Hyper threading technology. Once again about Hyper Threading
Hyper-Threading technology (HT, hyperthreading) first appeared 15 years ago - in 2002, in Pentium 4 and Xeon processors, and since then has appeared in Intel processors (in the Core i line, some Atom, and recently also in Pentium), then disappeared (its support was not in the Core 2 Duo and Quad lines). And during this time, it has acquired mythical properties - they say its presence almost doubles the processor’s performance, turning weak i3s into powerful i5s. At the same time, others say that HT is a common marketing ploy and is of little use. The truth is, as usual, in the middle - in some places there is some sense from it, but you definitely shouldn’t expect a two-fold increase.
Technical description of the technology
Let's start with the definition given on the Intel website:
Intel® Hyper-Threading Technology (Intel® HT) enables more efficient use of processor resources by allowing multiple threads to run on each core. In terms of performance, this technology increases the throughput of processors, improving the overall performance of multi-threaded applications.
In general, it is clear that nothing is clear - just general phrases, but they briefly describe the technology - HT allows one physical core to simultaneously process several (usually two) logical threads. But how? Processor supporting hyperthreading:
- can store information about several running threads at once;
- contains one set of registers (that is, fast memory blocks inside the processor) and one interrupt controller (that is, a built-in processor unit responsible for the ability to sequentially process requests for the occurrence of any event that requires immediate attention from different devices) for each logical CPU.

Let's say the processor has two tasks. If the processor has one core, then it will execute them sequentially, if two, then in parallel on two cores, and the execution time of both tasks will be equal to the time spent on the heavier task. But what if the processor is single-core, but supports hyperthreading? As you can see in the picture above, when performing one task, the processor is not 100% busy - some processor blocks are simply not needed in this task, somewhere the branch prediction module is making an error (which is needed to predict whether a conditional branch will be executed in the program), somewhere there is a cache access error - in general, when executing a task, the processor is rarely more than 70% busy. And the HT technology just “shoves” a second task into unoccupied processor blocks, and it turns out that two tasks are processed simultaneously on one core. However, doubling performance does not happen for obvious reasons - very often it turns out that two tasks need the same computing unit in the processor, and then we see a simple one: while one task is being processed, the execution of the second one simply stops at this time (blue squares - the first task, green - second, red - tasks accessing the same block in the processor):

As a result, the time spent by a processor with HT on two tasks turns out to be more than the time required to calculate the heaviest task, but less than the time required to sequentially evaluate both tasks.
Pros and cons of technology
Taking into account the fact that the processor die with HT support is physically larger than the processor die without HT by an average of 5% (this is how much additional register blocks and interrupt controllers take up), and HT support allows you to load the processor by 90-95%, then compared to 70 % without HT we get that the increase at best will be 20-30% - the figure is quite large.
However, not everything is so good: it happens that there is no performance gain from HT at all, and it even happens that HT worsens the performance of the processor. This happens for many reasons:
- Lack of cache memory. For example, modern quad-core i5s have 6 MB of L3 cache - 1.5 MB per core. In quad-core i7s with HT, the cache is already 8 MB, but since there are 8 logical cores, we get only 1 MB per core - during calculations, some programs may not have enough of this volume, which leads to a drop in performance.
- Lack of software optimization. The most basic problem is that programs consider logical cores to be physical, which is why when executing tasks in parallel on one core, delays often occur due to tasks accessing the same computational unit, which ultimately reduces the performance gain from HT to nothing.
- Data dependency. It follows from the previous point - to complete one task, the result of another is required, but it has not yet been completed. And again we get downtime, a reduction in CPU load and a small increase from HT.
There are many of them, because for HT calculations this is manna from heaven - heat dissipation practically does not increase, the processor does not become much larger, and with proper optimization you can get an increase of up to 30%. Therefore, its support was quickly implemented in those programs where it is easy to parallelize the load - in archivers (WinRar), programs for 2D/3D modeling (3ds Max, Maya), programs for photo and video processing (Sony Vegas, Photoshop, Corel Draw) .
Programs that do not work well with hyperthreading
Traditionally, this is the majority of games - they are usually difficult to parallelize competently, so often four physical cores at high frequencies (i5 K-series) are more than enough for games, parallelizing which with 8 logical cores in i7 turns out to be an impossible task. However, it is also worth considering that there are background processes, and if the processor does not support HT, then their processing falls on the physical cores, which can slow down the game. Here the i7 with HT wins - all background tasks traditionally have a lower priority, so when running simultaneously on one physical core of the game and a background task, the game will receive increased priority, and the background task will not “distract” the cores busy with the game - that’s why For streaming or recording games, it is better to take an i7 with hyperthreading.
Results
Perhaps there is only one question left here - does it make sense to take processors with HT or not? If you like to keep five programs open at the same time and play games at the same time, or are engaged in photo processing, video or modeling - yes, of course it’s worth taking. And if you are used to closing all others before launching a heavy program, and do not dabble in processing or modeling, then a processor with HT is of no use to you.
15.03.2013
Hyper-Threading technology appeared in Intel processors, scary to say, more than 10 years ago. And at the moment it is an important element of Core processors. However, the question of the need for HT in games is still not completely clear. We decided to conduct a test to understand whether gamers need a Core i7, or if a Core i5 is better. And also find out how much better Core i3 is than Pentium.
Hyper-Threading Technology, developed by Intel and exclusively used in the company's processors, starting with the memorable Pentium 4, is something that is taken for granted at the moment. A significant number of processors of current and previous generations are equipped with it. It will be used in the near future.
And it must be admitted that Hyper-Threading technology is useful and has a positive effect on performance, otherwise Intel would not use it to position its processors within the line. And not as a secondary element, but one of the most important, if not the most important. To make it clear what we are talking about, we have prepared a table that makes it easy to evaluate the principle of segmentation of Intel processors.

