that clean traffic from viruses, spam, intrusions and any other threats that are detected by signatures. Since this feature is "free", users often feel that this is enough. Such solutions really protect against accidental leaks, i.e. in cases where the outgoing text is not changed by the sender in order to bypass the filter, but they are powerless against malicious users.
masks
An extension of the functionality of the search for stopword signatures is the search for their masks. It is a search for such content that cannot be accurately specified in the base of "stop words", but its element or structure can be specified. Such information should include any codes characterizing a person or enterprise: TIN, numbers of accounts, documents, etc. It is impossible to search for them using signatures.
It is unreasonable to set the number of a specific bank card as a search object, but you want to find any credit card number, no matter how it is written - with spaces or together. This is not just a desire, but a requirement of the PCI DSS standard: it is forbidden to send unencrypted plastic card numbers by e-mail, i.e. it is the user's responsibility to find such numbers in the e-mail and discard prohibited messages.
Here, for example, is a mask that specifies a stop word such as the name of a confidential or secret order, the number of which starts from zero. The mask takes into account not only an arbitrary number, but also any case and even the substitution of Russian letters for Latin ones. The mask is written in the standard "REGEXP" notation, although different DLP systems may have their own, more flexible notation. The situation is even worse with phone numbers. This information is classified as personal data, and you can write it in a dozen ways - using different combinations of spaces, different types of brackets, plus and minus, etc. Here, perhaps, a single mask is indispensable. For example, in anti-spam systems, where a similar task has to be solved, several dozen masks are used simultaneously to detect a telephone number.
Many different codes inscribed in the activities of companies and their employees are protected by many laws and represent commercial secrets, banking secrets, personal data and other legally protected information, so the problem of detecting them in traffic is a prerequisite for any solution.
Hash functions
Various types of hash functions for samples of confidential documents were at one time considered a new word in the leak protection market, although the technology itself has been around since the 1970s. In the West, this method is sometimes called "digital fingerprints", i.e. "digital fingerprints", or "shindles" in scientific slang.
The essence of all methods is the same, although specific algorithms for each manufacturer may differ significantly. Some algorithms are even patented, which confirms the uniqueness of the implementation. The general scenario of action is as follows: a database of samples of confidential documents is being collected. An “imprint” is taken from each of them, i.e. meaningful content is extracted from the document, which is reduced to some normal, for example (but not necessarily) text form, then the hashes of all content and its parts, such as paragraphs, sentences, fives of words, etc., are removed, the detail depends on the specific implementation. These fingerprints are stored in a special database.
The intercepted document is cleared of service information in the same way and brought to a normal form, then fingerprints-shindles are removed from it using the same algorithm. Received prints are searched in the database of prints of confidential documents, and if found, the document is considered confidential. Since this method is used to find direct quotes from a sample document, the technology is sometimes called "anti-plagiarism".
Most of the advantages of this method are also its disadvantages. First of all, this is the requirement to use sample documents. On the one hand, the user does not have to worry about stop words, significant terms and other information that is completely non-specific for security officers. On the other hand, "no pattern, no protection" poses the same problems with new and incoming documents as with label-based technologies. A very important advantage of this technology is its focus on working with arbitrary character sequences. From this follows, first of all, independence from the language of the text - even hieroglyphs, even Pashto. Further, one of the main consequences of this property is the possibility of taking fingerprints from non-textual information - databases, drawings, media files. It is these technologies that Hollywood studios and world recording studios use to protect media content in their digital storages.
Unfortunately, low-level hash functions are not robust to the primitive encoding discussed in the signature example. They easily cope with changing the order of words, rearranging paragraphs and other tricks of "plagiarists", but, for example, changing letters throughout the document destroys the hash pattern and such a document becomes invisible to the interceptor.
Using only this method complicates the work with forms. So, an empty loan application form is a freely distributed document, and a completed one is confidential, since it contains personal data. If you simply take a fingerprint from an empty form, then the intercepted completed document will contain all the information from the empty form, i.e. The prints will largely match. Thus, the system will either let confidential information through or prevent empty forms from being freely distributed.
