Optimal configuration of server 1C 8.3. Output the working server from the cluster
1C server cluster: enterprises 8 (1C: ENTERPRISE 8 Server Cluster)
1C Server Cluster: Enterprises 8 is the main component of the platform that provides interaction between the database management system and the user in case of client-server work. The cluster makes it possible to organize uninterrupted, sustainable failures, competitive work for a significant number of users with voluminous information bases.
1C Server Cluster: Enterprises 8 is a logical concept that denotes a set of processes that serve the same set of information bases.
You can select the following server cluster capabilities as the main:
- the ability to operate both on several and on one computer (working servers);
- each working server can support the functioning of both one and several workflows that serve client connections within the boundaries of this cluster;
- the inclusion of new customers in the cluster work processes occurs based on the long-term analysis of workflow workflow statistics;
- the interaction of all cluster processes among themselves, with client applications and databases server, is carried out using TCP / IP protocol;
- cluster processes are running, can be both service and as an application.
Client-server option. Scheme of work
In this case, the client application interacts with the server. The server cluster, in turn, interacts with the database server.
The role of the center server cluster plays one of the computers, which are part of the server cluster. In addition, the central server serves client compounds, it still manages the work, in general, the entire cluster and keeps the register of this cluster.
The cluster is addressed to the client connection by the name of the central server and, possibly, the network port number. If the network port is standard, it is enough for the connection to simply specify the name of the central server.
During the connection to the connection to the central cluster server, the client application is drawn. Based on the analysis of workflow workflow statistics, the central server forwards the client application to the necessary workflow that must serve it. This process It can be activated on any cluster operating server, in particular on the central server.
Connection service and user authentication are supported by this workflow until the client's termination with a specific information base.
Cluster servers
An elementary cluster of servers can be a single computer and contain only one workflow.
In the figure you can observe all elements that, one way or another, take part in the server cluster. These are the following items:
- server cluster processes:
o ragent.exe;
o rmngr.exe;
o rphost.exe; - data warehouse:
o list of clusters;
o Cluster Registry.
The ragent.exe process, called the server agent, ensures the functioning of the computer as an integral part of the cluster. Consequently, the computer on which the Ragent.exe process is running, should be called a working server. In particular, one of the functional responsibilities of RAGENT.EXE is the maintenance of the registry of clusters that are on a specific operating server.
Neither the register of clusters nor the server agent is an integral part of the server cluster, but only make it possible to function the server and clusters located on it.
The server cluster itself consists of such elements:
- one or more RMNGR.EXE processes
- register cluster
- one or more rphost.exe processes.
Cluster Manager (RMNGr.exe process). It serves to manage the functioning of the entire cluster. The cluster may include several RMNGr.exe processes, one of which will always be the main manager of this cluster, and the remaining processes are additional managers. The central cluster server should be called a working server on which the master cluster manager is valid, and which contains a cluster list. It is the maintenance of a cluster registry is one of the functions of the main cluster manager.
Workflow (RPHOST.EXE process). It is he, directly, serves client applications, interacting with the database server. In this process, some server module configuration procedures can be executed.
Scalability 1C version 8.3
The scalability of the server cluster is carried out in the following ways:
- increase the number of managers in the cluster and the distribution of services between them
- increase the number of workflows that function on this operating server.
- increase the number of working servers from which the cluster consists.
Use at the same time multiple managers.
The functions that execute the cluster manager are divided into several services. These services can be assigned to different cluster managers. This makes it possible to evenly distribute the load on several processes.
However, some services can only be used by the chief cluster manager:
- cluster configuration service
- debug Control Service
- cluster lock service.
For other services, arbitrary cluster managers are permissions:
- services of registration logs
- service lock service
- task service
- service full-text search
- session data service
- numbering service
- custom settings service
- sERVICE OF TIME
- services of transactional locks.
Use simultaneously multiple workflows.