As you can see, there are very few differences between the Pentium and Core i3, as well as between the Core i5 and Core i7. In fact, the i3 and i7 models differ from the Pentium and i5 only in the size of the third level cache per core (not counting the clock frequency, of course). The first pair has 1.5 megabytes, and the second pair has 2 megabytes. This difference cannot fundamentally affect the performance of processors, since the difference in cache size is very small. That is why Core i3 and Core i7 received support for Hyper-Threading technology, which is the main element that allows these processors to have a performance advantage over Pentium and Core i5, respectively.
As a result, a slightly larger cache and Hyper-Threading support will allow significantly higher prices for processors. For example, processors of the Pentium line (about 10 thousand tenge) are approximately two times cheaper than Core i3 (about 20 thousand tenge), and this despite the fact that physically, at the hardware level, they are absolutely identical, and, accordingly, have the same cost . The price difference between Core i5 (about 30 thousand tenge) and Core i7 (about 50 thousand tenge) is also very large, although less than two times in younger models.

How justified is this increase in price? What real gain does Hyper-Threading provide? The answer has long been known: the increase varies, it all depends on the application and its optimization. We decided to check what HT can do in games, as one of the most demanding “household” applications. In addition, this test will be an excellent addition to our previous material on the effect of the number of cores in the processor on gaming performance.
Before moving on to the tests, let's remember (or find out) what Hyper-Threading Technology is. As Intel itself said when introducing this technology many years ago, there is nothing particularly complicated about it. In fact, all that is needed to introduce HT at the physical level is to add not one set of registers and an interrupt controller to one physical core, but two. In Pentium 4 processors, these additional elements increased the number of transistors by only five percent. In modern Ivy Bridge cores (as well as Sandy Bridge and future Haswell), the additional elements for even four cores do not increase the die by even 1 percent.

Additional registers and an interrupt controller, coupled with software support, allow the operating system to see not one physical core, but two logical ones. At the same time, the processing of data from two streams that are sent by the system still occurs on the same core, but with some features. One thread still has the entire processor at its disposal, but as soon as some CPU blocks are freed and idle, they are immediately given to the second thread. Thanks to this, it was possible to use all processor blocks simultaneously, and thereby increase its efficiency. As Intel itself stated, the performance increase under ideal conditions can reach up to 30 percent. True, these indicators are true only for the Pentium 4 with its very long pipeline; modern processors benefit from HT less.
But ideal conditions for Hyper-Threading are not always the case. And most importantly, the worst result of HT is not the lack of performance gain, but its decrease. That is, under certain conditions, the performance of a processor with HT will drop relative to a processor without HT due to the fact that the overhead of thread division and queuing will significantly exceed the gain from processing parallel threads, which is possible in this particular case. And such cases occur much more often than Intel would like. Moreover, many years of using Hyper-Threading have not improved the situation. This is especially true for games that are very complex and not at all standard in terms of data calculation and applications.
In order to find out the impact of Hyper-Threading on gaming performance, we again used our long-suffering Core i7-2700K test processor, and simulated four processors at once by disabling cores and turning HT on/off. Conventionally, they can be called Pentium (2 cores, HT disabled), Core i3 (2 cores, HT enabled), Core i5 (4 cores, HT disabled), and Core i7 (4 cores, HT enabled). Why conditional? First of all, because according to some characteristics they do not correspond to real products. In particular, disabling cores does not lead to a corresponding reduction in the volume of the third level cache - its volume for all is 8 megabytes. And, in addition, all our “conditional” processors operate at the same frequency of 3.5 gigahertz, which has not yet been achieved by all processors in the Intel line.

However, this is even for the better, since thanks to the constant change of all important parameters, we will be able to find out the real impact of Hyper-Threading on gaming performance without any reservations. And the percentage difference in performance between our “conditional” Pentium and Core i3 will be close to the difference between real processors, provided the frequencies are equal. It should also not be confusing that we are using a processor with Sandy Bridge architecture, since our efficiency tests, which you can read about in the article “Bare Performance - Examining the Efficiency of ALUs and FPUs,” showed that the influence of Hyper-Threading in the latest generations of processors Core remains unchanged. Most likely, this material will also be relevant for upcoming Haswell processors.
Well, it seems that all the questions regarding the testing methodology, as well as the operating features of Hyper-Threading Technology, have been discussed, and therefore it’s time to move on to the most interesting thing - the tests.
Even in a test in which we studied the impact of the number of processor cores on gaming performance, we found that 3DMark 11 is completely relaxed about CPU performance, working perfectly even on one core. Hyper-Threading had the same “powerful” influence. As you can see, the test does not notice any differences between Pentium and Core i7, not to mention intermediate models.

Metro 2033
But Metro 2033 clearly noticed the appearance of Hyper-Threading. And she reacted negatively to him! Yes, that's right: enabling HT in this game has a negative impact on performance. A small impact, of course - 0.5 frames per second with four physical cores, and 0.7 with two. But this fact gives every reason to say that the Metro 2033 Pentium is faster than the Core i3, and the Core i5 is better than the Core i7. This is confirmation of the fact that Hyper-Threading does not show its effectiveness always and not everywhere.