Despite the shortcomings mentioned, this method is widely used, especially in a business that cannot afford qualified employees, but operates on the principle of "put all confidential information in this folder and sleep well." In this sense, requiring specific documents to protect them is somewhat similar to solutions based on labels, only stored separately from samples and preserved when changing the file format, copying part of the file, etc. However, a large business that has hundreds of thousands of documents in circulation is often simply not able to provide samples of confidential documents, because. the company's business processes do not require it. The only thing that is (or, more honestly, should be) in every enterprise is the "List of information constituting a trade secret." Making patterns out of it is not a trivial task.
The ease of adding samples to a controlled content database often plays tricks on users. This leads to a gradual increase in the fingerprint base, which significantly affects the performance of the system: the more samples, the more comparisons of each intercepted message. Since each print takes up from 5 to 20% of the original, the base of prints gradually grows. Users notice a sharp drop in performance when the database begins to exceed the filtering server's RAM. Usually the problem is solved by regularly auditing sample documents and removing outdated or duplicate samples, i.e. saving on implementation, users lose on operation.
Linguistic Methods
The most common method of analysis today is the linguistic analysis of the text. It is so popular that it is often referred to colloquially as "content filtering". carries the characteristics of the entire class of content analysis methods. From the point of view of classification, both hash analysis, and signature analysis, and mask analysis are “content filtering”, i.e. traffic filtering based on content analysis.
As the name implies, the method works only with texts. You will not use it to protect a database consisting only of numbers and dates, especially drawings, drawings and a collection of favorite songs. But with texts, this method works wonders.
Linguistics as a science consists of many disciplines - from morphology to semantics. Therefore, linguistic methods of analysis also differ from each other. There are methods that use only stop words, only entered at the root level, and the system itself already compiles a complete dictionary; there are terms based on the distribution of weights encountered in the text. There are linguistic methods and their imprints based on statistics; for example, a document is taken, the fifty most used words are counted, then the 10 most used words in each paragraph are selected. Such a "dictionary" is an almost unique characteristic of the text and allows you to find meaningful quotes in "clones".
Analysis of all the subtleties of linguistic analysis is not within the scope of this article, so we will focus on the advantages and disadvantages.
The advantage of the method is complete insensitivity to the number of documents, i.e. rare for corporate information security scalability. The content filtering base (a set of key vocabulary classes and rules) does not change in size depending on the appearance of new documents or processes in the company.
In addition, users note in this method the similarity with "stop words" in that if the document is delayed, then it is immediately clear why this happened. If a fingerprint-based system reports that a document is similar to another, then the security officer will have to compare the two documents himself, and in linguistic analysis he will receive already marked up content. Linguistic systems along with signature filtering are so common because they allow you to start working without changes in the company immediately after installation. There is no need to bother with tagging and fingerprinting, inventorying documents and doing other non-specific work for a security officer.
The disadvantages are just as obvious, and the first one is language dependence. In every country whose language is supported by the manufacturer, this is not a disadvantage, but from the point of view of global companies that have, in addition to a single language of corporate communication (for example, English), many more documents in local languages in each country, this is a clear disadvantage.
Another drawback is a high percentage of type II errors, which requires a qualification in the field of linguistics (to fine-tune the filtering base) to reduce it. Standard industry databases typically give 80-85% filtering accuracy. This means that every fifth or sixth letter is intercepted by mistake. Setting the base to an acceptable 95-97% accuracy is usually associated with the intervention of a specially trained linguist. And although to learn how to adjust the filtering base, it is enough to have two days of free time and speak the language at the level of a high school graduate, there is no one to do this work, except for a security officer, and he usually considers such work to be non-core. Attracting a person from outside is always risky - after all, he will have to work with confidential information. The way out of this situation is usually to buy an additional module - a self-learning "autolinguist", which is "fed" with false positives, and it automatically adapts the standard industry base.
Linguistic methods are chosen when they want to minimize interference in the business, when the information security service does not have the administrative resource to change the existing processes for creating and storing documents. They work always and everywhere, albeit with the disadvantages mentioned.
Popular channels of accidental leaks mobile storage media
InfoWatch analysts believe that mobile media (laptops, flash drives, mobile communicators, etc.) remain the most popular channel for accidental leaks, since users of such devices often neglect data encryption tools.