On the one hand, the use of several workflows makes it possible to lower the load of each specific workflow. On the other hand, the application of several workflows leads to a more efficient use of working server hardware resources. Moreover, the procedure for starting multiple workflows improves server reliability, as isolates customer groups that work with different information bases. The workflow in the cluster in which we assume the launch of several workflows can be restarted automatically, within the time interval specified by the cluster administrator.
The ability to use more workflows (increasing the number of client connections) without increasing the load on a specific workflow, gives a change, to the most side, the number of working servers that are included in the cluster.
Failure tolerance 1C version 8.3
Resistance to failures in the work of the cluster is provided by three directions:
- reservation of the cluster itself
- reservation of workflows
- resistant to the break channel break.
Reservation of cluster 1c version 8.3
Several clusters are combined into the reservation group. Clusters that are in such a group are automatically synchronized.
In case of failure of the active cluster, it replaces the following working cluster of the group. After an inoperable cluster is restored, it will become active after data synchronization.
Reservation of workflows 1C version 8.3
For each of the workflows, it is possible to specify options for use:
- use
- do not use
- use as a backup.
In the event of an emergency completion of the work of any process, the cluster begins to use inactive backup process at the moment. In this case, the automatic redistribution of the existing load on it occurs.
Sustainability 1C version 8.3 to Communication Channel Cliff
Since each user is provided with its own communication session, the cluster retains data on the connected users and what actions were performed.
With the disappearance of the physical connection, the cluster will be in a state of waiting for a connection to this user. In most cases, after the connection is restored by the user will be able to continue working from the place, the moment on which the communication break occurred. Repeated connection The information database will not need.
Sessions of 1C version 8.3
A session makes it possible to define an active user of a specific information base and determine the control flow from this client. Distinguish the following sessions:
- Slim client, web client, Thick client - These sessions arise when contacting the appropriate customers to the information base
- Connection of the "Configurator" type - it occurs when contacting the information base of the configurator
- Som connection - is formed when used external compound To appeal to the information base
- WS connection - occurs in the case of contacting the information database of the web server, as a result of contacting the Web service published on the web server
- The background task is formed when the cluster workflow refers to the information base. Serves such a session to execute the code of the background task procedure,
Cluster Console - It is created when the client-server application administration utility appeals to the workflow - Som administrator - occurs in the case of accessing the workflow using an external connection.
- Work when using various operating systems
Any server cluster processes can function as under operating system Linux and under the operating room windows systems. This is achieved by the fact that the interaction of clusters occurs running the TCP / IP protocol. Also, the cluster can include working servers running any of these operating systems.
Server Cluster Administration Utility 8.3
Included System Supplies there is a utility to administer the option of client-server work. This utility makes it possible to change the composition of the cluster, management of information bases, and promptly analyze transactional locks.
Often by car along with the server 1C: the company employs other services - terminal server, SQL server, etc. And at some point, Server 1C: Enterprise, and more precisely, the RPHOST workflow is eaten more than planned or all the memory. What leads to a slowdown in the work of other services and server zombies. To avoid such situations, you need to configure the automatic restart of the 1C server workflows: Enterprises
Decision
1. Open the 1C Enterprise Server Administration Console;
2. We deploy the center of the central server to clusters and select the cluster of interest to the NC. In the example, the cluster is only one;
3. Open the properties of the selected cluster and see the following form.
1C Server Cluster Properties: Enterprise 8.3
We will analyze the example specified in the image:
Interval restart - The time through which the RPHOST process will be forcibly restarted. Before completing the process, a new RPHOST process starts, to which all connections are transmitted, and only the work of the old process will be completed. At the work of the user it will not affect. The interval is indicated in seconds, in the example, 24 hours are indicated.
Permissible memory - the amount of memory, within which the workflow can work without problematic. The volume is indicated in kilobytes, in the example the value of 20 gigabytes is indicated (in fact, the figure is too big and it is necessary to repel from a particular system, but the average digit 4 GB). As soon as the memory occupied by the workflow exceeds the specified value, it begins the countdown.
Exceeding interval permissible memory - After the timer running after exceeding the permissible amount of memory counts the specified time, a new workflow will be launched to which all connections are transmitted, the old process is marked as shut down. The interval is indicated in seconds, the example indicates 30 seconds.