Crysis 2
This game showed very interesting results. First of all, we note that the influence of Hyper-Threading is clearly visible in dual-core processors - the Core i3 is ahead of the Pentium by almost 9 percent, which is quite a lot for this game. Victory for HT and Intel? Not really, since the Core i7 did not show any gain relative to the noticeably cheaper Core i5. But there is a reasonable explanation for this - Crysis 2 cannot use more than four data streams. Because of this, we see a good increase in the dual-core with HT - still, four threads, albeit logical, are better than two. On the other hand, there was nowhere to put additional Core i7 threads; four physical cores were quite enough. So, based on the results of this test, we can note the positive impact of HT in the Core i3, which is noticeably better than the Pentium here. But among quad-core processors, the Core i5 again looks like a more reasonable solution.

Battlefield 3
The results here are very strange. If in the test for the number of cores, battlefield was an example of a microscopic but linear increase, then the inclusion of Hyper-Threading introduced chaos into the results. In fact, we can state that the Core i3, with its two cores and HT, turned out to be the best of all, ahead of even the Core i5 and Core i7. It’s strange, of course, but at the same time, Core i5 and Core i7 were again on the same level. What explains this is not clear. Most likely, the testing methodology in this game played a role here, which gives greater errors than standard benchmarks.

In the last test, F1 2011 proved to be one of the games that is very critical of the number of cores, and in this test it again surprised us with the excellent impact of Hyper-Threading technology on the performance. And again, as in Crysis 2, the inclusion of HT worked very well on dual-core processors. Look at the difference between our conditional Core i3 and Pentium - it is more than twofold! It is clearly visible that the game is very much lacking two cores, and at the same time its code is parallelized so well that the effect is amazing. On the other hand, you can’t argue with four physical cores - Core i5 is noticeably faster than Core i3. But the Core i7, again, as in previous games, did not show anything outstanding compared to the Core i5. The reason is the same - the game cannot use more than 4 threads, and the overhead of running HT reduces the performance of the Core i7 below the level of the Core i5.

An old warrior needs Hyper-Threading no more than a hedgehog needs a T-shirt - its influence is by no means as clearly noticeable as in F1 2011 or Crysis 2. However, we still note that turning on HT on a dual-core processor brought 1 extra frame. This is certainly not enough to say that Core i3 is better than Pentium. At the very least, this improvement clearly does not correspond to the difference in price of these processors. And it’s not even worth mentioning the price difference between Core i5 and Core i7, since the processor without HT support again turned out to be faster. And noticeably faster - by 7 percent. Whatever one may say, we again state the fact that four threads is the maximum for this game, and therefore HyperThreading in this case does not help the Core i7, but hinders.
If you carefully looked through the contents of BIOS Setup, then you may well have noticed the CPU Hyper Threading Technology option there. And you may have wondered what Hyper Threading is (or hyperthreading, the official name is Hyper Threading Technology, HTT), and what this option is for.
Hyper Threading is a relatively new technology developed by Intel for Pentium architecture processors. As practice has shown, the use of Hyper Threading technology has made it possible in many cases to increase CPU performance by approximately 20-30%.
Here you need to remember how a computer’s central processor generally works. As soon as you turn on the computer and run a program on it, the CPU begins to read the instructions contained in it, written in the so-called machine code. It reads each instruction in turn and executes them one after another.
However, many programs have several simultaneously running software processes. In addition, modern operating systems allow the user to have several programs running at once. And they don’t just allow it - in fact, a situation where a single process is running in the operating system is completely unthinkable today. Therefore, processors developed using older technologies had low performance in cases where it was necessary to process several simultaneous processes at once.
Of course, in order to solve this problem, you can include several processors or processors using several physical computing cores in the system. But such an improvement is expensive, technically complex and not always effective from a practical point of view.
Development history
Therefore, it was decided to create a technology that would allow processing multiple processes on one physical core. In this case, for programs, it will look outwardly as if there were several processor cores in the system at once.
Hyper Threading technology support first appeared in processors in 2002. These were processors of the Pentium 4 family and Xeon server processors with clock speeds above 2 GHz. Initially, the technology was codenamed Jackson, but then its name was changed to Hyper Threading, which is more understandable to the general public - which can be roughly translated as “super-threading”.
At the same time, according to Intel, the surface area of the processor crystal that supports Hyper Threading has increased compared to the previous model that does not support it by only 5%, with an average performance increase of 20%.
Despite the fact that the technology has generally proven itself well, however, for a number of reasons, Intel decided to disable Hyper Threading technology in the Core 2 family processors that replaced the Pentium 4. Hyper Threading, however, later reappeared in processors of the Sandy Bridge and Ivy architectures Bridge and Haswell, having been significantly redesigned.
The essence of technology
Understanding Hyper Threading Technology is important because it is one of the key features in Intel processors.
Despite all the success that processors have achieved, they have one significant drawback - they can only execute one instruction at a time. Let's say that you launched applications such as a text editor, a browser and Skype at the same time. From the user's point of view, this software environment can be called multitasking, however, from the processor's point of view this is far from the case. The processor core will still execute one instruction per certain period of time. In this case, the task of the processor is to distribute processor time resources between individual applications. Because this sequential execution of instructions happens extremely quickly, you don't notice it. And it seems to you that there is no delay.
But there is still a delay. The delay occurs due to the way each program supplies the processor with data. Each data stream must arrive at a specific time and be processed individually by the processor. Hyper Threading technology makes it possible for each processor core to schedule data processing and distribute resources simultaneously for two threads.