Another common cause of accidental leaks is paper media: it is more difficult to control than electronic media, since, for example, after a sheet leaves the printer, it can only be monitored “manually”: control over paper media is weaker than control over computer information. Many leak protection tools (you can’t call them full-fledged DLP systems) do not control the output channel of information to the printer, so confidential data easily leaks out of the organization.
This problem can be solved by multifunctional DLP systems that block the sending of unauthorized information for printing and check the correspondence of the postal address and the addressee.
In addition, the growing popularity of mobile devices makes it much more difficult to protect against leaks, because there are no corresponding DLP clients yet. In addition, it is very difficult to detect a leak in the case of cryptography or steganography. An insider, in order to bypass some kind of filter, can always turn to the Internet for “best practices”. That is, DLP-means protect quite poorly from an organized intentional leak.
The effectiveness of DLP tools can be hampered by their obvious flaws: modern leak protection solutions do not allow you to control and block all available information channels. DLP systems will monitor corporate email, web usage, instant messaging, external media, document printing, and hard drive content. But Skype remains out of control for DLP systems. Only Trend Micro has managed to declare that it can control the operation of this communication program. The remaining developers promise that the corresponding functionality will be provided in the next version of their security software.
But if Skype promises to open its protocols to DLP developers, other solutions, such as Microsoft Collaboration Tools for organizing collaboration, remain closed to third-party programmers. How to control the transmission of information over this channel? Meanwhile, in the modern world, the practice is developing when specialists remotely unite into teams to work on a common project and disintegrate after its completion.
The main sources of leaks of confidential information in the first half of 2010 are still commercial (73.8%) and government (16%) organizations. About 8% of leaks come from educational institutions. The nature of the leaking confidential information is personal data (almost 90% of all information leaks).
The leaders in leaks in the world are traditionally the United States and Great Britain (Canada, Russia and Germany are also in the top five countries by the largest number of leaks, with significantly lower rates), which is due to the peculiarity of the legislation of these countries, which requires reporting all incidents of confidential data leakage. Analysts at Infowatch predict a decrease in the share of accidental leaks and an increase in the share of intentional leaks next year.
Implementation difficulties
In addition to the obvious difficulties, the implementation of DLP is also hampered by the difficulty of choosing the right solution, since various vendors of DLP systems profess their own approaches to the organization of protection. Some have patented algorithms for analyzing content by keywords, while others offer a method of digital fingerprints. How to choose the best product in these conditions? What is more efficient? It is very difficult to answer these questions, since there are very few implementations of DLP systems today, and there are even fewer real practices for their use (which one could rely on). But those projects that were nevertheless implemented showed that consulting accounts for more than half of the scope of work and budget, and this usually causes great skepticism among management. In addition, as a rule, existing business processes of the enterprise have to be restructured to meet the requirements of DLP, and companies are having difficulty doing this.
To what extent does the introduction of DLP help to comply with the current requirements of regulators? In the West, the introduction of DLP systems is motivated by laws, standards, industry requirements and other regulations. According to experts, clear legal requirements available abroad, guidelines for ensuring requirements are the real engine of the DLP market, since the introduction of special solutions eliminates claims from regulators. We have a completely different situation in this area, and the introduction of DLP systems does not help to comply with the law.
Some incentive for the introduction and use of DLP in a corporate environment may be the need to protect the trade secrets of companies and comply with the requirements of the federal law "On Trade Secrets".
Almost every enterprise has adopted such documents as the “Regulations on trade secrets” and “List of information constituting a trade secret”, and their requirements should be followed. There is an opinion that the law "On Trade Secrets" (98-FZ) does not work, however, company executives are well aware that it is important and necessary for them to protect their trade secrets. Moreover, this awareness is much higher than the understanding of the importance of the law “On Personal Data” (152-FZ), and it is much easier for any manager to explain the need to introduce confidential document management than to talk about the protection of personal data.
What prevents the use of DLP in the process of automating the protection of trade secrets? According to the Civil Code of the Russian Federation, in order to introduce a trade secret protection regime, it is only necessary that the information has some value and be included in the appropriate list. In this case, the owner of such information is required by law to take measures to protect confidential information.
