We work with Yandex Wordstat. Automatic collection Yandex Wordstat Automatic captcha recognition
The very first thing you need to figure out: what is parsing. Perhaps you know this definition, and even if you don't, it will be easy to understand. Parsing- means to collect information from any source with subsequent data processing. If we talk about special cases, parsing in seo (in other words, parsing search results) is the collection and analysis of user request statistics.
Search engines also use scraping. So, search robots parse by analyzing web pages and entering information about them into the database of search engines.
Yandex.Wordstat is a very useful service in SEO. But it is possible to work with it only if you have a Yandex account. It allows you to select keywords based on user requests in order to further compose a semantic core from them.
First of all, you need to determine the topic. What do you sell? What services do you provide? Having determined your topic and what you will request, you can start using Wordstat.
Enter your query in the search bar. And expand it with the returned results.
The results are generated in two columns. The number next to the query is the predicted number of impressions per month that can be received by selecting the query you like with the keyword. The forecast is for the last 30 days before the statistics update date.
You can configure the issue to be shown by region. If you provide services only in Moscow, select the "All regions" tab (it is located just below the search bar) and customize it for yourself.
In the left column, all the phrases with the words of your query, and the words in it are sorted in descending order by the frequency of impressions. It is important for you to immediately highlight those extended key options that will be targeted for your project. Target - these are the requests by which a user entering a query into a search engine can find what he needs on your site. Target phrases will be more low-frequency, and users who come from them from the issue will be able to find what they wanted, which means they will not leave your site immediately. These visitors are important to you, because it is they who can perform the target action - buy a product or order a service.
Check the selected phrases - exclude those whose frequency is close to zero. To do this, use the “ “ (quotation marks) operator.

Then go to the right column.
The right column shows queries similar to yours. Having collected the necessary, do not forget to check the phrases with the operator “ “ (quotation marks).

Having typed a sufficient number of key phrases, you proceed to the next step: divide the phrases by frequency. This completes your work with Wordstat.
For some keywords, Wordstat gives incorrect information. How to check it? Go to the Request History tab and take a look at the statistics.
Statistics readings are presented in 2 graphs: absolute and relative.

Absolute indicator- This is the actual value of impressions in different periods of time. And the relative indicator is the ratio of impressions for the query of interest to the total number of impressions in the network. It demonstrates the popularity of the request among all others.
If the graph of the relative value is higher than the absolute value, then, perhaps, the request is being automatically boosted, or the interest in the request is above the norm. Perhaps it has to do with the season. So the demand for skis is higher in winter.
The parsing process can be automated. In this case, it is possible to use not only paid and free programs, but also browser extensions.
1. Yandex Wordstat Assistant browser extension. Install it in your browser, and when working with Yandex.Wordstat, a panel will appear on the left in which you can collect your favorite keywords.

2.Key Collector- the program is paid, but highly functional.
- There is a tab "Yandex.Wordstat" in the settings. By clicking on it, you can set the parsing depth. So you can collect more keys. But it is recommended to set 0 so as not to increase the time. And the keys can be expanded in another way, and it will take less time to collect them. The maximum number of pages for parsing in Yandex.Wordstat is 40. Each page contains up to 50 phrases. Thus, the maximum number of results for one phrase in Wordstat is 2000. And if you want to collect more data, you need to expand the input list of words by adding qualifying words. For example, not just “cabbage”, but “cauliflower”, “cabbage production”, etc.;
If you have a large project with a semantic core for several hundred or thousands of queries, you will agree that sitting in Wordstat and selecting them manually will seem like sophisticated torture. It is good that there are assistant programs that can take on the bulk of the routine work. One of these programs is called Slovoeb.
What is Slovoeb
Slovoeb- free (and significantly reduced in functionality) version of the program, which is loved by professional optimizers. Most of the functions of KeyKolletor are unlikely to be needed by an ordinary user, so you can get by with Slovoeb to solve the main task - the selection of keywords.
By the way, the paid KeyCollector allows you to parse words from Google AdWords as well - this is especially useful if your site is primarily focused on countries where Google provides the main traffic. Free Slovoeb is limited to Yandex only.
First you need to download the Slovoeb program. You can do this by following the link in the SEOM.info blog.
The program does not require installation. Just unzip the archive to any convenient location on your computer and run Slovoeb.exe. In the future, all your settings will be stored in the selected folder. Before you start, do not forget to read the material about - the information in the article is also relevant for this program.
Setting up Slovoeb
Here is what we will see after launch:
Before you get started, you need to make a number of settings. The first is to specify Yandex accounts for keyword parsing. I remind you that you can work in Wordstat only after authorization. Therefore, I advise, about five accounts specially designed for Slovoeb. Do not use special characters inpasswords of these accounts!
I do not advise you to use your real account, since the program makes a lot of requests to Yandex per unit of time, for which you can get sanctions.
Click on the gear icon in the upper left part of the program window and go to settings.
Select the Yandex.Direct tab and enter your account information in the format Login: Password. You can also specify a proxy if you wish. Be sure to read the memo in the settings window!