It should be noted that in the core of modern processors there are several so-called execution devices, each of which is designed to perform a specific operation on data. In this case, some of these executive devices may be idle while processing data from one thread.
To understand this situation, we can give an analogy with workers working in an assembly shop on a conveyor and processing different types of parts. Each worker is equipped with a specific tool designed to perform a task. However, if parts arrive in the wrong sequence, delays occur because some workers wait in line to start work. Hyper Threading can be compared to an additional conveyor belt that was laid in the workshop so that previously idle workers would carry out their operations independently of others. The workshop is still one, but parts are processed more quickly and efficiently, resulting in reduced downtime. Thus, Hyper Threading made it possible to turn on those processor execution units that were idle while executing instructions from one thread.
As soon as you turn on a computer with a dual-core processor that supports Hyper Threading and open Windows Task Manager under the Performance tab, you will find four graphs in it. But this does not mean that you actually have 4 processor cores.

This happens because Windows thinks that each core has two logical processors. The term "logical processor" sounds funny, but it means a processor that doesn't physically exist. Windows can send streams of data to each logical processor, but only one core actually does the work. Therefore, a single core with Hyper Threading technology is significantly different from separate physical cores.
Hyper Threading technology requires support from the following hardware and software:
- CPU
- Motherboard chipset
- operating system
Benefits of technology
Now let's consider the following question: how much does Hyper Threading technology increase computer performance? In everyday tasks, such as surfing the Internet and typing, the benefits of technology are not so obvious. However, keep in mind that today's processors are so powerful that everyday tasks rarely fully utilize the processor. In addition, a lot also depends on how the software is written. You may have multiple programs running at once, but if you look at the load graph, you will see that only one logical processor per core is being used. This happens because the software does not support the distribution of processes between cores.
However, for more complex tasks, Hyper Threading can be more useful. Applications such as 3D modeling programs, 3D games, music or video encoding/decoding programs, and many scientific applications are written to take full advantage of multithreading. So you can experience the performance benefits of a Hyper Threading-enabled computer while playing challenging games, listening to music, or watching movies. The performance increase can reach up to 30%, although there may be situations where Hyper Threading does not provide an advantage at all. Sometimes, if both threads load all processor execution units with the same tasks, a slight decrease in performance may even be observed.
Returning to the presence of a corresponding option in BIOS Setup that allows you to set Hyper Threading parameters, in most cases it is recommended to enable this function. However, you can always disable it if it turns out that your computer is running with errors or even has lower performance than you expected.
Conclusion
Since the maximum performance increase when using Hyper Threading is 30%, it cannot be said that the technology is equivalent to doubling the number of processor cores. However, Hyper Threading is a useful option, and as a computer owner, it will not hurt you. Its benefit is especially noticeable when, for example, you edit multimedia files or use your computer as a workstation for professional programs such as Photoshop or Maya.
We wrote that using single-processor Xeon systems makes no sense, since at a higher price their performance will be the same as that of a Pentium 4 of the same frequency. Now, after a more thorough study, a slight amendment will probably have to be made to this statement. Hyper-Threading technology, implemented in Intel Xeon with the Prestonia core, really works and gives a very noticeable effect. Although many questions arise when using it...
You give productivity
"Faster, even faster..." The race for performance has been going on for years, and sometimes it’s even difficult to say which computer component is accelerating faster. To achieve this, more and more new methods are being invented, and the further, the more qualified labor and high-quality brains are invested in this avalanche-like process.
A constant increase in performance is certainly necessary. At the very least, this is a profitable business, and there is always a nice way to encourage users to yet another upgrade from yesterday’s “super-efficient CPU” to tomorrow’s “even more super…”. For example, simultaneous speech recognition and simultaneous translation into another language - isn’t this the dream of everyone? Or unusually realistic games of almost “cinema” quality (wholly absorbing attention and sometimes leading to serious changes in the psyche) - isn’t this the desire of many gamers, young and old?
But in this case, let's take the marketing aspects out of the equation and focus on the technical ones. Moreover, not everything is so gloomy: there are pressing tasks (server applications, scientific calculations, modeling, etc.), where increasingly higher performance, in particular of central processors, is really necessary.