At the same time, it is obvious that DLP will not be able to solve all issues. In particular, cover access to confidential information to third parties. But there are other technologies for this. Many modern DLP solutions can integrate with them. Then, when building this technological chain, a working system for protecting trade secrets can be obtained. Such a system will be more understandable for the business, and it is the business that will be able to act as the customer of the leak protection system.
Russia and the West
According to analysts, Russia has a different attitude towards security and a different level of maturity of companies supplying DLP solutions. The Russian market focuses on security specialists and highly specialized problems. Data breach prevention people don't always understand what data is valuable. In Russia, a "militarist" approach to the organization of security systems: a strong perimeter with firewalls and every effort is made to prevent penetration inside.
But what if a company employee has access to an amount of information that is not required to perform his duties? On the other hand, if we look at the approach that has been formed in the West in the last 10-15 years, we can say that more attention is paid to the value of information. Resources are directed to where valuable information is located, and not to all the information in a row. Perhaps this is the biggest cultural difference between the West and Russia. However, analysts say the situation is changing. Information is beginning to be perceived as a business asset, and it will take some time to evolve.
There is no comprehensive solution
100% leak protection has not yet been developed by any manufacturer. The problems with using DLP products are formulated by some experts as follows: effective use of the experience of dealing with leaks used in DLP systems requires the understanding that a lot of work on providing leak protection must be done on the customer's side, since no one knows better than him information flows.
Others believe that it is impossible to protect against leaks: it is impossible to prevent information leakage. Since the information is of value to someone, it will be received sooner or later. Software tools can make obtaining this information more costly and time consuming. This can significantly reduce the benefit of possessing information, its relevance. This means that the efficiency of DLP systems should be monitored.
»Today, the DLP systems market is one of the fastest growing among all information security tools. However, the domestic information security sphere has not quite kept pace with global trends, and therefore the DLP systems market in our country has its own characteristics.
What is DLP and how do they work?
Before talking about the market of DLP-systems, it is necessary to decide what, in fact, is meant when it comes to such solutions. DLP systems are commonly understood as software products that protect organizations from leaks of confidential information. The abbreviation DLP itself stands for Data Leak Prevention, that is, the prevention of data leaks.
Such systems create a secure digital "perimeter" around the organization, analyzing all outgoing, and in some cases, incoming information. Controlled information should be not only Internet traffic, but also a number of other information flows: documents that are taken outside the protected security loop on external media, printed on a printer, sent to mobile media via Bluetooth, etc.
Since the DLP system must prevent leakage of confidential information, it necessarily has built-in mechanisms for determining the degree of confidentiality of a document detected in intercepted traffic. As a rule, two methods are most common: by parsing special document markers and by parsing the contents of the document. Currently, the second option is more common, because it is resistant to modifications made to the document before it is sent, and also allows you to easily expand the number of confidential documents that the system can work with.
"Side" DLP tasks
In addition to their main task related to the prevention of information leaks, DLP systems are also well suited for solving a number of other tasks related to the control of personnel actions.
Most often, DLP systems are used to solve the following non-core tasks for themselves:
- monitoring the use of working time and working resources by employees;
- monitoring the communication of employees in order to identify "undercover" struggles that can harm the organization;
- control over the legitimacy of employees' actions (prevention of printing counterfeit documents, etc.);
- identification of employees who send out resumes for the rapid search for specialists for a vacant position.
Due to the fact that many organizations consider a number of these tasks (especially control of the use of working time) to be a higher priority than protection against information leaks, a number of programs have arisen that are designed specifically for this, but in some cases can also work as a means of protecting the organization from leaks. . What distinguishes such programs from full-fledged DLP systems is the absence of advanced tools for analyzing intercepted data, which must be done manually by an information security specialist, which is convenient only for very small organizations (up to ten controlled employees).
DLP Technology
Digital Light Processing (DLP) is an advanced technology invented by Texas Instruments. Thanks to it, it was possible to create very small, very light (3 kg - is that really weight?) And, nevertheless, quite powerful (more than 1000 ANSI Lm) multimedia projectors.
Brief history of creation
A long time ago, in a galaxy far far away...
In 1987 Dr. Larry J. Hornbeck invented digital multimirror device(Digital Micromirror Device or DMD). This invention completed decades of Texas Instruments research into micromechanical deformable mirror devices(Deformable Mirror Devices or again DMD). The essence of the discovery was the rejection of flexible mirrors in favor of a matrix of rigid mirrors with only two stable positions.