I advise you to study and change other software settings.
Automatic captcha recognition
The next step is to automate captcha recognition. Agree, what's the point in the program if every time it requires you to manually enter the captcha issued by Yandex. Since Slovoeb will send requests to Yandex many times in a short period of time, captchas are inevitable.
I am using the service Antigate. You can use other programs if you wish. Slovoeb supports the following:
- Antigate
- captchabot
- RIPCaptcha
- enCaptcha
- SocialLink
Many of them I had never heard of before.
In the case of Antigate, there is a nuance: they have moved to a new site (although the old one is still available). They use a common database, so both sites have a single account. Which one to register is up to you. The first one is more classic, spartan, more familiar to experienced webmasters. The second one is more modern.
Please note that Antigate is paid. But inexpensive. I have enough 1 dollar for 2 months of work (or even more).
Go to the anti-captcha settings page by clicking on the tab on the left side of the settings window.
In field Antigate Key enter your anti-captcha key. You can get it in your Antigate profile settings.

This completes the basic setup of Slovoyob.
Keyword selection with Slovoeb
It's time to proceed directly to the selection of requests. To do this, you need to create a new project. All data will be saved to a file. There can be an unlimited number of such files, so you can easily switch between projects.
Click on the "Create Project" button:
In the window that opens, choose where to save the file and how to name it. I usually name the files by the name of the site and save them to the project folder (where all the other data on it is). Someone keeps all Slovoeb's files in a single folder. Who is more comfortable.
The next step after creating the project is setting up the region. If your site is focused only on a certain region (or regions), you need search query statistics for it, and not for the whole world. Click on the region selection button and check the boxes you need.
Here everything is the same as in the Wordstat interface:

It's time for keyword research!
Click on the " Batch collection of requests from the left column of Yandex.Wordstat“ as shown in the screenshot.
In the window that opens, enter the keywords on the basis of which you want to search for queries. Everything is exactly the same as in the Wordstat interface. The main difference is that in the program you can enter several words at once, and the program will work with them in turn, while in Wordstat you need to work with each word in turn, manually, which significantly increases the time of work.