So, what are the ways to increase their performance?
Boost clock speed. It is possible to further “thinner” the technological process and increase the frequency. But, as you know, this is not easy and is fraught with all sorts of side effects, such as problems with heat generation.
Increasing CPU resources- for example, increasing the cache volume, adding new blocks (Execution Units). All this entails an increase in the number of transistors, a more complex processor, an increase in the chip area, and, consequently, cost.
In addition, the previous two methods, as a rule, do not provide a linear increase in productivity. This is well known in the Pentium 4: errors in branch prediction and interrupts cause a long pipeline to be reset, which greatly affects overall performance.
Multiprocessing. Installing multiple CPUs and distributing work between them is often quite effective. But this approach is not very cheap - each additional processor increases the cost of the system, and a dual motherboard is much more expensive than a regular one (not to mention boards that support four or more CPUs). Additionally, not all applications benefit from multiprocessing in performance enough to justify the cost.
In addition to “pure” multiprocessing, there are several “intermediate” options that can speed up application execution:
Chip Multiprocessing (CMP)- two processor cores are physically located on one chip, using a common or separate cache. Naturally, the crystal size turns out to be quite large, and this cannot but affect the cost. Note that several of these "dual" CPUs can also operate in a multiprocessor system.
Time-Slice Multithreading. The processor switches between program threads at fixed intervals. The overhead can sometimes be quite significant, especially if a process is waiting.
Switch-on-Event Multithreading. Switching tasks when long pauses occur, for example, cache misses, a large number of which are typical for server applications. In this case, the process waiting to load data from relatively slow memory into the cache is suspended, freeing up CPU resources for other processes. However, Switch-on-Event Multithreading, like Time-Slice Multithreading, does not always achieve optimal use of processor resources, in particular due to errors in branch prediction, instruction dependencies, etc.
Simultaneous Multithreading. In this case, program threads are executed on one processor "simultaneously", that is, without switching between them. CPU resources are distributed dynamically, according to the principle “if you don’t use it, give it to someone else.” It is this approach that forms the basis of Intel Hyper-Threading technology, which we now consider.
How Hyper-Threading Works
As you know, the current “computing paradigm” involves multi-threaded computing. This applies not only to servers, where such a concept exists initially, but also to workstations and desktop systems. Threads can belong to the same or different applications, but almost always there are more than one active threads (to verify this, just open the Task Manager in Windows 2000/XP and turn on the display of the number of threads). However, a typical processor can only execute one of the threads at a time and is forced to constantly switch between them.
For the first time, Hyper-Threading technology was implemented in the Intel Xeon MP (Foster MP) processor, on which it was tested. Let's remember that Xeon MP, officially presented at IDF Spring 2002, uses a core related to the Pentium 4 Willamette, contains 256 KB L2 cache and 512 KB/1 MB L3 cache and supports operation in 4-processor configurations. Hyper-Threading support is also available in the workstation processor - Intel Xeon (Prestonia core, 512 KB L2 cache), which entered the market somewhat earlier than the Xeon MP. Our readers are already familiar with dual-processor configurations on Intel Xeon, so we will look at the capabilities of Hyper-Threading using these CPUs as an example - both theoretically and practically. Be that as it may, the “simple” Xeon is a more mundane and digestible thing than the Xeon MP in 4-processor systems...
The operating principle of Hyper-Threading is based on the fact that at any given time only part of the processor resources is used when executing program code. Unused resources can also be loaded with work - for example, another application (or another thread of the same application) can be used for parallel execution. In one physical Intel Xeon processor, two logical processors (LP - Logical Processor) are formed, which share the computing resources of the CPU. The operating system and applications “see” exactly two CPUs and can distribute work between them, as in the case of a full-fledged dual-processor system.
One of the goals of implementing Hyper-Threading is to allow it to run at the same speed as on a regular CPU when there is only one active thread. To do this, the processor has two main operating modes: Single-Task (ST) and Multi-Task (MT). In ST mode, only one logical processor is active and has undivided use of available resources (ST0 and ST1 modes); another LP is stopped with a HALT command. When a second program thread appears, the dormant logical processor is activated (via an interrupt) and the physical CPU is put into MT mode. Stopping unused LPs with the HALT command is assigned to the operating system, which is ultimately responsible for the same fast execution of one thread as in the case without Hyper-Threading.