Off processes stop through - The time through which the workflow will be stopped, marked as turned off, if the value is 0, the process will not be completed. The interval is indicated in seconds, in the example, 60 seconds are indicated.
After applying the settings, you can not restart the server service, they apply dynamically.
TOTAL
So we configured the automatic restart of the 1C server's workflows: enterprises and get a more stable system if the memory leak occurs, the specific session will be terminated.
Also in some situations you can play the settings, and prevent a possible drop in the server when you assign errors.
Please note that the cluster settings are responsible for setting up all servers belonging to the custom cluster. The cluster implies the work of several physical or virtual servers operating with the same information bases.
Interval restart - responsible for the restart of the cluster workflows. This parameter must be set at the server around the clock. Restarting frequency is recommended to communicate with the technological cycle of the cluster information bases. This is usually every 24 hours (86400 seconds). As you know, 1C servers are processed and stored working data.
The automatic restart was developed in the platform "to minimize the negative consequences of fragmentation and memory leakage in the workflows". At ITS there are even information on how to organize a restart of workflows on other parameters (memory, occupied resources, etc.).
Permissible memory - Protects 1C servers from memory recalculation. When the process of this volume is exceeded in exceeding interval permissible volumeThe process is restarted. Can calculate how maximum size Memory occupied by RPHOST processes during servers peak periods. It is also worth installing a small excess interval of permissible volume.
Permissible deviation of server errors. The platform calculates the average number of server errors with respect to the number of appeals to the server for 5 minutes. If this ratio exceeds the allowable, the workflow is considered "problem", and can be completed by the system if the flag is installed "Forced completing problem processes."
Disabled processes stop through. If the allowable amount of memory is exceeded, the workflow is not completed immediately, and becomes "turned off" so that it is time to "transfer" the working data without losing a new running workflow. If this parameter is specified, then the "off" process will be completed in any case after this time expires. If the workflows are "hung" workflows in the server 1c server, then this parameter can be 2-5 minutes.
These settings are installed for each server 1C individually.
Maximum amount of workflow memory - This is volume cumulative Memory, which can occupy workflows (rphost) on the current cluster. If the parameter is set to "0", then takes 80% of server memory. "-1" - without restrictions. When the DBMS and Server 1C are operating on one server, they need to share RAM. If during the operation it will be found that the DBMS server does not have enough memory, then you can limit the memory allocated to the 1C server using this parameter. If the DBMS and 1C are divided according to servers, it makes sense to calculate this parameter by the formula:
"Max volume" \u003d "Total RAM" - " RAM OS ";
"OS RAM" is calculated on the principle of 1 GB for every 16 GB of server memory
Secure memory consumption for one call. In general, individual calls should not occupy all RAM allocated to the workflow. If the parameter is set to "0", the amount of safe flow will be equal to 5% of " Maximum workflow memory ". "-1" - without limitation, which is extremely not recommended. In most cases, this parameter is better to leave "0".
Using parameters "Number of IB per process" and "The number of compounds to the process" You can control the distribution of the 1C server workflow. For example, to run a separate "rphost" to each information base, only users of one base disabled in the case of "drops" of the process. These parameters should be selected individually for each server configuration.
Restriction on the use of RAM server DBMS - Server DBMS MS SQL has one wonderful feature - he likes to load the bases with which active work is carried out completely. If it is not limited, he will take himself all the rapid memory, which only can.
- If the server 1C: Enterprises installed together with Microsoft SQL. Server, then the upper memory threshold needs to be reduced by a value sufficient for the 1C server.
- If only DBMS works on the server, then for the DBMS by the formula:
"DBM memory" \u003d "Shared RAM" - "RAM RAM";
Shared Memory. - A lot is known about this parameter, but still meets what they forget about it. Test to "1" if the server 1c and DBMS work on a single physical or virtual server. By the way, it works, starting from the platform 8.2.17.