Click on the “ Start collecting“. Hurray, now you can go make coffee or switch to other tasks. It will take time for the wordfuck to collect requests.
Stop words
After the program has parsed the keywords, it is necessary to filter them, discarding combinations and formulations that are not of interest to us. This can be done using stop words. Click on the big button Stop words” with the image of a shield. In the window that opens, click on the “ Add to list“. In another window that opens, list the stop words (each on a new line) that should not be in your search query. For example, we are not interested in requests with the words “download”, “torrent”, “new version”, “latest version”, etc., since we do not distribute the program itself, but only its description.
After entering the stop words, click on the “ Mark phrases in the table” in the lower left corner of the stop words window.
Working with frequency in Slovoeb
There is one nuance left: the frequency of requests displayed in the column is the base frequency, that is, a phrase with all word forms. To determine the frequencies using operators, click on the magnifying glass button and select “ Collect frequencies of the form ” ” “.
Keyword parser is a Datacol setting that automatically collects queries from service statistics wordstat by user-specified keywords. Thus, you only need to set the base keywords, after which Datacol will independently collect information on derived queries. Along with requests, the frequency of impressions of each request per month is stored. When parsing, Datacol goes through all the pages of the Wordstat issue.
- With the help of a parser wordstat You can collect requests and display frequency from statistics;
- You only need to provide a list of keywords for which you need to collect data;
- Save the collected information in any convenient format ( Excel, TXT, WordPress, MySQL etc.).
Parsing Wordstat implies the processing of Javascript, as well as the need for authorization to collect data. We get this opportunity thanks to the plugin. When launching a campaign Datacol will open one or more browser instances Chrome to download web pages through them. Number of running instances Chrome equals the number of campaign threads. Note that browser instances may take some time to initialize.
By whom and for what purpose is the Yandex keyword parser used?
The keyword parser is most often used by search engine promotion specialists. In particular, this concerns the implementation of the task of compiling the semantic core of the site. We will make a reservation that below we will talk about the promotion of sites in Runet. In this context, the Yandex Direct keyword parser is more relevant.
Direct search query parser
First, let's describe the standard scheme of the direct parser.
1.
The user specifies the search queries whose derivatives are to be collected.
2.
The parser logs in to Yandex and starts parsing Yandex WordStat for each request in turn.
3.
For each request, derived keywords are obtained not only from the first page of the direct issuance, but also from all subsequent ones.
As a result, at the output we have a fairly large number of keyword options, which are further used to form the semantic core of the site.
Keywords and impressions parser - “slippery moment”
Note that in addition to keywords, we get the so-called “predicted number of impressions” - an indicator that should be treated very carefully. To begin with, let's figure out what Yandex itself writes about this value:
The results display statistics of queries from the Yandex search engine containing a given word or phrase, and other queries made by people who searched for it (on the right).
The numbers next to each query in the results of Wordstat give a preliminary forecast of the number of impressions per month that you will have by selecting this query as a keyword.
The mistake of many optimizers is that they read only the first part of the description, and at the same time they do not read very carefully. Go ahead:
The number next to the word "TV" indicates the number of impressions for absolutely all queries that include the word "TV": "buy a TV", "Plasma TV", "Buy a plasma TV", "Buy a new plasma TV", etc.
Have you already guessed what we are hinting at? So, you should understand the main thing - when parsing derived queries according to Wordstat, you should not pay attention to their frequency indicator, since this value is summed from the frequencies of all derived queries.
But how, in this case, to determine which keywords are more “fat” and which are less? Let's immediately debunk the erroneous opinion that derivative keywords always have fewer real impressions than the main ones. This is blatant nonsense! Quote operators will allow us to find the real number of impressions of keywords (minus the number of impressions of derivatives). Thus, to search for queries and determine the most “fat” ones, it is necessary to apply the following scheme:
1.
Run a key parser to search for derivatives.
2.
Take all derived queries and parse the number of impressions for each one by specifying the query in quotes.
We agree that this is a somewhat longer and more difficult path. However, imagine the situation. You have about 500 requests for which you want to promote the main site. 30 of them are (in your initial opinion, that is, according to the originally parsed Wordstat statistics) the most high-frequency. Then you spend 3 months of time and several thousand killed raccoons (yes, guys - high-quality promotion is an expensive and long-term event) and in the end it turns out that search traffic is several times less than expected. You are very upset, look for a professional promotion specialist and he opens your eyes to the fact that you promoted completely different queries that drive traffic (in particular, he shows you real statistics on queries in quotes).
Testing the Query Parser
On our site you can download the Yandex keyword parser for free and test it. We can also discuss setting up the key parser, which will check the values of the collected requests in quotes.
Testing the Wordstat parser
To test work Wordstat parser:
Step 1. Install . The demo version of the program has all the features of the paid one, but saves only first 25 results parsing.
Step 2 There is a campaign in the campaign tree seo-parsers/wordstat-keywords-parser.par. Select it and click the button Launch (Play). Before launch, you can edit Input data to change the base set requests for which statistics will be collected.