For each of the two LPs, the so-called Architecture State (AS) is stored, which includes the state of registers of various types - general purpose, control, APIC and service. Each LP has its own APIC (interrupt controller) and a set of registers, for correct operation of which the concept of Register Alias Table (RAT) is introduced, which tracks the correspondence between eight general-purpose IA-32 registers and 128 registers of the physical CPU (one RAT for each LP ).

When running two threads, two corresponding sets of Next Instruction Pointers are supported. Most of the instructions are taken from the Trace Cache (TC), where they are stored in decoded form, and the two active LPs access the TC alternately, every other clock. At the same time, when only one LP is active, it gets exclusive access to the TC without clock rotation. Access to Microcode ROM occurs in a similar way. ITLB (Instruction Translation Look-aside Buffer) blocks, which are used when the necessary instructions are missing in the command cache, are duplicated and each deliver commands for its own thread. The IA-32 Instruction Decode block is shared and, in the case where instructions are required to be decoded for both threads, it services them one by one (again, every other clock). The Uop Queue and Allocator blocks are split in two, allocating half the elements to each LP. Schedulers, numbering 5, process queues of decoded commands (Uops) despite belonging to LP0/LP1 and direct commands to be executed by the required Execution Units - depending on the readiness for execution of the first and the availability of the second. Caches of all levels (L1/L2 for Xeon, as well as L3 for Xeon MP) are completely shared between two LPs, however, to ensure data integrity, entries in DTLB (Data Translation Look-aside Buffer) are equipped with descriptors in the form of logical processor IDs.
Thus, instructions from both logical CPUs can be executed simultaneously on the resources of one physical processor, which are divided into four classes:
- duplicated;
- Fully Shared;
- with element descriptors (Entry Tagged);
- dynamically partitioned (Partitioned) depending on the operating mode ST0/ST1 or MT.
However, most applications that receive acceleration on multiprocessor systems can also be accelerated on a CPU with Hyper-Threading enabled without any modifications. But there are also problems: for example, if one process is in a wait loop, it can take up all the resources of the physical CPU, interfering with the work of the second LP. Thus, performance when using Hyper-Threading can sometimes drop (up to 20%). To prevent this, Intel recommends using the PAUSE instruction (introduced in the IA-32 starting with the Pentium 4) instead of empty wait cycles. Quite serious work is also being done on automatic and semi-automatic code optimization during compilation - for example, the Intel OpenMP C++/Fortran Compilers () series of compilers have made significant progress in this regard.
Another goal of the first implementation of Hyper-Threading, according to Intel, was to minimize the increase in the number of transistors, chip area and power consumption while achieving a noticeable increase in performance. The first part of this commitment has already been fulfilled: the addition of Hyper-Threading support to the Xeon/Xeon MP increased die area and power consumption by less than 5%. We still have to check what happened with the second part (performance).
Practical part
For obvious reasons, we did not test 4-processor server systems on Xeon MP with Hyper-Threading enabled. Firstly, it is quite labor-intensive. And secondly, even if we decide on such a feat, it would still be absolutely impossible to get this expensive equipment now, less than a month after the official announcement. Therefore, it was decided to limit ourselves to the same system with two Intel Xeon 2.2 GHz on which the first testing of these processors was carried out (see the link at the beginning of the article). The system was based on a Supermicro P4DC6+ motherboard (Intel i860 chipset), contained 512 MB RDRAM memory, a video card on a GeForce3 chip (64 MB DDR, Detonator 21.85 drivers), a Western Digital WD300BB hard drive and 6X DVD-ROM; Windows 2000 Professional SP2 was used as the OS.
First, a few general impressions. When installing one Xeon with the Prestonia core, at system startup the BIOS displays a message about the presence of two CPUs; if two processors are installed, the user sees a message about four CPUs. The operating system normally recognizes "both processors", but only if two conditions are met.
Firstly, in the CMOS Setup, the latest BIOS versions of Supermicro P4DCxx boards now have an Enable Hyper-Threading option, without which the OS will only recognize the physical processor(s). Secondly, ACPI capabilities are used to inform the OS about the presence of additional logical processors. Therefore, to enable Hyper-Threading, the ACPI option must be enabled in CMOS Setup, and the HAL (Hardware Abstraction Layer) with ACPI support must also be installed for the OS itself. Fortunately, in Windows 2000, changing the HAL from Standard PC (or MPS Uni-/Multiprocessor PC) to ACPI Uni-/Multiprocessor PC is easy - replacing the “computer driver” in the device manager. At the same time, for Windows XP, the only legal way to switch to ACPI HAL is to reinstall the system over the existing installation.
But now all the preparations have been made, and our Windows 2000 Pro already firmly believes that it is running on a dual-processor system (although in fact there is only one processor installed). Now, traditionally, it’s time to decide on the testing goals. So we want:
- Assess the impact of Hyper-Threading on the performance of applications of various classes.
- Compare this effect with the effect of installing a second processor.
- Check how “fairly” resources are allocated to the active logical processor when the second LP is idle.
To evaluate performance, we took a set of applications already familiar to readers, used in testing workstation systems. Let's start from the end and check the “equality” of the logical CPUs. It's very simple: first we run tests on one processor with Hyper-Threading disabled, and then we repeat the process with Hyper-Threading enabled and using only one of the two logical CPUs (using Task Manager). Since in this case we are only interested in relative values, the results of all tests are brought to the “bigger is better” form and normalized (the indicators of a single-processor system without Hyper-Threading are taken as one).
Well, as you can see, Intel's promises are fulfilled here: with only one active thread, the performance of each of the two LPs is exactly equal to the performance of a physical CPU without Hyper-Threading. The inactive LP (and both LP0 and LP1) is indeed suspended, and the shared resources, as far as can be judged from the results obtained, are completely transferred for use to the active LP.

Therefore, we draw the first conclusion: two logical processors are actually equal, and enabling Hyper-Threading “does not interfere” with the work of one thread (which in itself is not bad). Let's now see if this inclusion “helps”, and if so, where and how?
Rendering. The results of four tests in the 3D modeling packages 3D Studio MAX 4.26, Lightwave 7b and A|W Maya 4.0.1 are combined into one diagram due to their similarity.

In all four cases (for Lightwave - two different scenes), the CPU load in the presence of one processor with Hyper-Threading turned off is almost always kept at 100%. Nevertheless, when Hyper-Threading is enabled, scene calculations are accelerated (as a result of which we even had a joke about the CPU load being more than 100%). In three tests, a performance increase from Hyper-Threading of 14-18% is visible - on the one hand, not much compared to the second CPU, but on the other hand, quite good, considering the “free” nature of this effect. In one of the two tests with Lightwave, the performance increase is almost zero (apparently, this is due to the specifics of this application, which is full of strange things). But there is no negative result anywhere, and a noticeable increase in the other three cases is encouraging. And this despite the fact that parallel rendering processes do similar work and probably cannot simultaneously use the resources of the physical CPU in the best way.
Photoshop and MP3 encoding. The GOGO-no-coda 2.39c codec is one of the few that supports SMP, and it has a noticeable 34% increase in performance due to dual processors. At the same time, the effect of Hyper-Threading in this case is zero (we do not consider a difference of 3% significant). But in the test with Photoshop 6.0.1 (a script consisting of a large set of commands and filters), a slowdown is visible when Hyper-Threading is enabled, although the second physical CPU adds 12% performance in this case. This is, in fact, the first case when Hyper-Threading causes a drop in performance...