MAX DEGREE OF PARALLELISM - Determines how many processors are used when performing one request. DBMS parallelects data obtaining during execution sophisticated requests For several streams. For 1C it is recommended to install in "1", that is, by one thread.
Evaluation of bd files - We define a step in the MB with which the database file "expands". If the step is small, then with the active database growth, frequent extensions will result in additional load on the disk system. It is better to set 500 - 1000 MB.
Reindexation and defragmentation of indexes - It is recommended to do defragmentation / reindexing at least once a week. Reindexing blocks tables, so it is better to run no time or periods of minimum load. It makes no sense to make defragmentation after rebuilding the index (reindexation). On the recommendation of Microsoft, defragmentation is done if the index fragmentation does not exceed 30%. If above, it is recommended to make a reindexation.
Power Plan - In the power supply settings of the operating system, set on high performance.
First of all, after installing the 1c cluster, I had previously needed to create workflows. As it turned out, the cluster processes began to be created automatically depending on the database load.
Trial launch of the background tasks of the main base caused the 1C cluster to infinitely overload rphost.exe and the additional rphost.exe did not want to be created. Running in the settings everything became clear.
Maximum amount of workflow memory - This is the amount of memory that can use workflows together. You need to be very careful when installing the parameter, is measured in bytes. If you set an incorrect value (insufficient to normal users), users will be issued to users "not enough free memory On the 1C server. You can also get this error when the memory quota has ended on the 1C server.
Secure memory consumption for one call - Allows you to control the memory consumption during server call, is measured in bytes. If the call uses more memory than it is necessary, this call will be completed within the 1C cluster without restarting the workflow (rphost.exe). Accordingly, the "loser" that executed the server call will lose the 1c base session without affecting the operation of other users.
in one GB - 1073741824 bytes, therefore in 2 GB - 2147483648 byte
The amount of memory of the workflows to which the server is considered to be productive - when the server is exceeded, the server in the 1c cluster will cease to take new connections.
Number of IB per process- Allows you to isolate information bases for workflows. By default, the current cluster 1C was set to " 8 ", But for several hours of operation, the server itself is very unstable, users have freezed. After wasolation of each information base (value - "1") problems are disappeared.
Number of compounds on the process - default value " 128 ". Since the current base is very huge pressure Background tasks (Logistics calculation, account analysis, competitors analysis, etc.) decided to reduce the number to "25".
A little changed settings and cluster 1C:

Level of fault tolerance- This is the number of working servers that can simultaneously fail, and this will not lead to an emergency completion of users. Backup services are automatically launched in the amount required to provide a given fault tolerance. In real time, the active service to the backup is replicated.
Load distribution mode - There are two options for the parameter: "Productivity Priority" - the server's memory is spent more and the performance above, "memory priority" - 1C cluster saves server memory.
Server 8.3 is characterized by recycled internal code, although the "outside" may seem that this is the burdens, refined 8.2.
The server has become more "auto custom", part of the parameters of the type of workflows is no longer created manually, but is calculated based on the descriptions of the requirements of fault tolerance and reliability tasks.
This reduces the likelihood incorrect setting Servers and lowers the requirements for the qualifications of admins.
Received a load balancing mechanism that can be used either to increase the performance of the system as a whole, or use the new "memory savings" mode, which allows "with limited memory" in cases where the configuration used "likes to dismiss memory".
The stability of work when using large amounts of memory is determined by the new parameters of the operating server.
The "Safe Memory Consumption per challenge" option is especially interesting. For those who are poorly present what it is - it is better not to train on a "productive" base. The parameter "Maximum amount of workflow memory" allows you when "overflow" does not dangle the entire workflow, but only one session "with a loser". "The amount of workflow memory, to which the server is considered to be productive" allows you to block new connections as soon as this memory threshold is overcome.
I recommend to isolate working processes by information basesFor example, specify the parameter "Number of IB per process \u003d 1". With several high-loaded bases, this will reduce the mutual influence of both reliability and performance.
A separate contribution to the system stability makes "spending" licenses / keys. In 8.3, it was possible to use the "Program License Manager" reminding the Aladin manager. The goal is the ability to bring the key to a separate machine.