click on image to enlarge
Download archive with parserAfter launching the campaign, a browser window opens, in which you need to enter authorization data to access Wordstat statistics.
This parser collects keywords and frequency in an excel file from the Yandex wordstat service.
If your frequent tasks include collecting statistics on keywords from the yandex vodstat service, then one of the ways to optimize the workflow is to delegate the task of parsing keywords to the parser.
This parser is not original in functionality, but original in ease of settings and getting data by keywords.
The functionality of this parser allows you to collect keywords from the wordstat.yandex.ru service, statistics on the request for collected keys, the exact frequency of keys, and also ungroup the collected keys into clusters.
Parser settings:
1. Login from yandex.ru - in this field you must enter the address of your mailbox from Yandex mail
2. Password from yandex.ru - in this field you must enter the password from your mail on Yandex
3. File with keywords - this field specifies a file with a list of keywords (the file must be saved in utf-8 format, each key on a new line), if you plan to activate query clustering after collection, then this file should contain only 1 basic passphrase (all words in lower case only (small letters))
4. File with negative keywords - this field contains a file with a list of negative keywords (the file must be saved in utf-8 format, each negative keyword on a new line)
5. Depth of taking - to what depth to parse
6. Explore results - this option activates the query clustering stage, after the keys are collected for the base phrase (by activating this option, you must specify the file to save the research)
7. Check for the exact frequency - this option activates the collection of the exact frequency from the collected keys
8. Deep scan - this option activates deep scan
9. Key for captcha - optional
10. File for saving keys - an excel file in which keywords from the wordstat.yandex.ru service will be saved
11. File for saving the study - an excel file in which grouped clusters will be saved after clustering
If you have any questions or wishes - write to the mail [email protected]
skype - vipvodu
Download archive with parser
An example of a file with clusters by key is the customer base.
Adviсe:
1. Carefully check the settings before starting.
2. If the program, after pressing the button - run - turns off - then most likely, something is wrong with the settings, or there are hanging processes after the previous interrupted parsing, the hanging processes must either be killed in the task manager or restart the computer.
3. Do not interrupt parsing, wait for the inscription - All data is saved
Yandex Wordstat is a Yandex service used to select keywords by analyzing user search queries.
Why you need Wordstat
It is mainly used to compose the semantic core. Wordstat is free, it is a powerful tool, but so simple that even a beginner can figure it out. With the help of Wordstat, it is possible to find out detailed statistics of requests in the Yandex system for the last month, and to compile not only the structure of the whole site, but also its individual pages. In practice, the service is used to solve the following problems:
- Collection of the most complete semantics due to query extensions;
- Checking the frequency of requests, including regional ones;
- Checking the seasonality of requests.
This is the most basic, but of course there are smaller tasks that Wordstat helps to solve.
How to use Wordstat correctly
First you need to register there. Here is a link to the service, you can enter words in it without registration, but you can find out the results only after registration. Otherwise it will pop up something like this:
It is also important that your Yandex profile indicates your region, for which you are going to view query statistics. Otherwise, if you look for how many customers for your business enter the word “fishing rods” in your Nizhny Vasyuki, and you have the Moscow region, then you may be given that hundreds of thousands of people are looking for fishing rods. You will buy a hundred thousand of them, and in the Lower Vasyuki only a couple of cripples are looking for them.
After registering, enter the word there and click the "Pick up" button. You will get results like this:

As you can see, we entered the word "brother", and in the left column there will be requests in which the phrase "brother" is present. These queries are entered by real users. In the right column are similar queries. The numbers next to each request are their frequency (that is, how often users enter them). But this is not an exact frequency, but an approximate one. That is, the phrase “brother” itself in this form may have been entered 20 times in total (that is, the exact frequency of it is 20 then), but together with the phrases “brothers”, “brothers 90”, “come on brother” and others, it has a frequency of 27 080. We will learn to determine the exact frequency further.
Basically, they work with Wordstat through special services and programs. Thousands of them! The most famous is Kay Collector. All these programs increase the convenience of working with this tool at times.
They rarely work directly with Wordstat, but I heard awesome stories that in Ashmanov's studio, one of the coolest SEO studios, there are monkeys who manually enter each request into Wordstat and copy the output to a .txt file. I immediately presented a hundred slaves who do the same amount of work per day as one SEO with Kay Collector.
Let's now look at the rest of the interface functions:
Block 1- switch between device type. I personally don't use. I make my sites convenient for all types of devices.
In block 2 is a very useful switch. With its help, you can see, firstly, the regionality of the request (in which region it is entered more often, in which less often). You can seriously get stuck on this tool. And secondly, here you can see the "History of the request" - and this is really sometimes very necessary to determine the seasonality of the request and to track the trend.
In block 3— the date when Yandex last updated statistics on requests. In most cases, we don't need it.
Block 4- select the region / regions.
By region
You can see what they are looking for. Funny thing. Here, for example, you can find out that thieves' songs, on average per capita, are most searched for in the Russian Federation, and in Greece and still in Israel:

And if you click on Russia, you will see that blatnyak is in demand everywhere, but especially in Dagestan:

Request History
In the query history, you can define seasonal queries and trends, as I said. For example, we can only envy those webmasters who managed to write articles about Trump, because now (the end of 2016) they started to grow traffic:

But the most professional begins when you work with operators.
What operators are useful when working with Wordstat
You need to know how to use Yandex Wordstat operators in order to work most efficiently in the interface.
Basic Operators
The two basic operators are the exclamation word and quotation marks. This is the basics of the basics.
Look, without them, we have 25,655 impressions. These are displays of all phrases with the word "brother".

With quotes, only 832. Quotes fix the phrase. This means that 832 impressions are for the phrases “brother”, “brother”, “brother”, taken together, that is, for this phrase with a different word order and endings, but without adding other words to this phrase. That is, it does not include displays of the phrases “we are brothers”, “we failed brother”, and so on.

With an exclamation mark - 7409 impressions. It fixes the word form. That is, this includes displays of the phrases “brother”, “nishtyak brother”, “hold on brother” and others with the same ending. And the phrases “call a brother”, “download a song about a brother”, and so on, are not included.

And here we have only 152 impressions. This is because with an exclamation point and quotation marks, only impressions of this phrase and only in this form are counted. But with a different word order in the phrase. That is, if we enter “nishtyak bro”, then Wordstat will show us the sum of the impressions “nishtyak bro” and “brother nishtyak”.

Auxiliary operators
Plus. The "+" symbol forces stopwords to be taken into account. By default, Wordstat does not take into account prepositions, and for the query "how to buy a TV" it will show you mostly commercial queries:
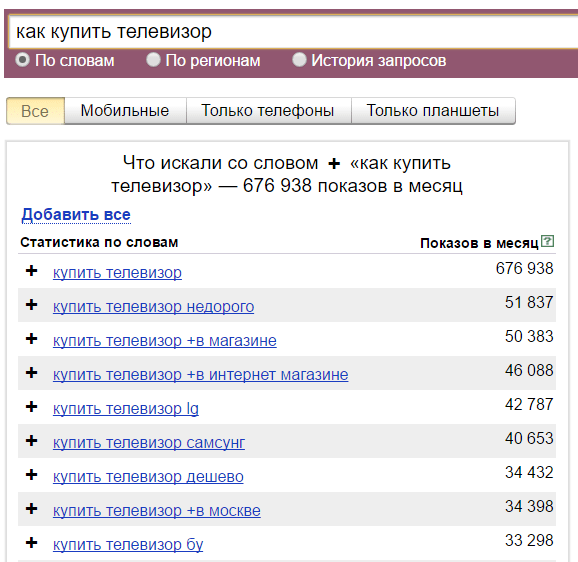
If the “how” particle is important to you, then fix it with a plus and Wordstat will already give the following data:

"OR" operator. Forward slash "|" - if two phrases are separated by this operator, it will show all variations with these two phrases.
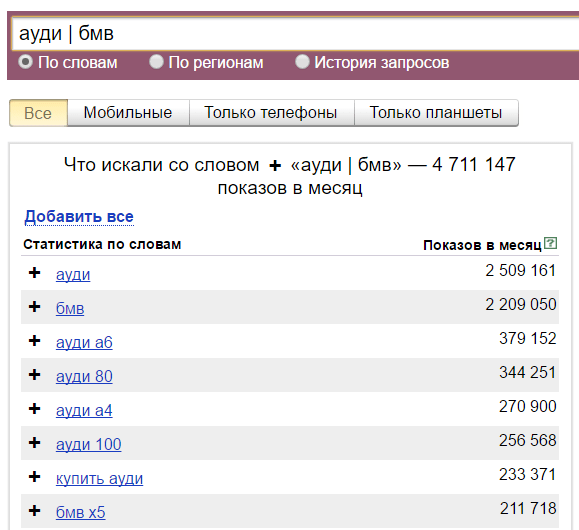
By the way, it allows you to compare two queries, for this I mainly use it.
Minus. The "-" character excludes a specific word from the query. Example: "buy a car in Moscow -bu". Requests without the use of the word "boo" will be shown.

Parentheses "()" - Groups the use of multiple operators.

Square brackets "" - fixes the sequence of words in the search phrase. This operator was introduced not so long ago. That is, we get the opportunity to find out with what word order the phrase is entered most often:

As you can see, almost no one enters the phrase with the wrong order:

Plugins
Working with bare Yandex Wordstat is generally inconvenient. To make your work easier, you can install a special plugin in your browser designed to work in Wordstat. Plugins for Chromium browsers (Yandex, Mail, Amigo, Opera and Google Chrome) are the same, but for Mozilla there is a separate plugin, everything is free and available for download, you can install them directly from the browser. The most popular are Wordstat Assistant and Yandex Wordstat Helper plugins.
Yandex Wordstat Assistant
Perhaps the best plugin for wordstat.yandex.ru. I myself use it. It's easy to use, practical, and doesn't get in the way when you're working on other sites. The installed wordstat assistant is launched only if you go to the Wordstat page. By clicking on the plus signs, the required keyword can be added to the list (it is located on the left). The assistant has the ability to sort the selected keywords, and delete unnecessary ones. The resulting list is simply copied to the clipboard, and transferred to Excel for further processing. By the way, the convenience of using the plugin also lies in the fact that when you add phrases already there to the list, duplicates are automatically removed, which significantly reduces the work.
Yandex Wordstat Helper
This plugin is simpler than the previous one, but no less popular, it can also be installed directly from the browser. The helper is made in the form of a widget that is added to the wordstat page immediately after installation, you just need to refresh the page and you can start working. Its functions:
- Possibility of automatic sorting in alphabetical order;
- Checks for duplicates, removing the latest;
- It is possible to process different requests in several browser tabs. The necessary words are added to the same list;
- There is a word counter;
- The ability to copy a ready-made list to Excel, putting everything together according to the initial phrases.
Before deciding which plugin to use, try both in action, this will allow you to make the right choice.
Wordstat parsers
To save time when selecting keywords, they often use automatic programs specially designed for this purpose - parsers, which can be both paid and free.
Some guys order parsers and purely for their needs.
The best paid Wordstat parser is KeyCollector. It is mainly used by those who are professionally involved in compiling semantics. The free analogue of KeyCollector is the Slovoeb program. Its functions are cut down, but it is quite possible to compose small kernels with its help.
Magadan is also a fairly popular Wordstat parser, which can also be downloaded for free. It selects and analyzes requests, there is support for regions, it is designed for parsing Yandex Direct phrases.
In the end, I want to note that Wordstat provides only the data that Yandex has. Therefore, for example, the frequency in Google and other search engines can be completely different.
 How to reinstall Windows: step by step instructions
How to reinstall Windows: step by step instructions Programs that optimize computer performance
Programs that optimize computer performance Download and install all the necessary programs at the same time
Download and install all the necessary programs at the same time