Professional OpenGL. It has long been known that SPEC ViewPerf and many other OpenGL applications often slow down on SMP systems.
OpenGL and dual processors: why they are not friends
Many times in our articles we have drawn the attention of readers to the fact that dual-processor platforms very rarely show any significant advantage over single-processor platforms when performing professional OpenGL tests. And what’s more, there are often cases when installing a second processor, on the contrary, worsens the system’s performance when rendering dynamic three-dimensional scenes.
Naturally, we were not the only ones who noticed this oddity. Some testers simply silently avoided this fact - for example, presenting comparison results from SPEC ViewPerf tests only for dual-processor configurations, thus avoiding explanations of "why is a dual-processor system slower?" Others made all kinds of fantastic assumptions about cache coherence, the need to maintain it, the overhead that arises from this, etc. And for some reason, no one was surprised that, for example, processors were for some reason impatient to monitor coherence specifically in windowed OpenGL rendering (in its “computational” essence, it is not much different from any other computational task).
In fact, the explanation, in our opinion, is much simpler. As you know, an application can run on two processors faster than on one if:
- there are more than two or more simultaneously executing program threads;
- these threads do not interfere with each other's execution - for example, they do not compete for a shared resource such as an external drive or network interface.
Now let’s take a simplified look at what OpenGL rendering looks like when performed by two threads. If an application, “seeing” two processors, creates two OpenGL rendering threads, then for each of them, according to the OpenGL rules, its own gl context is created. Accordingly, each thread renders into its own gl context. But the problem is that for the window into which the image is displayed, only one gl context can be current at any time. Accordingly, the threads in this case simply “one by one” display the generated image in the window, alternately making their context the current one. Needless to say, this kind of “context interleaving” can be very expensive in terms of overhead?
Also, as an example, we will show graphs of the use of two CPUs in several applications displaying OpenGL scenes. All measurements were carried out on the platform with the following configuration:
- one or two Intel Xeon 2.2 GHz (Hyper-Threading disabled);
- 512 MB RDRAM memory;
- Supermicro P4DC6+ motherboard;
- ASUS V8200 Deluxe video card (NVidia GeForce3, 64 MB DDR SDRAM, Detonator 21.85 drivers);
- Windows 2000 Professional SP2;
- video mode 1280x1024x32 bpp, 85 Hz, Vsync disabled.
Blue and red show the load graphs of CPU 0 and CPU 1, respectively. The line in the middle is the final CPU Usage graph. The three graphs correspond to two scenes from 3D Studio MAX 4.26 and part of the SPEC ViewPerf test (AWadvs-04).
CPU Usage: animation 3D Studio MAX 4.26 - Anibal (with manipulators).max
CPU Usage: Animation 3D Studio MAX 4.26 - Rabbit.max
CPU Usage: SPEC ViewPerf 6.1.2 - AWadvs-04The same picture is repeated in a lot of other applications that use OpenGL. The two processors do not bother at all, and the overall CPU Usage is at the level of 50-60%. At the same time, for a single-processor system in all these cases, CPU Usage confidently remains at 100%.
Therefore, it is not surprising that many OpenGL applications do not accelerate very much on dual systems. Well, the fact that they sometimes even slow down has, in our opinion, a completely logical explanation.



We can state that with two logical CPUs the drop in performance is even more significant, which is understandable: two logical processors interfere with each other in the same way as two physical ones. But their overall performance, naturally, turns out to be lower, so when Hyper-Threading is enabled, it decreases even more than simply when two physical CPUs are running. The result is predictable and the conclusion is simple: Hyper-Threading, like “real” SMP, is contraindicated for OpenGL.

CAD applications. The previous conclusion is confirmed by the results of two CAD tests - SPECapc for SolidEdge V10 and SPECapc for SolidWorks. The graphics performance of these Hyper-Threading tests is similar (although the SMP system for SolidEdge V10 scores slightly higher). But the results of the processor-loading CPU_Score tests make you think: 5-10% increase from SMP and 14-19% slowdown from Hyper-Threading.


But at the end of the day, Intel honestly admits that Hyper-Threading can cause performance degradation in some cases - for example, when using empty wait loops. We can only assume that this is the reason (a detailed study of the SolidEdge and SolidWorks code is beyond the scope of this article). After all, everyone knows the conservatism of CAD application developers, who prefer proven reliability and are not in a particular hurry to rewrite code taking into account new trends in programming.
Summing up, or "Attention, the right question"
Hyper-Threading works, there is no doubt about it. Of course, the technology is not universal: there are applications that suffer from Hyper-Threading, and if this technology becomes widespread, it will be desirable to modify them. But didn't the same thing happen back in the day with MMX and SSE and continue to happen with SSE2?..
However, this raises the question of the applicability of this technology to our realities. We will immediately discard the option of a single-processor system on Xeon with Hyper-Threading (or allow it only as a temporary one, pending the purchase of a second processor): even a 30% increase in performance does not justify the price in any way - then it is better to buy a regular Pentium 4. The number of CPUs remaining is from two and above.
Now let's imagine that we are buying a dual-processor Xeon system (say, with Windows 2000/XP Professional). Two CPUs are installed, Hyper-Threading is enabled, the BIOS finds as many as four logical processors, now we’re about to take off... Stop. But how many processors will our operating system see? That's right, two. Only two, since it is simply not designed for more. These will be two physical processors, i.e. everything will work exactly the same as with Hyper-Threading disabled - not slower (two “additional” logical CPUs will simply stop), but not faster either (tested by additional tests, the results are not We present them because they are completely obvious). Hmmm, not much pleasant...
What remains? Well, shouldn’t we really install Advanced Server or .NET Server on our workstation? No, the system will install, recognize all four logical processors and will function. But the server OS looks a little strange on a workstation, to put it mildly (not to mention the financial aspects). The only reasonable case is when our dual-processor Xeon system will act as a server (at least some assemblers have, without hesitation, already started producing servers on workstation Xeon processors). But for dual workstations with the corresponding OS, the applicability of Hyper-Threading remains in question. Intel is now actively advocating for OS licensing based on the number of physical CPUs, rather than logical ones. Discussions are still ongoing, and, in general, a lot depends on whether we will see a workstation OS with support for four processors.
Well, with servers everything turns out quite simply. For example, Windows 2000 Advanced Server installed on a dual-processor Xeon system with Hyper-Threading enabled will “see” four logical processors and will run smoothly on it. To evaluate what Hyper-Threading can do in server systems, we present results from Intel Microprocessor Software Labs for dual-processor Xeon MP systems and several Microsoft server applications.