In 1989, Texas Instruments becomes one of four companies selected to implement the "projector" portion of the U.S. High-Definition Display funded by the Advanced Research and Development Administration (ARPA).
In May 1992, TI demonstrates the first DMD-based system to support the modern resolution standard for ARPA.
A High-Definition TV (HDTV) version of DMD based on three high-definition DMDs was shown in February 1994.
Mass sales of DMD chips began in 1995.
DLP Technology
A key element of multimedia projectors created using DLP technology is a matrix of microscopic mirrors (DMD elements) made of an aluminum alloy with a very high reflectivity. Each mirror is attached to a rigid substrate, which is connected to the base of the matrix through movable plates. Electrodes connected to CMOS SRAM memory cells are placed at opposite angles of the mirrors. Under the action of an electric field, the substrate with a mirror assumes one of two positions that differ by exactly 20° due to the limiters located on the base of the matrix.
These two positions correspond to the reflection of the incoming light flux, respectively, into the lens and an effective light absorber that provides reliable heat removal and minimal light reflection.
The data bus and the matrix itself are designed to provide up to 60 or more image frames per second with a resolution of 16 million colors.
The mirror array, together with CMOS SRAM, make up the DMD chip, the basis of DLP technology.
The small size of the crystal is impressive. The area of each matrix mirror is 16 microns or less, and the distance between the mirrors is about 1 micron. Crystal, and not one, easily fits in the palm of your hand.
In total, if Texas Instruments does not deceive us, three types of crystals (or chips) are produced with different resolutions. This:
- SVGA: 848×600; 508,800 mirrors
- XGA: 1024×768 with black aperture (inter-slit space); 786,432 mirrors
- SXGA: 1280×1024; 1,310,720 mirrors
 |
 |
So, we have a matrix, what can we do with it? Well, of course, illuminate it with a more powerful luminous flux and place an optical system in the path of one of the reflection directions of the mirrors, which focuses the image on the screen. On the path of the other direction, it would be wise to place a light absorber so that unnecessary light does not cause inconvenience. Here we can already project monochrome pictures. But where is the color? Where is the brightness?

But this, it seems, was the invention of comrade Larry, which was discussed in the first paragraph of the section on the history of the creation of DLP. If you still don’t understand what’s the matter, get ready, because now a shock may happen to you :), because this elegant and quite obvious solution is by far the most advanced and technologically advanced in the field of image projection.
Remember the children's trick with a rotating flashlight, the light from which at some point merges and turns into a luminous circle. This joke of our vision allows us to completely abandon analog imaging systems in favor of completely digital ones. After all, even digital monitors at the last stage have an analog nature.
But what happens if we make the mirror switch from one position to another with a high frequency? If we neglect the switching time of the mirror (and due to its microscopic dimensions, this time can be completely neglected), then the apparent brightness will fall only by a factor of two. By changing the ratio of time during which the mirror is in one position and another, we can easily change the apparent brightness of the image. And since the cycle rate is very, very high, there will be no visible flicker at all. Eureka. Although nothing special, it's all been known for a long time :)
Well, now for the final touch. If the switching speed is fast enough, then we can place filters in succession in the path of the light flux and thereby create a color image.
Here, in fact, is the whole technology. We will follow its further evolutionary development on the example of multimedia projectors.
DLP projector device
Texas Instruments does not manufacture DLP projectors, many other companies do, such as 3M, ACER, PROXIMA, PLUS, ASK PROXIMA, OPTOMA CORP., DAVIS, LIESEGANG, INFOCUS, VIEWSONIC, SHARP, COMPAQ, NEC, KODAK, TOSHIBA , LIESEGANG, etc. Most of the produced projectors are portable, with a mass of 1.3 to 8 kg and a power of up to 2000 ANSI lumens. Projectors are divided into three types.
Single matrix projector
The simplest type we have already described is − single matrix projector, where a rotating disk with color filters - blue, green and red - is placed between the light source and the matrix. The disk rotation frequency determines the frame rate we are used to.

The image is formed in turn by each of the primary colors, resulting in a normal full-color image.