It is implemented in the form of another "service" in the cluster manager. You can use for example "free" laptop. Add it to 1C 8.3 cluster, create a separate manager with the licensing service on it. In a laptop, you can stick hardware HASP key, or activate software licenses.
The greatest interest for programmers must submit "Requirements for functionality".
Requirements of the designated functionality 1C
So on a laptop with a protection key to not run users to the cluster server, you need to add "Requirements" for the object "Client Union with IB" requirement - "Not to assign", i.e. Prohibit the working processes of this server to handle client connections.
An even greater interest is given the ability to run "Only background tasks" on the working cluster server without user sessions. Thus, you can take high-load tasks (code) to make a separate machine. What can one background setting of the "closing of the month" can be started through the "value of an additional parameter" on one computer, and the "Updating of the full-text index" background task on the other. It occurs through the "Additional parameter value" indication. For example, if you specify the backgroundjob.comMonModule as a value, you can limit the operation of the working server in the cluster only by background tasks with any content. The value backgroundjob.commonmodule.<Имя модуля>.<Имя метода> - Specifies a specific code.
|
1C rental: ERP Cloud solution |
Delivery Management For shopping and courier companies! |
1C: Edo Learn about all the advantages of electronic document management! |
Termination of support |
1C Server Rental |



1C server cluster - building high-loaded systems
Order Demonstration OrderThis article will examine several variants of the 1C structure for high-loaded systems (from 200 active users), built on the basis of client-server architecture - their advantages and disadvantages, the cost of installation and comparative performance tests of each option.
We will not contain a description, assessment and comparison of the generally accepted and long-known classic schemes for constructing a 1c server structure, such as a separate 1C server and a separate DBMS server, or a Microsoft SQL cluster with a 1c cluster. Such reviews are a great set, including those conducted by the manufacturers by the manufacturers of software products. We will offer an overview of the design schemes for the structure of 1C, which have met over the past few years in our IT projects for medium and large businesses.
Requirements for high-loaded systems 1C
High-loaded 1C systems operating with large data arrays 24/7/365 are subject to risk factors that are usually not observed in standard situations. As a result, their elimination and progress requires the use of special architecture schemes for 1C and new technologies.
Catastrophorestability DBMS. In the process of designing an architecture of 1C, focus on computing power and high availability of services expressed in their clustering. Servers 1C: The default company is capable of working in a duplicate cluster, and the DBMS cluster is usually applied industrial system data storage (storage) and clustering technology (for example, Microsoft SQL Cluster). However, the situation becomes deplorable when problems happen to the SCD itself (often, in our experience of recent years - these are problems of a software nature). Then the IT engineer sharply arise two problems - where to take current data and where to deploy them as soon as possible, since the storage system with the desired amount of fast disk array is not available.
Database security requirements. Working with medium and large business projects, we regularly face the requirements for the protection of personal data (in particular, to fulfill the FZ-152 points). One of the conditions for performing these requirements is to ensure the proper preservation of personal data, which requires the encryption of 1C database.
When developing a scheme of high-loaded 1s systems, 1C usually pay attention to the parameters of the input disk system \\ output on which databases are located. But in addition, there is also an active utilization of CPU resources and consumption by RAM 1C server. Often, it is precisely this type of resource and lacking, the capabilities of the hardware upgradation of the current server 1c are exhausted and the addition of new 1C servers operating with a single DBMS server is required.Schemes for organizing clusters of servers 1C
A diagram with a cluster of 1C servers connected to the cluster with SQL AlwaySon synchronous replication via IP protocol. This scheme is one of the qualitative variants of solving the problem of the catastrophetability of the 1C database (see Figure 1). The SQL Alwayson base clustering technology is based on the principle of online synchronization of SQL tables between the main and backup servers without the interference of the end user. Using SQL Listener, it is possible to switch to the SQL backup server in case of failure of the main one, which allows you to call this system A full-fledged catastropheral cluster of SQL, thanks to the use of two SQL independent servers. SQL ALWAYS ON technology is available only in microsoft version SQL Enterprise.