A performance increase of 20-30% for a two-processor server “for free” is more than tempting (especially compared to buying a “real” 4-processor system).
So it turns out that at the moment the practical applicability of Hyper-Threading is only possible in servers. The issue with workstations depends on the decision regarding OS licensing. Although another application of Hyper-Threading is quite possible - if desktop processors also receive support for this technology. For example (let’s imagine), what’s bad about a system with a Pentium 4 with Hyper-Threading support, on which Windows 2000/XP Professional with SMP support is installed?.. However, there is nothing incredible about this: enthusiastic Intel developers promise the widespread implementation of Hyper-Threading - from servers to desktop and mobile systems.
January 20, 2015 at 07:43 pmOnce again about Hyper-Threading
- IT systems testing,
- Programming
There was a time when it was necessary to evaluate memory performance in the context of Hyper-threading technology. We have come to the conclusion that its influence is not always positive. When a quantum of free time appeared, there was a desire to continue research and consider the ongoing processes with an accuracy of machine clock cycles and bits, using software of our own design.
Platform under study
The object of the experiments is an ASUS N750JK laptop with an Intel Core i7-4700HQ processor. Clock frequency 2.4GHz, increased in Intel Turbo Boost mode up to 3.4GHz. Installed 16 gigabytes of DDR3-1600 RAM (PC3-12800), operating in dual-channel mode. Operating system – Microsoft Windows 8.1 64 bit.Fig.1 Configuration of the platform under study.
The processor of the platform under study contains 4 cores, which, when Hyper-Threading technology is enabled, provides hardware support for 8 threads or logical processors. The platform firmware transmits this information to the operating system via the ACPI table MADT (Multiple APIC Description Table). Since the platform contains only one RAM controller, there is no SRAT (System Resource Affinity Table) table, which declares the proximity of processor cores to memory controllers. Obviously, the laptop under study is not a NUMA platform, but the operating system, for the purpose of unification, considers it as a NUMA system with one domain, as indicated by the line NUMA Nodes = 1. A fact that is fundamental for our experiments is that the first-level data cache has size 32 kilobytes for each of the four cores. Two logical processors sharing one core share the L1 and L2 caches.
Operation under study
We will study the dependence of the reading speed of a data block on its size. To do this, we will choose the most productive method, namely reading 256-bit operands using the AVX instruction VMOVAPD. In the graphs, the X axis shows the block size, and the Y axis shows the reading speed. Around point X, which corresponds to the size of the L1 cache, we expect to see an inflection point, since performance should drop after the processed block leaves the cache limits. In our test, in the case of multi-threaded processing, each of the 16 initiated threads works with a separate address range. To control Hyper-Threading technology within the application, each thread uses the SetThreadAffinityMask API function, which sets a mask in which one bit corresponds to each logical processor. A single bit value allows the specified processor to be used by a given thread, a zero value prohibits it. For 8 logical processors of the platform under study, mask 11111111b allows the use of all processors (Hyper-Threading is enabled), mask 01010101b allows the use of one logical processor in each core (Hyper-Threading is disabled).The following abbreviations are used in the graphs:
MBPS (Megabytes per Second) – block reading speed in megabytes per second;
CPI (Clocks per Instruction) – number of clock cycles per instruction;
TSC (Time Stamp Counter) – CPU cycle counter.
Note: The TSC register clock speed may not match the processor clock speed when running in Turbo Boost mode. This must be taken into account when interpreting the results.
On the right side of the graphs, a hexadecimal dump of the instructions that make up the loop body of the target operation executed in each of the program threads, or the first 128 bytes of this code, is visualized.
Experience No. 1. One thread

Fig.2 Single thread reading
The maximum speed is 213563 megabytes per second. The inflection point occurs at a block size of about 32 kilobytes.
Experience No. 2. 16 threads on 4 processors, Hyper-Threading disabled

Fig.3 Reading in sixteen threads. The number of logical processors used is four
Hyper-Threading is disabled. The maximum speed is 797598 megabytes per second. The inflection point occurs at a block size of about 32 kilobytes. As expected, compared to reading with one thread, the speed increased by approximately 4 times, based on the number of working cores.
Experience No. 3. 16 threads on 8 processors, Hyper-Threading enabled

Fig.4 Reading in sixteen threads. The number of logical processors used is eight
Hyper-Threading is enabled. The maximum speed is 800,722 megabytes per second; as a result of enabling Hyper-Threading, it almost did not increase. The big minus is that the inflection point occurs at a block size of about 16 kilobytes. Enabling Hyper-Threading slightly increased the maximum speed, but the speed drop now occurs at half the block size - about 16 kilobytes, so the average speed has dropped significantly. This is not surprising, each core has its own L1 cache, while the logical processors of the same core share it.
 The connection to the game search servers is unstable: we are solving the problem!
The connection to the game search servers is unstable: we are solving the problem! How to check keyboard keys for functionality on a laptop or computer
How to check keyboard keys for functionality on a laptop or computer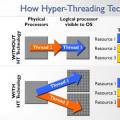 Once again about Hyper Threading
Once again about Hyper Threading