All, or almost all, portable projectors are built on a single-matrix type.
A further development of this type of projectors was the introduction of a fourth, transparent light filter, which makes it possible to significantly increase the brightness of the image.
Three matrix projector
The most complex type of projectors is three matrix projector, where the light is split into three color streams and reflected from three matrices at once. Such a projector has the purest color and frame rate, not limited by the speed of the disk, as in single-matrix projectors.

The exact match of the reflected flux from each matrix (convergence) is provided by a prism, as you can see in the figure.
Dual matrix projector
An intermediate type of projectors is dual matrix projector. In this case, the light is split into two streams: red is reflected from one DMD matrix, and blue and green from the other. The light filter, respectively, removes the blue or green components from the spectrum in turn.

A dual-matrix projector provides intermediate image quality compared to single-matrix and three-matrix types.
Comparison of LCD and DLP projectors
Compared to LCD projectors, DLP projectors have a number of important advantages:

Are there any disadvantages of DLP technology?
But theory is theory, but in practice there is still work to be done. The main drawback is the imperfection of the technology and, as a result, the problem of sticking mirrors.
The fact is that with such microscopic dimensions, small parts strive to “stick together”, and a mirror with a base is no exception.
Despite the efforts made by Texas Instruments to invent new materials that reduce the adhesion of micromirrors, such a problem exists, as we saw when testing a multimedia projector. Infocus LP340. But, I must say, she doesn’t really interfere with life.
Another problem is not so obvious and lies in the optimal selection of mirror switching modes. Every DLP projector company has its own opinion on this matter.
Well, the last. Despite the minimum time for switching mirrors from one position to another, this process leaves a barely noticeable trail on the screen. A kind of free antialiasing.
Technology development
- In addition to the introduction of a transparent light filter, work is constantly underway to reduce the inter-mirror space and the area of the column that fastens the mirror to the substrate (black dot in the middle of the image element).
- By splitting the matrix into separate blocks and expanding the data bus, the mirror switching frequency is increased.
- Work is underway to increase the number of mirrors and reduce the size of the matrix.
- The power and contrast of the light flux is constantly increasing. Three-matrix projectors with a power of over 10,000 ANSI Lm and a contrast ratio of over 1000:1 already exist today and have found their way into state-of-the-art cinemas using digital media.
- DLP technology is fully poised to replace CRT display technology in home theaters.
Conclusion
This is not all that could be said about DLP technology, for example, we did not touch on the topic of using DMD matrices in printing. But we will wait until Texas Instruments confirms the information available from other sources, so as not to give you a fake. I hope this short story is quite enough to get, if not the most complete, but sufficient idea of the technology and not torturing sellers with questions about the advantages of DLP projectors over others.
Thanks to Alexey Slepynin for help in preparing the material
These days, you can often hear about technology such as DLP systems. What is it and where is it used? This is software designed to prevent data loss by detecting possible violations while sending and filtering data. In addition, such services monitor, detect and block when it is used, when it moves (network traffic), and when it is stored.
As a rule, the leakage of confidential data occurs due to inexperienced users working with equipment or is the result of malicious actions. Such information in the form of private or corporate information, intellectual property (IP), financial or medical information, credit card information, and the like needs the enhanced security that modern information technology can offer.
The terms "data loss" and "data leak" are related and are often used interchangeably, although they are slightly different. Cases of information loss turn into its leakage when the source containing confidential information disappears and subsequently ends up with an unauthorized party. However, data leakage is possible without loss.
Categories DLP
Technological tools used to combat data leakage can be divided into the following categories: standard security measures, intelligent (advanced) measures, access control and encryption, as well as specialized DLP systems (which are described in detail below).

Standard Measures
Standard security measures such as intrusion detection systems (IDS) and antivirus software are common mechanisms available that keep computers safe from outsiders as well as insider attacks. Connecting a firewall, for example, prevents unauthorized persons from accessing the internal network, and an intrusion detection system detects intrusion attempts. Insider attacks can be prevented by antivirus scans that detect installed on the PC that send confidential information, as well as by using services that work in a client-server architecture without any personal or confidential data stored on the computer.