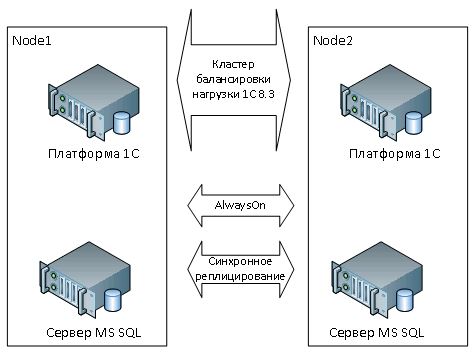
Figure 1 - 1C + SQL AlwaySon server cluster diagram
The second scheme is identical to the first, only the SQL database encryption is added on the main and backup server. We have already mentioned that work with the latest IT projects showed that companies began to pay much more attention to the issue of data security, for various reasons - the requirements of the FZ-152, raider seizures of servers, data leakage in the cloud and the like. So believe this option Schemes 1C are quite relevant (see Figure 2).
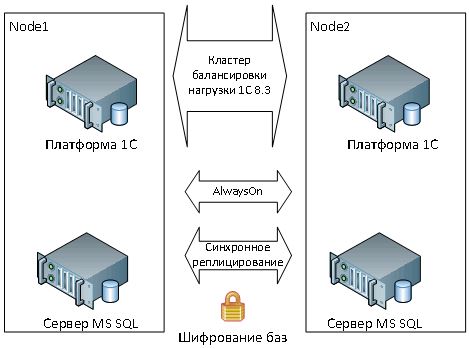
Figure 2 - 1C + SQL AlwaySon cluster cluster diagram with encryption
1C "Active-Active" server cluster, connected to a single SDB server via IP protocol. As opposed to fault tolerance and security needs - some structures are primarily required increased performanceso to speak "all computing power". Therefore, the maximum priority is given to an increase in the number of computing clusters of the 1C server, for which the modern 1c platform allows you to differentiate different types Calculations and background tasks (see Figure 3). Of course, the equipment of the SQL server's basic resources should also be at the level, but the database server itself is presented in a single number (apparently, the calculation goes to timely backup databases).
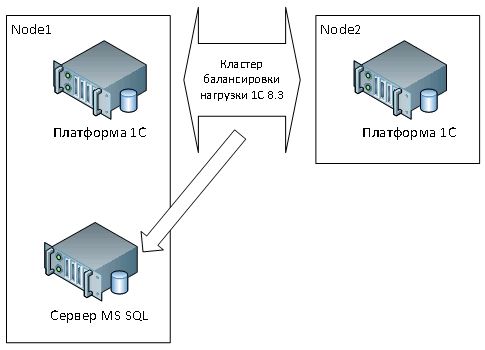
Figure 3 - 1c server cluster diagram with one DBMS server
Server 1C and DBMS on one hardware server with SharedMemory. Since our practical tests are focused on a comparison of performance of different schemes, then a certain standard is required to compare several options (see Figure 4). As a reference, in our opinion, you need to take the 1C server location scheme and the DBMS on one hardware server without virtualization with SharedMemory interaction.

Figure 4 - 1C server diagram and DBMS on one hardware server with SharedMemory
Below is a general comparative table, which shows general results on key criteria for assessing the organization of the 1C system structure (see Table 1).
| Criteria for assessing architectures 1C | 1C + SQL AlwaySon cluster |
1C + SQL AlwaySon cluster with encryption |
1C cluster with one DBMS server |
Classic 1C + DBMS SharedMemory |
| Ease of installation and maintenance | Satisfying | Satisfying | Okay | Excellent |
| fault tolerance | Excellent | Excellent | Satisfying | Not applicable |
| Safety | Satisfying | Excellent | Satisfying | Satisfying |
| Budget | Satisfying | Satisfying | Okay | Excellent |
Table 1 - Comparison of 1C systems
As you can see, one important criterion remains, the value of which is to find out is productivity. To do this, we will conduct a series of practical tests on a highlighted test bench.
Description Testing technique
Test stage consists of two key tools synthetic generation of load and imitation of users of 1C. This is a Gile Test (TPC-1C) and "Test Center" from the 1C Toolkit: Kip.
Test Gilev. The test refers to the section of universal integral cross-platform tests. It can be used both for file and for client-server options 1C: Enterprise. The test estimates the amount of time per unit of time in one stream and is suitable for estimating the speed of single-flow loads, including the recruitment rate of the interface, the impact of resource costs for servicing the virtual environment, rearness of documents, closure of the month, payroll, etc. Versatility allows you to make a generalized performance assessment without tosing to a specific standard platform configuration. The test result is the summary assessment of the measured system 1C, expressed in the conventional units.
Specialized "Test Center" from the 1C Toolkit: Kip. TEST CENTER - Tool of automation of multiplayer load tests of information systems on the 1C platform: Enterprise 8. With it, you can simulate the work of the enterprise without participation real usersthat allows you to evaluate the applicability, performance and scalability information system In real conditions. Using the 1C Toolkit: Kip, on the basis of processes and control examples, the matrix "List of objects of the Base layout objects of the ERP 2.2" is formed for the performance test script. In the 1C database layout: ERP 2.2 are generated by processing data on regulatory information (NSI):
- Several thousand nomenclature positions;
- Several organizations;
- Several thousand counterparties.
The test is carried out in several user groups. The group consists of 4 users, each of which has its own role and a list of consecutive operations. Thanks to the flexible setting mechanism for testing, you can run a test for a different number of users, which will estimate the behavior of the system at various loads and determine the parameters that can lead to a decrease in performance indicators. 3 iterations are held 3 iterations in which the 1C developer launches the test with emulation of users and measure the execution time of each operation. Measurements of all three iterations are performed for each of the 1C structure schemes. The test result is to obtain an average operation time for each matrix document.
The indicators of the "Test of the Center" and the test of Gilev will be reflected in the summary table 2.
Test stand
Server terminal access – virtual machineused to control testing tools:
- vCPU - 16 2.6GHZ cores
- RAM - 32 GB
- I \\ O: Intel SATA SSD RAID1
- RAM - 96 GB
- I \\ O: Intel SATA SSD RAID1
Server 1C and DBMS - physical server
- CPU - Intel Xeon. Processor E5-2670 8C 2.6GHz - 2 pcs
- RAM - 96 GB
- I \\ O: Intel SATA SSD RAID1
- Roles: Server 1C 8.3.8.2137, MS SQL Server 2014 SP 2
conclusions
We can conclude that in terms of the average operation of the operation is the most optimal scheme No. 3 "Cluster of Servers 1C" Active-Active ", connected to a single DBMS server via IP protocol" (see Table 2). To ensure the fault tolerance of such an architecture, we recommend building a classic fault-tolerant MSSQL cluster with the location of the database on a separate storage.
It is important to note that the most optimal ratio of frequency minimization factors, fault tolerance and data security - at schema No. 1 "1c servers cluster connected to a cluster with SQL AlwaySon synchronous replication via IP protocol", while the performance drop in relation to the most productive option is Approximately 10%.
As we see the results of tests, synchronous replication sQL database Alwayson has a negative effect on performance. This is explained by the fact that the SQL system is waiting for the end of replication of each transaction to the backup server, not allowing working with the base at this time. This can be avoided if you configure asynchronous replication between MSSQL servers, but with such settings we will not get automatic switching Applications on the backup number in case of failure. Switching will have to be performed manually.
On the basis of the EFSOL cloud we offer our customers 1c servers cluster For rent. This allows you to significantly save money on building your own fault tolerant architecture to work with 1C.
|
1C architecture scheme |
Average operation time, sec | ||
 State Services Personal Account
State Services Personal Account State Supervisory Cabinet- Entrance on SNILS and Telephone
State Supervisory Cabinet- Entrance on SNILS and Telephone Single telephone rescue service in the Russian Federation
Single telephone rescue service in the Russian Federation