Additional Security Measures
Additional security measures use highly specialized services and timing algorithms to detect abnormal data access (i.e. databases or information retrieval systems) or abnormal email exchanges. In addition, such modern information technologies detect programs and requests that come with malicious intent, and perform deep checks on computer systems (for example, recognition of keystrokes or speaker sounds). Some of these services are even capable of monitoring user activity to detect unusual data access.

Custom designed DLP systems - what is it?
Designed for information security, DLP solutions are used to detect and prevent unauthorized attempts to copy or transfer sensitive data (intentionally or unintentionally) without permission or access, usually from users who have the right to access confidential data.
In order to classify certain information and regulate access to it, these systems use mechanisms such as exact matching of data, structured fingerprinting, acceptance of rules and regular expressions, publication of code phrases, conceptual definitions and keywords. Types and comparison of DLP systems can be represented as follows.
Network DLP (also known as data-in-motion or DiM)
As a rule, it is a hardware solution or software that is installed at network points that originate near the perimeter. It analyzes network traffic to detect sensitive data sent in violation of

Endpoint DLP (data when using )
Such systems operate on end user workstations or servers in various organizations.
As with other network systems, an endpoint can address both internal and external communications and can therefore be used to control the flow of information between types or groups of users (eg "firewalls"). They are also capable of monitoring email and instant messaging. This happens as follows - before the messages are downloaded to the device, they are checked by the service, and if they contain an unfavorable request, they are blocked. As a result, they become unsent and are not subject to data retention rules on the device.
The DLP system (technology) has the advantage that it can control and manage access to physical type devices (eg, mobile devices with storage capabilities) and sometimes access information before it is encrypted.

Some endpoint-based systems can also provide application control to block attempts to transmit sensitive information, as well as provide immediate feedback to the user. However, they have the disadvantage that they must be installed on every workstation on the network, and cannot be used on mobile devices (eg cell phones and PDAs) or where they cannot be practically installed (eg , at a workstation in an Internet cafe). This circumstance must be taken into account when choosing a DLP system for any purpose.
Data identification
DLP systems include several methods aimed at identifying secret or confidential information. Sometimes this process is confused with decryption. However, data identification is the process by which organizations use DLP technology to determine what to look for (in motion, at rest, or in use).
The data is classified as structured or unstructured. The first type is stored in fixed fields within the file (such as spreadsheets), while unstructured refers to free-form text (in the form of text documents or PDFs).
Experts estimate that 80% of all data is unstructured. Accordingly, 20% are structured. based on content analysis focused on structured information and contextual analysis. It is done at the place of creation of the application or system in which the data originated. Thus, the answer to the question "DLP systems - what is it?" will serve as the definition of the information analysis algorithm.
Methods Used
Methods for describing sensitive content today are numerous. They can be divided into two categories: accurate and inaccurate.
Accurate methods are those that are related to content analysis and practically nullify false positive responses to requests.
All others are imprecise and may include: dictionaries, keywords, regular expressions, extended regular expressions, data meta tags, Bayesian analysis, statistical analysis, etc.

The effectiveness of the analysis directly depends on its accuracy. A DLP system with a high rating scores high on this parameter. The accuracy of DLP identification is essential to avoid false positives and negative consequences. Accuracy can depend on many factors, some of which may be situational or technological. Accuracy testing can ensure the reliability of the DLP system - almost zero false positives.
Detection and prevention of information leaks
Sometimes the source of data distribution makes confidential information available to third parties. After some time, a part of it will most likely be found in an unauthorized place (for example, on the Internet or on another user's laptop). DLP systems, the price of which is provided by developers upon request and can range from several tens to several thousand rubles, must then investigate how the data leaked - from one or more third parties, whether it was independently of each other, whether the leak was provided by any then by other means, etc.
Data at rest
“Data at rest” refers to old archived information stored on any of the hard drives of the client PC, on a remote file server, on a disk. Also this definition refers to data stored in a backup system (on flash drives or CDs). This information is of great interest to businesses and governments simply because a large amount of data is stored unused in storage devices and is more likely to be accessed by unauthorized persons outside the network.
 Yandex browser update
Yandex browser update Yandex disk: logging into your disk?
Yandex disk: logging into your disk? How to update Google Chrome the easiest way?
How to update Google Chrome the easiest way?